
DynamoDB Data Modeling Series
- What really matters in DynamoDB data modeling?
- Which flavor of DynamoDB secondary index should you pick? (YOU ARE HERE)
- Maximize cost savings and scalability with an optimized DynamoDB secondary index
- Single table design for DynamoDB: The reality
This is the second article in a short series about DynamoDB data modeling (without the “single table design” misconceptions). If you haven’t read the first article, I’d encourage you to check it out. In that one, I discuss the most important concepts in DynamoDB modeling: schema flexibility and item collections. This time, I’ll build upon that foundation to discuss secondary indexes—one of my favorite DynamoDB features. Please note this article assumes some familiarity with core DynamoDB concepts like partitions, items, primary key types and data types. If you need to get up to speed on those, here’s a video playlist I recommend.
Secondary indexes are powerful! You can use them to automatically provide different perspectives for reads of the data in your table. They help you to define and maintain additional relationships (item collections) within the same data, they allow you to sort the related data with a different dimension, and they can be incredibly effective filters.
But like any other tool, it’s possible to use DynamoDB secondary indexes poorly.
With great power comes great responsibility—and great need to understand your options! In this blog, I’ll focus on comparing the different types of secondary indexes and offer some tips for choosing between them. I’ll save talk about secondary index projection choices and the consequences for cost and scalability for the next blog—plus some observations about a recent trend in use of DynamoDB global secondary indexes called “overloading” and why it should be avoided in the majority of designs.
So stay tuned! And hold onto your hats—it’s going to be a whirlwind tour.
Where do secondary indexes live? And how do they get there?
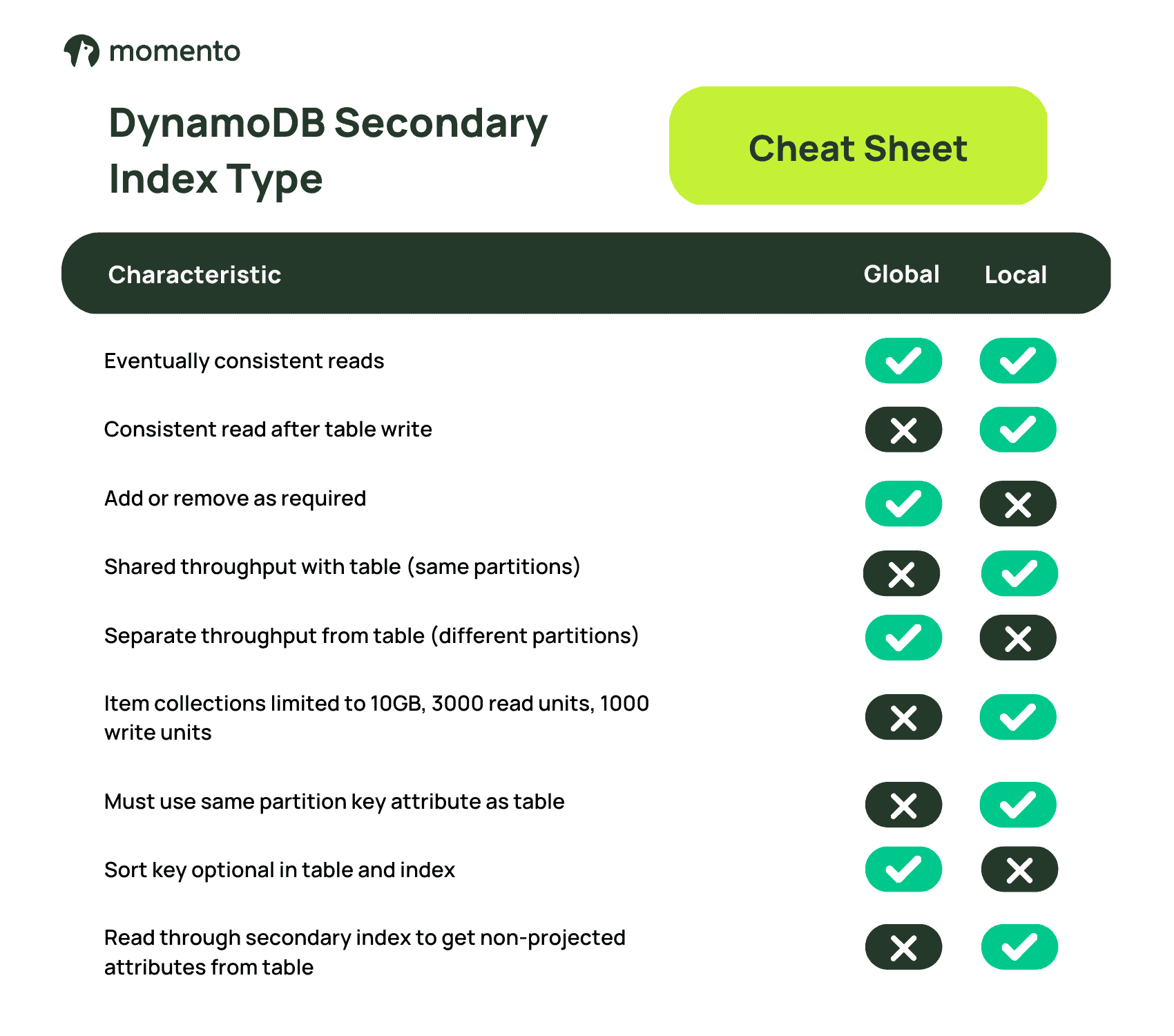
Data from your table (the primary index) is projected into your secondary indexes by the DynamoDB service based on the index definition you provide. You can’t write directly to a secondary index, but when you write to an item in your base table DynamoDB will project relevant changes into your secondary indexes for you. There are two types of secondary index: Local Secondary Indexes (LSIs) and Global Secondary Indexes (GSIs).
Local secondary indexes
LSIs live on the same DynamoDB partitions as the base table—they share the same partition key attribute (but have a different sort key attribute) and they share throughput with the base table. LSIs are local because they offer a different sort order for an item collection within the same partition. LSIs support strongly consistent reads after a write to the base table if specified as a parameter to the request (otherwise the default eventual consistency is used).
In fact, LSIs and base tables share the same item collections—and this constrains each item collection to living on a single partition. When a table has one or more LSIs, each item collection can never grow beyond ~10GB (all data for the same value of the partition key value in the base table and all LSIs combined). The read and write throughput for any given item collection is limited to 3,000 read units per second and 1,000 write units per second within the table and all associated LSIs.
LSIs must be defined when the table is created and cannot be deleted without deleting the associated base table. Think carefully before using LSIs in your data model—you should have a good reason (like a valid requirement for strongly consistent reads), and you must know that you’ll never have an item collection which could grow to require more than 10GB, 3,000 read units per second, or 1,000 write units per second.
If you later decide you don’t want to be constrained by the properties of LSIs or don’t need a particular LSI anymore, it may require a complex migration from your existing table to a replacement table.
Global secondary indexes
GSIs are like a separate table—they can have a different partition key attribute, and they have their own partitions and throughput capability. They can be added (with backfill) as required, and removed (at no cost) when no longer needed. They are global because they allow new relationships (item collections) to be defined across items in all of the base table’s partitions. Item collections in a GSI can span partitions to store more data and deliver greater throughput (also true for the base table as long as there are no LSIs).
One of the biggest differences between LSIs and GSIs is in their behavior during writes to the base table. Because the base table and any LSIs share the same partitions, any updates to the LSIs are handled atomically with the change to the base table item. For GSIs, the change is asynchronously propagated to a different partition. This has read-after-write consistency implications. Reads from an LSI can be requested to be consistent if desired—but a read from a GSI is always eventually consistent.
A further consideration for reads from a GSI is monotonicity. GSI reads are not monotonic. If you update an item in your base table to increment an attribute’s value from 7 to 8, you could make three successive reads of the projected data in your GSI and see the value as 8 first, then 7, and finally back to 8. A series of reads for the same data in a GSI can return results that move both forward and backward over time. Strongly consistent reads from the table or an LSI are monotonic.
GSIs are more flexible than LSIs, and any LSI could easily be modeled as a GSI instead. Only use LSIs if you are sure the index will need to support consistent/monotonic reads, or if you want to benefit from the “read through” capability (details on this in a future blog).
Interesting properties of secondary index keys
First and foremost: the value for the index key is not guaranteed unique like the primary key in your base table. The index can have multiple projected entries which have the same values for the index partition key and sort key! The GetItem API is not supported for secondary indexes because GetItem implies reading a maximum of one item for a particular value of the key. But in a secondary index, even when a specific value of the index key is provided you may see many items returned! You must use Query or Scan to read from an LSI or GSI. LSIs provide alternate sorting, GSIs provide alternate collections and (optional) sorting.
As mentioned before, an LSI must have a composite key. The base table the LSI is attached to must have a composite key also. The LSI’s partition key is required to be the same as the base table, and the sort key attribute must be different from that of the table. A simple example might be a graphical user interface which lists a set of entries in tabular form—the entries are grouped (item collections related by the same value of the partition key attribute), and sorted by one of the column’s values (base table sort key). What if the user should need to sort the same group of entries by a different column? This is where an LSI can help you.
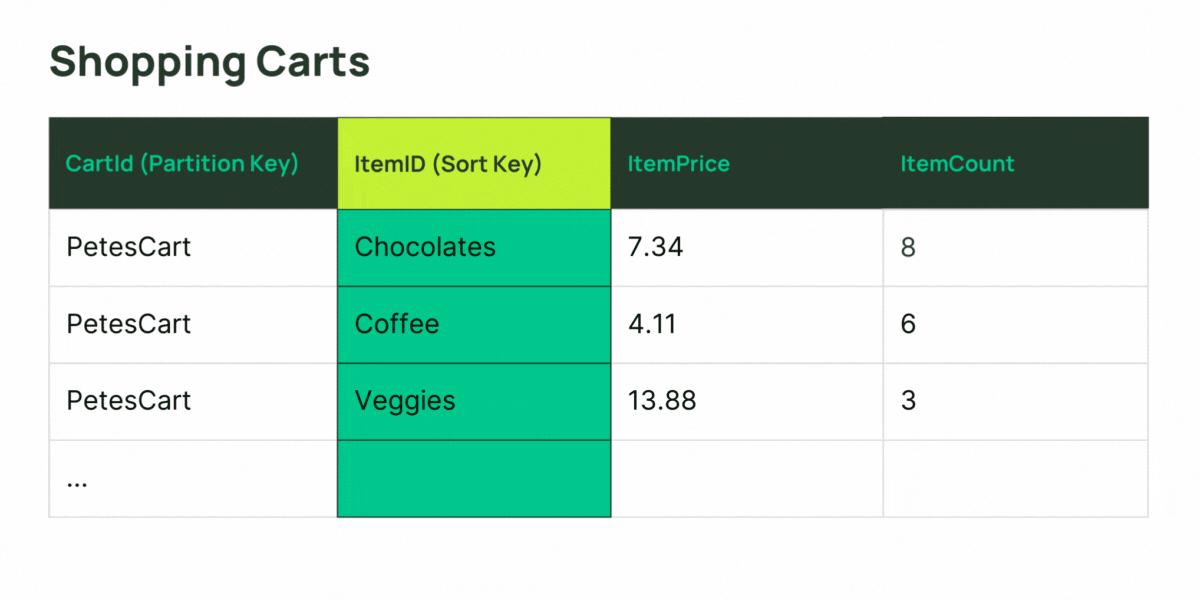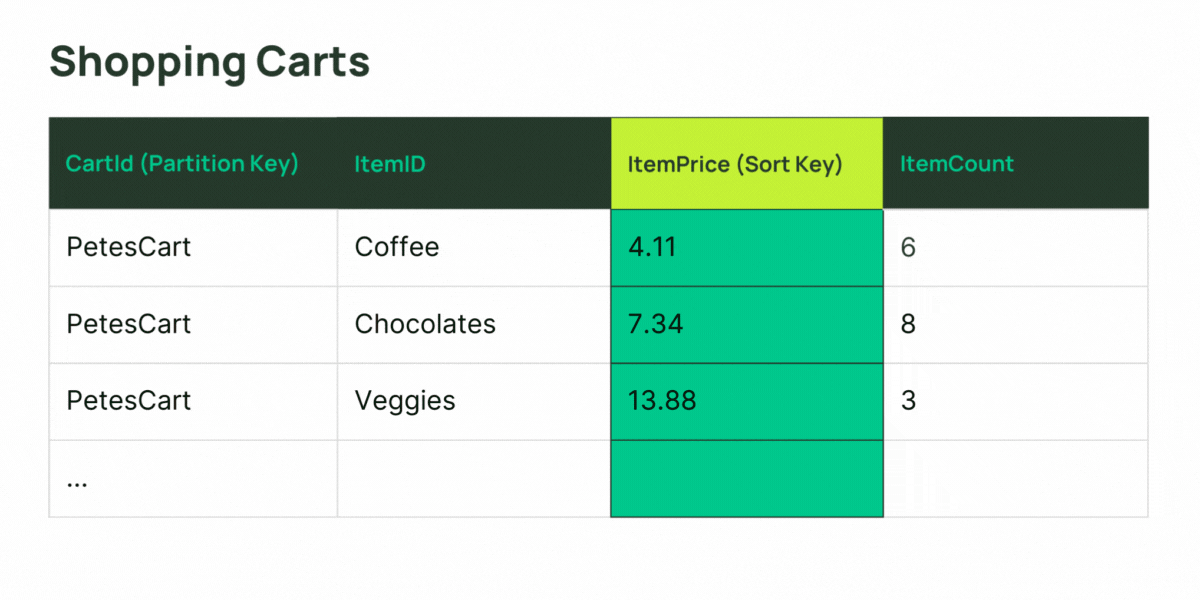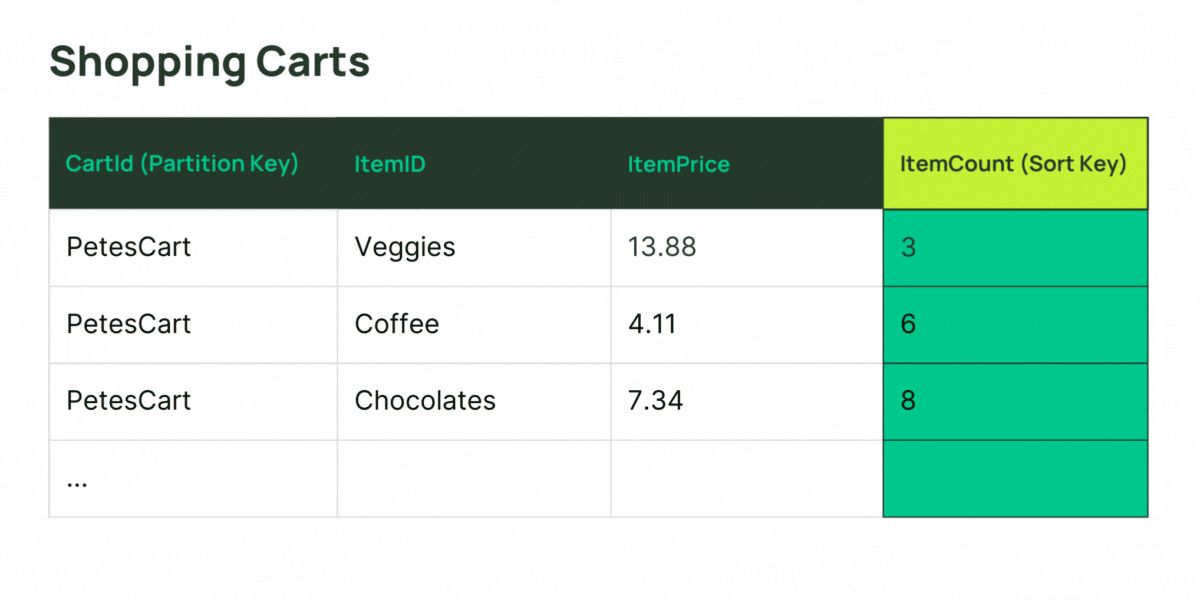
GSIs are more flexible: a partition key is required, but it can be different from the base table—you can relate/group your table’s data on a different attribute! A GSI can have a simple key or a composite key—and the same is true for the base table it is attached to. If you don’t need to retrieve item collections from your GSI in sorted order (perhaps the pattern is just to Query for all the items that have a common value of partition key in the index), don’t define a sort key—the GSI can still build collections of items for efficient retrieval. Defining a sort key when it’s not necessary can limit your scalability for the item collections.
Distilling distinctions between secondary index types
There’s a lot of nuance here, but it really boils down to some simple differences, so I made a cheat sheet you can use next time you’re considering your secondary index options.
Keep your eyes peeled for the next entry in this DynamoDB Data Modeling series (which aims to debunk “single table design”). Coming up in future articles: more on secondary indexing and a summary discussion about where “single table design” went horribly wrong.


