

A team is chasing latency. A database call is just a little too slow, or traffic has grown to the point that read amplification is starting to hurt. Someone proposes adding Valkey. It works immediately. The p99 drops. Everyone moves on.
A few months later, another team runs into the same problem. They don’t want to share a cache, they have different TTLs, memory profiles, and failure tolerance. They spin up their own cluster and it works too. For a long time, nothing is obviously broken.
Then one day, someone asks how many caches exist, who owns them, and what would happen if half of them degraded at once. The answers are fuzzy. Metrics look healthy. Incidents are rare but strangely hard to explain. Failures don’t look like storage failures or network failures. They look like coordination failures.
This is the moment a cache stops being a feature and becomes critical infrastructure.
What Happens When Your Cache Cluster Stops Being Predictable
At small scale, a cache cluster is a local optimization. At large scale, caches begin to shape the system itself by influencing cost curves, failure domains, deployment speed, and how much implicit coordination exists between teams.
At Unlocked, engineers from Uber and Mercado Libre described versions of this transition from the inside. What stood out was the variance of workloads running through the same platform.
Uber operates around one billion operations per second at peak across roughly 2,000 clusters. Each cluster presents a different stress signature, and as Yang Yang, Senior Staff Engineer on Uber’s online data infrastructure team, put it: “Some are CPU-intensive with minimal memory usage, while others have very large memory footprints, and each presents different challenges.” When workloads are that varied, caching stops being about average latency and starts being about latency distribution control — keeping the entire shape of the curve in bounds, not just the median.
Mercado Libre operates under similar pressure with a different profile: thousands of microservices across four primary language stacks — Java, Go, Python, and Node — with infrastructure growing 30–60% year over year. Ignacio Alvarez, Senior Principal Engineer at Mercado Libre, framed their mission plainly: “Our main focus is to let developers focus on what they need to build.” At that rate of growth, the failure mode is accumulated decisions that no single team can see across.
In both environments, the early model (one cluster per team, owned locally) never failed dramatically. It gradually became harder to reason about. Decisions that felt isolated on paper started interacting in production in ways no single team could observe.
Nothing breaks. The system just becomes opaque.
That opacity is the first sign that a platform needs to form. It’s not a crisis or a postmortem, but the slow buildup of questions nobody can answer cleanly.
Why Cache Ownership Becomes the Bottleneck Before Technology Does
Neither organization hit a cache limit. They hit an ownership limit.
Provisioning is self-service, lifecycle is informal, and isolation feels safe. But isolation is deceptive when lifecycle events synchronize. Independent clusters create independent connection pools, independent retry behavior, and independent topology reactions. When infrastructure shifts, like a rebalance, rolling restart, or an availability zone event, those independent reactions often align unintentionally. What was deliberately designed to be isolated becomes correlated.
Uber adapted by centralizing lifecycle operations behind a control plane. Provisioning, scaling, healing, and decommissioning were turned into explicit workflows. “Every operation is workflow-driven,” Shawn Wang, Staff Software Engineer at Uber, explained. “Scaling checks run daily, and self-healing runs about every 30 minutes.” Teams are still able to request caches when they need them, but now the platform absorbs the operational burden of those requests.
Mercado Libre arrived at a similar solution from the opposite direction. Their first iteration — Memcached, one cluster per app, client of your choice — produced idle infrastructure, poor sizing decisions, and no governance over usage. The second iteration, built on Redis and rolled out in 2022, introduced wrapper SDKs, centralized governance, and invisible multi-tenancy through key prefixing. Clusters could now be shared without developers being aware of it, which let the platform team manage fleet-level efficiency and blast radius. As Alvarez described it: “Users didn’t know about it, but we could share the same cluster across different users.”
The shift to higher levels of platform team visibility in both cases was subtle. Individual teams still chose when to cache. The platform chose how caching behaved as part of the end-to-end solution.
How Connection Storms and Bandwidth Limits Expose Cache Architecture Problems
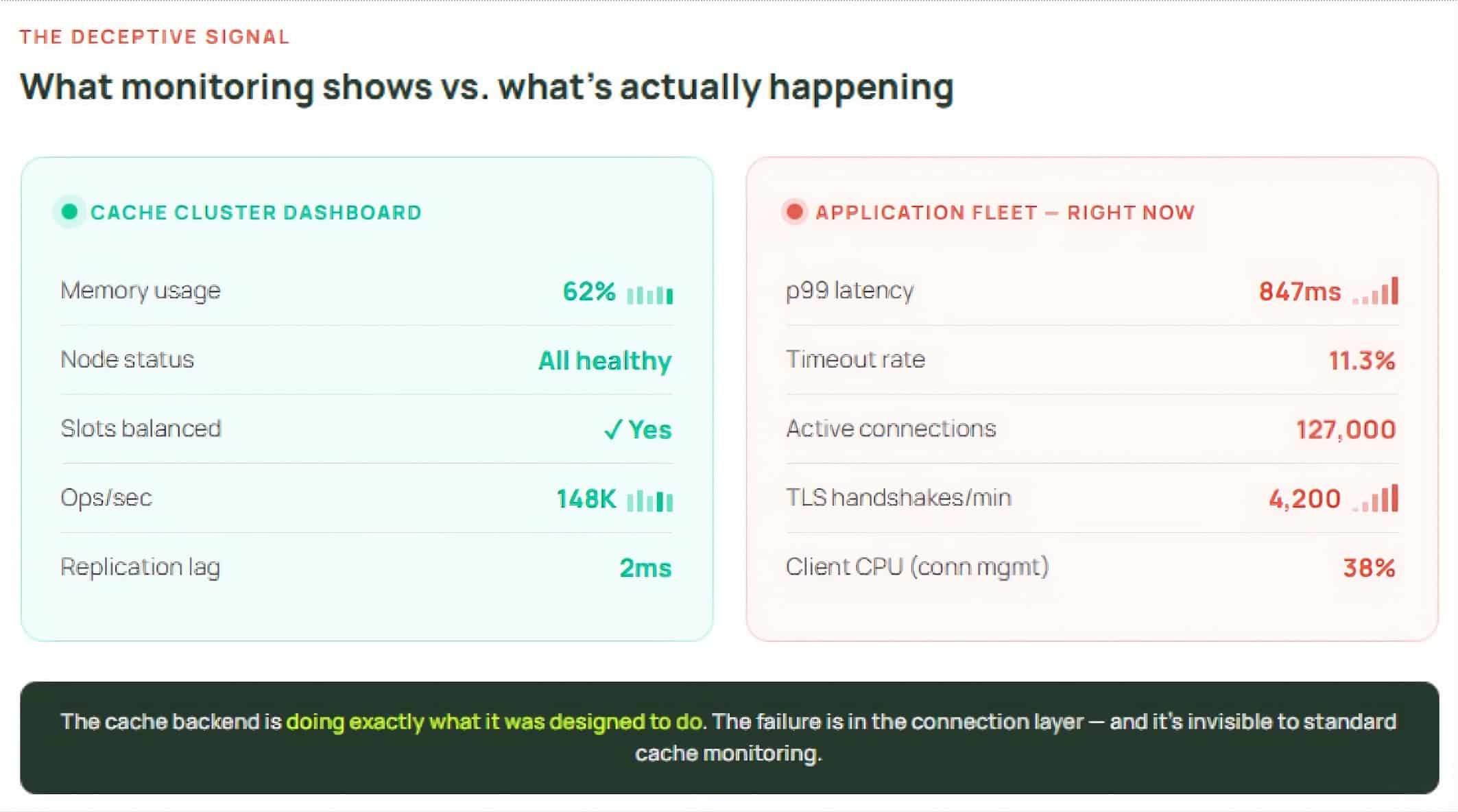
One of the most telling themes across both sessions was how often serious incidents originated in client behavior under stress and that the cache was what amplified the problem.
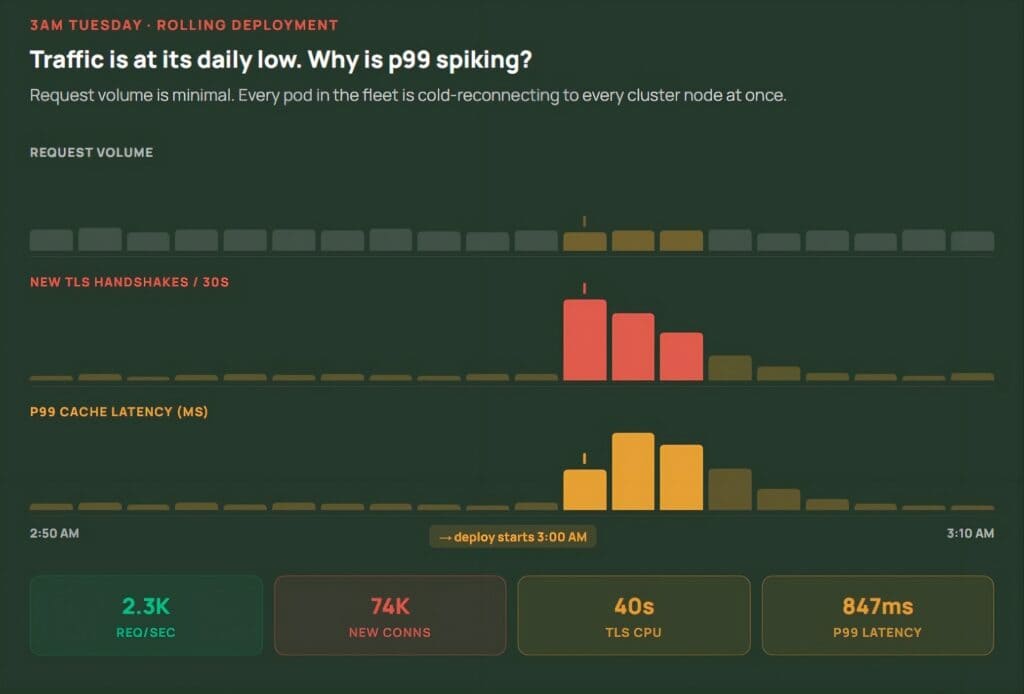
Uber described a specific failure pattern during their migration from T-Redis (an in-house twin-proxy plus standalone Redis architecture) to native Redis clusters. When a node slowed down or became briefly unavailable, the Go Redis client responded by closing the connection and immediately opening a new one. Wang described the dynamic directly: “When this happens across hundreds or thousands of instances simultaneously, retries amplify load instead of relieving it.” Nodes hit 100% CPU and stopped responding, and the system fed back into itself.
The connection math behind this is straightforward and brutal. If n service instances each maintain a connection pool of p connections per cache node, that node doesn’t see n connections — it sees n × p.
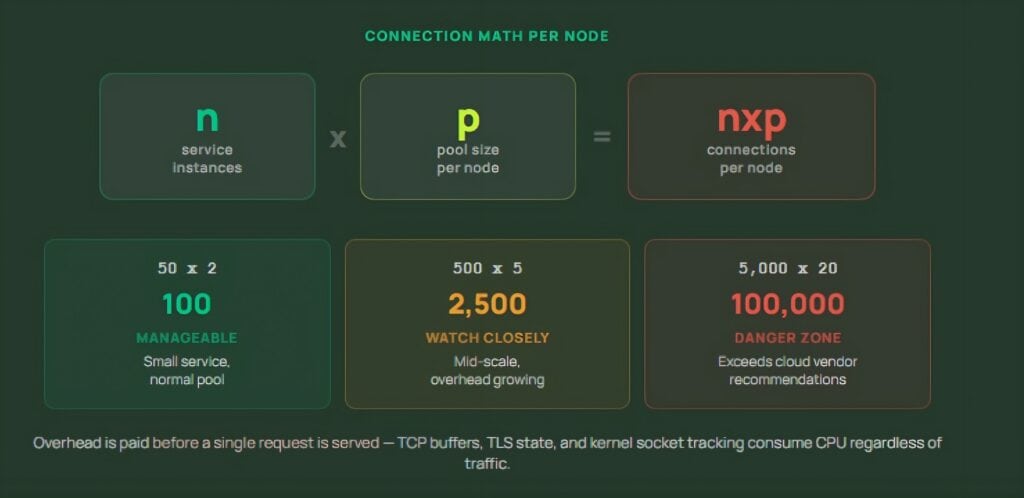
For large services with thousands of instances, this exceeds 100,000 connections per node before a single request is processed. The overhead alone consumes real CPU and memory regardless of whether those connections are active through TCP buffer allocation, TLS state tracking, and kernel socket bookkeeping .
Uber’s mitigations were layered. For immediate incidents, they configured iptables rules to isolate affected nodes and stop retry amplification from cascading. Longer-term: upgrading their client version removed aggressive connection reaping, introduced fair queuing for new requests, and added explicit I/O timeouts independent of application-level configuration. They also added client-side circuit breakers with per-node rate limiters to dampen feedback loops proactively.
The failure mode is especially deceptive during low-traffic windows. Deployments often happen overnight precisely because traffic is minimal — but a rolling restart means every pod in the fleet cold-reconnects to every cluster node at once. The connection storm has nothing to do with request volume.
Mercado Libre hit a structurally different but equally foundational constraint: bandwidth. “When you optimize for efficiency and cost, you have many variables,” Alvarez noted. “In our experience, for our workloads, bandwidth was the key bottleneck and caused the most issues. Nodes dying because of the volume of bytes moving in and out was the hardest problem to solve.” Their dominant bottleneck was bytes per second. So payload size, rather than request count, became the hindrance.
In both environments, the cache was doing exactly what it was designed to do. The degradation emerged from synchronized client reactions, oversized values, and fleet-wide retries. Once that pattern appears, you need more than just backend tuning. The system needs a place where behavior can be shaped in addition to being observed.
How Wrapper SDKs and Routing Layers Become Reliability Infrastructure
Wrapper SDKs and routing layers are often misclassified as developer-experience conveniences. At scale, they are the mechanism a platform enforces correct behavior with rather than hoping teams converge on it themselves.
Uber’s client libraries standardized retry semantics, connection pooling behavior, circuit breakers, batching, and observability across hundreds of microservices. The wrapper made it structurally difficult for individual teams to configure aggressive retry behavior that would have amplified load during partial failures. They standardized on Go-Redis for Go and Lettuce for Java, then built a thin wrapper on top that abstracts cluster discovery, provides built-in metrics, and enables circuit breakers and context propagation. Lettuce’s use of I/O multiplexing was notable enough that the team began exploring equivalent capabilities for Go clients.
Mercado Libre’s SDK abstracted entire backend decisions. Developers simply consumed a capability as opposed to choosing Memcached or Redis. Within that abstraction, the platform team added an opt-in compression codec that shrank payload sizes without requiring application rewrites, directly addressing their bandwidth bottleneck at the platform layer without touching a single line of application code. They also implemented efficiency features for dynamic scaling, compute type selection, and infrastructure switching based on conditions — all invisible to developers.
This abstraction was about making systemic behavior enforceable.The platform can prevent connection storms before they form, absorb hot-key bursts before they concentrate, and standardize timeout behavior before it cascades across the fleet. The internal cache platform becomes the set of control points that govern how clients interact with those clusters.
Why Large-Scale Teams Move to Valkey
Both organizations described movement toward Valkey, and their motivation is telling. Neither were chasing the lowest possible latency. They were optimizing for longevity and operational continuity.
Yang Yang described their evaluation criteria like this: “Our criteria include performance, client capabilities, upgrade complexity, control-plane compatibility, and long-term sustainability. Valkey meets these requirements well. It offers stable latency under stress, strong client compatibility, manageable upgrade paths, compatibility with our control plane, and a growing community that we’re excited to contribute to.” Mercado Libre moved in the same direction after the Redis licensing change, and found that the abstraction layer they’d already built made the transition mostly invisible to application teams. As Alvarez noted simply: “Valkey came up. We love you, Valkey.”
This is one of the structural advantages of accessing Valkey through a managed platform rather than operating it directly. When the datastore sits behind an abstraction layer like your own SDK or a service like Momento, backend migrations become operational decisions rather than application-level rewrites. The platform absorbs the transition; teams keep building. This is exactly how Momento approaches it: we run Valkey, and we run it hard. The routing layer, connection management, hot-key absorption, and multi-tenant isolation are already built in, which means the teams we serve get the performance of a well-tuned Valkey deployment without inheriting the operational surface area that comes with it.
Once caching becomes foundational infrastructure, the decision horizon shifts. Teams stop optimizing for quarterly performance gains and start optimizing for multi-year stability. The datastore becomes part of the system’s durability contract. The interesting signal isn’t the move itself. It’s that platform teams begin thinking in years instead of releases. That shift also changes what visibility means. Now the platform owns the health of the entire cache fleet, not individual app teams.
How to Know If Your Team Is Ready to Build an Internal Cache Platform
The rise of the internal cache platform is rarely a dramatic pivot. It’s a gradual shift in what engineers spend their time worrying about, and recognizing it early is the difference between building deliberately and reacting to cascading failure.
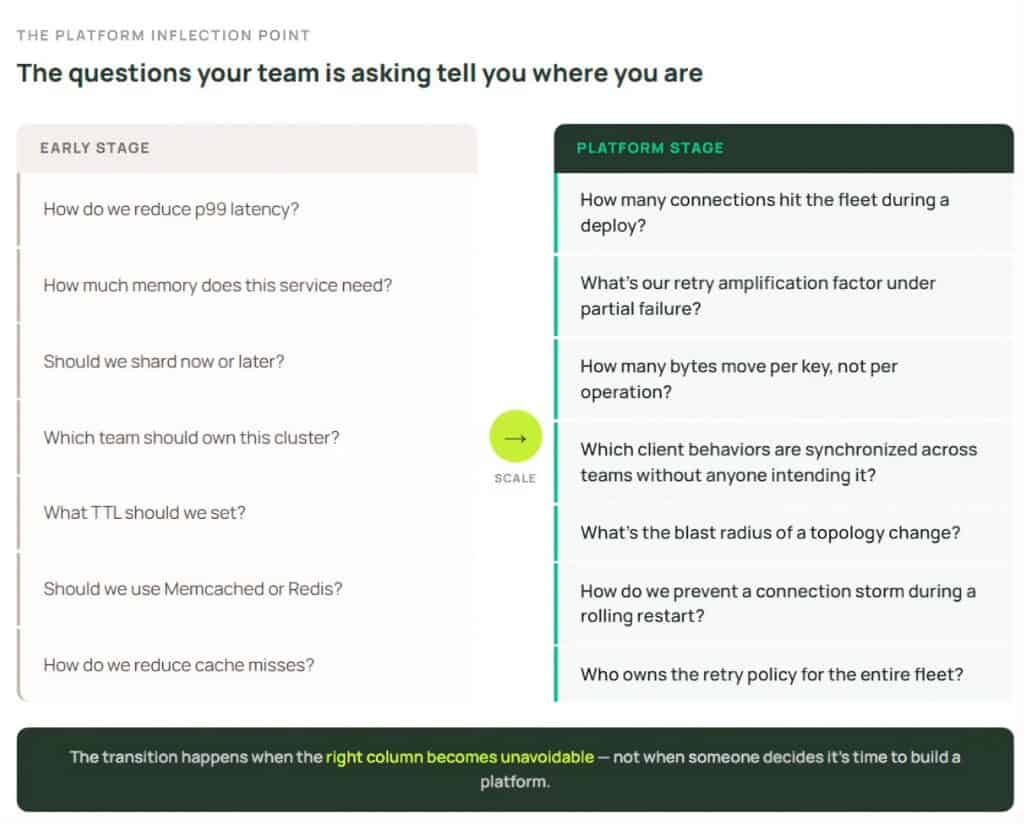
The transition happens when the right column becomes unavoidable. At that point, the cost of continuing to treat caches as independent team-owned resources is greater than the cost of the coordination layer required to govern them centrally. Both Uber and Mercado Libre described this crossover not as a slow accumulation of friction that eventually became inevitable.
What made the Unlocked sessions resonate was that engineers were comparing perf traces, connection math, and payload distributions instead of feature lists. The domains were different, but the arc was the same: caching starts as a performance optimization, becomes a coordination problem, and the internal cache platform is the structure organizations build to solve that coordination problem deliberately instead of accidentally.
The conversations in this post happened at Unlocked — an event for engineers working on performance-critical cache infrastructure. The next Unlocked is in Seattle this May*. If your team is asking the later-stage questions, this is the room where those conversations happen.* Learn more and register →


