
Alright, maybe “dark art” is a step too far, but multi-tenancy is certainly hard to get right. While it is tempting to take advantage of the efficiencies a multi-tenant system offers, it can be a risky undertaking. If you’re not careful, you could compromise isolation, leading to greedy tenants affecting availability and performance for others in the system—also known as noisy neighbors.
The recently published DynamoDB paper has been widely covered (if you haven’t read the paper, I would encourage you to at least read incredible summaries fromAlex DeBrie and Marc Brooker). In this blog, I’m focused on one of its hidden gems: how a mission-critical service like DynamoDB handles multi-tenancy. The paper has a lot to teach about creating a successful multi-tenant system, but it’s important to understand the benefits of multi-tenancy first—as well as the mechanisms used to avoid noisy neighbors.
Let’s dive in!
The why behind multi-tenancy
Multi-tenancy fuels innovation. Single-tenant systems typically operate at a smaller scale, incentivizing operators to do the minimal possible effort to sustain the system. As the customer base of a multi-tenant system grows, common patterns emerge—and it becomes easier to justify investments to innovate on behalf of the users. On DynamoDB, for instance, this fueled innovations like On-Demand provisioning, giving each DynamoDB customer the ability to deal with their bursts without ever having to provision for it.
Multi-tenancy yields better economics
Marc Brooker says it best:
Multi-tenancy is a big economic and efficiency win, and tends to allow much higher utilization of resources. That’s good for sustainability. It’s also good for availability, because there’s less dynamic range in the workload the system needs to deal with.
If you end up a believer in multi-tenancy, you may also want to read Allen Helton’s blog on multi-tenancy—and follow him on Twitter!
But how does multi-tenancy offer better economics? First and foremost, single-tenant systems are either a) overprovisioned (high cost), b) underprovisioned (risking outages during peaks), or c) both overprovisioned for average load and lacking ability to scale to handle bursts.
In a multi-tenant system, resources get consolidated into a shared pool—and the service owners innovate to improve utilization. Consider a collection of 100 individual caches. The aggregate peak load is meaningfully smaller than the aggregate of all the peaks in the system. A collection of single-tenant caches individually provision capacity to handle their peak load. Hence, the total provisioned capacity is the sum of the capacity required to handle each individual peak. In contrast, a multi-tenant system provisions capacity for the aggregate peak—which is meaningfully smaller than the aggregate of the peaks. This becomes truer as the number of caches in the pool increase.
Second, operators of large-scale multi-tenant systems wake up each morning and worry about how to make systems more cost effective (not to mention highly scalable and available). Cost optimizations can easily be a multi-month effort, which may be difficult to justify until sufficient scale. Furthermore, manual cost optimizations (like scale-down for your cache cluster) may introduce operational risk that isn’t worth taking (or spending effort in de-risking) if the reward is a few thousands dollars.
Consider a customer running a three-instance (cache.r5.xlarge) ElastiCache cluster costing $948/month. This cluster has 26GB of RAM, four VCPUs, and can easily handle over 100K requests per second (RPS) . If your team realizes you are only using 5GB of RAM—or your peak load is only 10K RPS, you may consider moving to a smaller instance size. You may even realize moving to a newer instance type—ideally with Graviton—can yield further savings and improved performance. On the other hand, if you are only spending $12K per year on this cluster, is it really worth dedicating a sprint or the operational risk to resize the cluster? Probably not. Most teams are understaffed, and there are easier ways to save money.
Now imagine if you are running a 3,000-node cluster costing $12M per year. Is it worthwhile to dedicate an engineer to assess the cost savings available to move to smaller instances or to Graviton? Or build automation to scale the size of the fleet to handle newer peaks? Or to deeply instrument the system for the automated deployments? Absolutely!
Operators of multi-tenant services take advantage of the economies of scale to innovate efficiency, scale, and availability of the system. Furthermore, once they have sufficient scale and data, they can start to oversubscribe the system, yielding further efficiencies. We see this phenomenon outside of the cloud world all the time: from banks to the eclectic grid to your ISP.
The Firecracker paper from the team running AWS Lambda covers the power of oversubscription as it pertains to running Lambda as a multi-tenant service:
Oversubscription is fundamentally a statistical bet … We set some compliance goal X (e.g., 99.99%), so that functions are able to get all the resources they need with no contention X% of the time … Keeping these workloads uncorrelated requires that they are unrelated: multiple workloads from the same application, and to an extent from the same customer or industry, behave as a single workload for these purposes.
DynamoDB takes on this statistical bet very successfully to deliver fundamentally different economics than a single-tenant system with idle resources:
DynamoDB employs a multi-tenant architecture. DynamoDB stores data from different customers on the same physical machines to ensure high utilization of resources, en- abling us to pass the cost savings to our customers.
Multi-tenant systems have more robust scaling
A second reason to use multi-tenant systems is for the better scaling properties they provide. There are many lessons teams learn as they scale to 100-node clusters. Unfortunately, these lessons often come one outage at a time. The journey is riddled with distractions for teams. Teams must do huge amounts of benchmarking, instrumentation, characterization, and tuning.
On the other hand, if you’re a customer of a large-scale multi-tenant system like DynamoDB, you can rest assured you would not be the first one to create a 100-partition DynamoDB table spanning hundreds of nodes behind the scenes. This seemingly massive scale is trivial in the context of the broader DynamoDB fleet:
DynamoDB achieves boundless scale for tables. There are no predefined limits for the amount of data each table can store. Tables grow elastically to meet the demand of the customers’ applications. DynamoDB is designed to scale the resources dedicated to a table from several servers to many thousands as needed. DynamoDB spreads an application’s data across more servers as the amount of data storage and the demand for throughput requirements grow.
Whatever scale you are planning to throw at the service, it’s surely handled something bigger for another customer (or aggregate of customers).
Multi-tenant systems scale and provision faster.
Well-built multi-tenant systems take advantage of warm pooling to handle bursts from a new customer or spikes from existing customers. This is excess capacity that the system keeps on hand to absorb spikes.
Warm capacity is technically a source of inefficiency. However, as systems grow larger (and collect more data), the operators can tune the amount of warm capacity required to deliver an awesome customer experience without wasting resources. A real-world example is the empty seats you may see on the public bus. It feels excessive until you realize most cars on the road are driving around with 4 empty seats. A bus with 50% utilization is meaningfully more efficient than the aggregate excess capacity in each car on the road. This gets dramatically more interesting once you incorporate all the seats in the cars that are not even on the road (0% utilization). Much of Uber’s innovations revolve around improving utilization of the cars ecosystem.
With warm pooling, a multi-tenant system gets near-instant provisioning. The best example of this is when Lambda functions instantly turn on when needed. Unless you are doing something massive or extraordinarily spiky, you do not need to worry about pre-provisioning capacity. The warm pools in Lambda can absorb the spikes and give you instantaneous access to a function which can get executed in line of a request.
This is meaningfully faster than putting autoscaled EC2 instances behind a load balancer because this requires a) detecting the spike, b) realizing you are under provisioned, c) instantiating new EC2 instances, d) waiting for them to boot up, e) activating them behind the load balancer, and f) new load starting to hit these instances. This process could easily take minutes. Compare that to Lambda, where the team has already built in the automation and warm pooling to give you the instant burst—and the judicious oversubscription required to do this efficiently.
Multi-tenant systems have better availability
The final reason to use multi-tenant systems is for better availability. For a cache, we include predictable performance and ability to handle usage spikes in our definition of availability. Let’s use another transportation analogy to understand this.
Despite any fear of flying you may have, you are far more likely to die from a car crash than an airplane crash—even if you travel more miles in an airplane. The operators of multi-tenant services like airlines take meticulous care of their aircraft and have deeper instrumentation on the health of their systems than the average car owner. Take-offs and landings (analogous to deployments) are rehearsed and well orchestrated with a whole control tower supervising operations. In contrast, many individuals driving their own cars means countless uncontrolled variables. Similarly, customers operating their own self-managed databases or caches often end up winging it with deployments like scale-in/scale-out.
Multi-tenant systems are much better characterized, have published limits, and fail in more predictable ways. Due to the availability bias, people often assume these systems are less available. This is often simply due to the fact these systems have done a better job of characterizing and outlining the ways they fail, whereas the self-managed systems yield more surprising outages.
For example, DynamoDB has a published limit of 1,000 writes per second for a single 1KB object—and a 400KB max object size (this can only be written to 2.5 times per second). Redis, on the other hand, does not have such limits and can likely take a lot higher throughput on a single key. However, your mileage may vary if you start storing 512MB objects or pushing hot keys. In this type of single-tenant service, you just don’t know the point when your service may tip over—and it may be different each day.
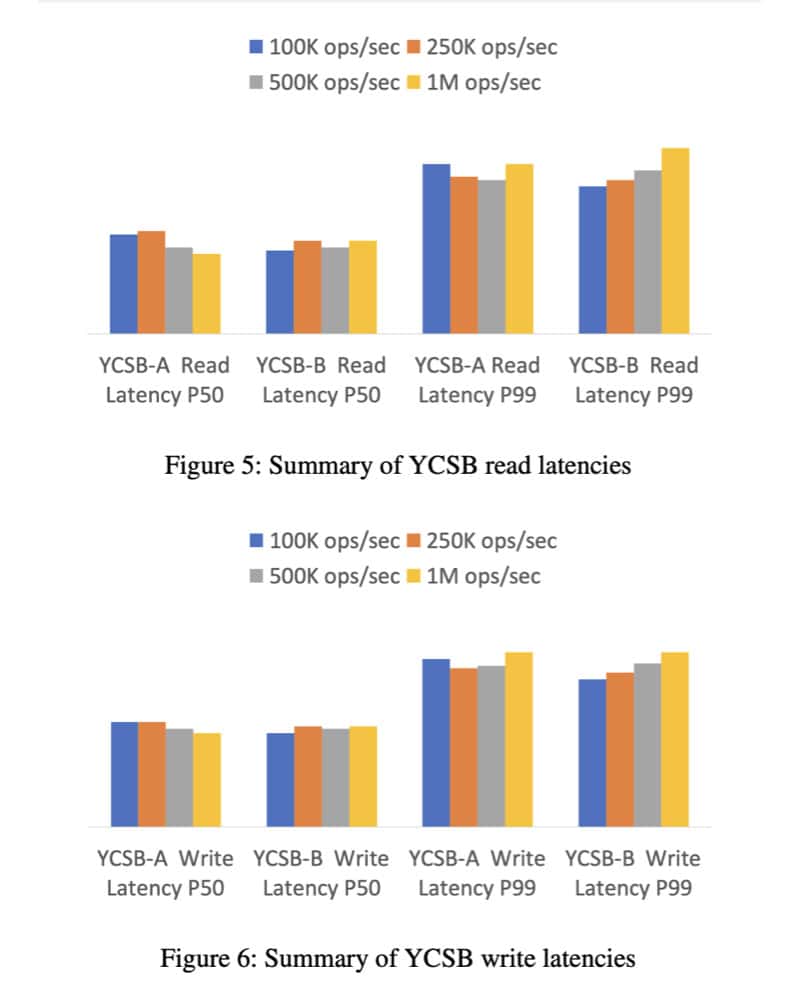
DynamoDB focuses on predictability. Figures 5 and 6 in the DynamoDB paper outline how the tail latencies look remarkably similar regardless of the load—100K operations per second (OPS) to 1M OPS. Upon publication of the paper, many were curious as to why the axes weren’t labeled. The answer is simple: the specific latency matters a lot less than the consistent performance of tail latencies (p99) independent of scale. In other words, DynamoDB’s performance at the client side is indistinguishable for loads of 100K, 250K, 500K, and 1M.
But the lack of variability by itself isn’t interesting until you consider the multi-tenancy implications of this test. The test was likely run against a multi-tenant DynamoDB production fleet filled with spiky workloads. This means the DynamoDB team was able to run 1M OPS without impacting fellow tenants—and of course the flipside is true, too: the DynamoDB team’s load experienced no impact from those other customers. You can reproduce this test yourself on DynamoDB without talking to an engineer and get the same results.
The bane of multi-tenant systems
So now we know why we want multi-tenant systems. Despite these benefits, why don’t we see more of them?
The answer is noisy neighbors. Greedy and noisy neighbors can take more than their fair share of resources, at the cost of impacting performance and availability of other tenants in the system. Accordingly, fairness and prioritization is key to building a successful multi-tenant system. The following sections cover how multi-tenant systems protect themselves from these scenarios with a deeper dive into the DynamoDB paper on this topic.
But first—it is imperative to understand single-tenant systems suffer from the same noisy neighbor problems.
For example, I may borrow my wife’s car, take it on a long drive, and forget to charge or refuel it. Meanwhile, she may be under the assumption she has plenty of fuel to get to work the next day—until she realizes mid-morning she is out of gas and has to refuel at the cost of running late to work.
Before you point out that I actually described a multi-tenant system with two tenants in the car (me and my wife), consider this: while you may be single-tenant on your ElastiCache Redis cluster, you may also have teammates (or microservices) who have access to the cluster. One rogue microservice can cause an impact to your entire cluster. Imagine the tail latency hit when one microservice adds a 10MB object in Redis, while another is doing scans.
Multi-tenant systems have deeper instrumentation and meticulous procedures to prevent common outages. Public buses have checklists and procedures in the morning (and throughout the day) to maintain the buses and to ensure there is sufficient gas.
The building blocks that support multi-tenancy in DynamoDB
We’ll see how DynamoDB supports multi-tenancy in the sections below. Availability is the key goal for DynamoDB. This includes successfully processing requests with predictable latencies at any scale. Being available requires DynamoDB to implement isolation (protecting customers from each other), fairness (prioritizing across customers when the system is under duress), and resource management (ensuring that there is sufficient capacity and that it is well utilized).
Let’s start with a quick look at DynamoDB’s storage system.
A DynamoDB table consists of partitions living on DynamoDB storage nodes. Each storage node consists of many partition replicas spanning tables and accounts. Because partitions from different accounts are co-located, DynamoDB needs to maintain isolation at a partition level. Left unchecked, a single partition can consume all the resources available on the node, leaving other partitions (and customers) starving.
Load shedding and load spreading to optimize resource utilization
A common theme in large distributed systems (like caching) is the notion of a hot shard (also commonly referred to as hot partition). This happens when one node in the distributed fleet is handling an overwhelming amount of load. As a result, a common technique is to double the size of the fleet to spread the load further. Similarly, if the load is unevenly spread between the nodes in a distributed system, the aggregate size of the system grows proportionately to that imbalance.
To improve utilization, DynamoDB has innovated extensively on spreading the load across storage nodes. To understand how it is done, we start by learning about the autoadmin service, the central nervous system of DynamoDB. The paper outlines it as:
The autoadmin service is built to be the central nervous system of DynamoDB. It is responsible for fleet health, partition health, scaling of tables, and execution of all control plane requests. The service continuously monitors the health of all the partitions and replaces any replicas deemed unhealthy (slow or not responsive or being hosted on bad hardware).
The autoadmin coordinates changes across the fleet. This centralization allows DynamoDB to continuously monitor the fleet, while minimizing the churn in the fleet that could occur if too many nodes made decisions that caused a feedback loop.
The storage nodes also monitor themselves for utilization. If a storage node ever detects that it is beyond a configurable threshold, it informs the autoadmin service and proposes a list of partitions that ought to be moved away to reduce load. The autoadmin is aware of utilization across storage nodes, and finds new homes for the partitions in the list (presumably the underutilized storage nodes). This continuous monitoring enables the load to remain spread even as the usage patterns of each partition evolve. From the DynamoDB Paper:
In case the throughput is beyond a threshold percentage of the maximum capacity of the node, it reports to the autoadmin service a list of candidate partition replicas to move from the current node.
This simple technique allows DynamoDB partitions to burst beyond their provisioned or allocated capacity, but it also does a great job migrating load away from storage nodes that are at risk of becoming overwhelmed.
Fairness matters but isolation and utilization matter more
Sufficient capacity and an evenly spread load makes a fair experience automatic. Fairness comes into play mostly when the system is under duress. A DynamoDB storage node serves requests as long as there is sufficient capacity available. This oversubscription allows DynamoDB to improve utilization across customers with provisioned IOPS as well as customers that are running on-demand.
This approach does not work in isolation, and it is complemented by multiple mechanisms (controlled bursting, prioritization, and throttling). First, controlled bursting limits the maximum IOPS a single partition could consume on the node. This reduces the blast radius of a partition on the node—and enables more effective capacity planning for the DynamoDB team.
Second, bursts are only available to partitions which happen to land on nodes with unused capacity. The paper mentions:
DynamoDB still maintained workload isolation by ensuring that a partition could only burst if there was unused throughput at the node level.
There are two types of tables in DynamoDB (provisioned and on-demand). In the provisioned tables, IOPS are spread between the partitions. However, the system allows these partitions to burst beyond their provisioned IOPS as needed. DynamoDB on-demand tables rapidly adapt to customer workloads, obviating capacity management from the customers. They are analogous to EC2 Spot Instances—but the tight capacity management and load spreading enables the DynamoDB team to offer an almost indistinguishable experience for the on-demand tables.
DynamoDB prioritizes requests to get the best of utilization and isolation. For instance, when a storage node is under duress, imposing fairness becomes important. Partitions with provisioned IOPS on the node get priority over partitions that are bursting above. This is usually a short-lived phenomenon given the proactive load shedding mentioned above: storage nodes under duress quickly work with auto-admin to spread the load. On the other hand, when the nodes are under low utilization, each partition has the ability to burst up to a threshold (3,000 IOPS), independent of the IOPS provisioned for it. The team works hard to optimize this statistical bet to meet their SLOs (increasing utilization makes the noisy neighbor impact more likely, while decreasing utilization erodes efficiency)—and since most customers never notice variability, the team has been pretty successful at isolation.
Throttling via global admission control (GAC)
In the early days, DynamoDB imposed IOPS limits at a partition level on the storage node. This had a pretty terrible side effect on customers whose IOPS were not distributed well across all of their partitions. In those situations, customers would observe throttling on their tables despite utilizing a small partition of their provisioned IOPS.
DynamoDB innovated in this space with the notion of Global Admission Control (GAC). This allows IOPS to be enforced at a table level, instead of at a partition.
DynamoDB requests travel through a stateless request router layer that forwards operations to the relevant storage nodes. These request routers know the number of IOPS allocated to each table. They connect with a fleet of GAC nodes, and they track the token bucket for an assigned table. This way, any table consuming too much capacity can get throttled at the request router before the request even makes it to the storage node.
The storage node token buckets have been retained for defense-in-depth. They serve as a second layer to ensure that even if request routers let in more requests than a node could handle, the storage node can isolate partitions and prioritize the partitions below the burst threshold.
Final thoughts
DynamoDB is among the best examples of how multi-tenancy fuels innovation. Being able to apply multi-tenancy at scale with mission critical availability required the team to innovate on utilization, cost optimizations, and performance. The customers got all these benefits without becoming distributed systems experts—and the system kept evolving underneath them.
DynamoDB handles multi-tenancy through complementary mechanisms around load shedding, throttling at the node level and table level, and handling bursts on a best-effort basis. None of these systems are sufficient in isolation—but together, they formulate an incredibly reliable, mission-critical service for Amazon retail, most AWS control planes, and consequently, most AWS customers.
Multi-tenant systems are more available, have fundamentally better economics, and offer a better experience than single-tenant systems. Meanwhile, many single-tenant systems are often susceptible to the same noisy neighbor issues from which well-built multi-tenant systems explicitly protect customers.
We are embracing multi-tenancy wholeheartedly at Momento, and it’s fueling innovation. We are already operating at a scale where the deep investments in resource and performance optimizations are worthwhile—and we are eager to continue down this path to delight our customers.


