 Ellery Addington-White
Ellery Addington-WhiteServerless and multi-cloud are buzzwords developers hear often—but not usually together. Typically when developers think of serverless, they think of architectural components that are tightly coupled with the cloud they are running in—not easily shifted to a different cloud. Similarly, when they hear multi-cloud, people tend to jump to Kubernetes (k8s) and the assumption that k8s is the only way to enable this layer of abstraction. In this article, I cover practical advice on how to think about multi-cloud, share patterns to make your workloads more portable, and show how serverless and multi-cloud can actually go hand in hand.
What does multi-cloud really mean?
Some vendors insist on pushing multi-cloud, using the exact same infrastructure stack across clouds. They claim that getting there—at any cost (including giving up most of the benefits that brought you to the cloud)—is worth it. This tends to lead back to a lousy developer experience and lowest-common-denominator infrastructure services that have high admin overhead. In reality, you need your business logic to be portable—but the infrastructure does not necessarily need to be. You should still pick the best tools for the job and the best of each cloud you are in.
To achieve this, instead of making your infrastructure portable, you should be focusing on lowering the operational surface area required to run your application in each cloud. Adopting this mindset will help with getting up and running within another cloud provider while still being able to move fast and independently as an engineer at any scale. Reducing your operational surface area makes it easier to jump between cloud providers without a heavy lift.
What does this look like in practice?
This is where serverless microservices come in. Using API-accessible data model services instead of cluster-based services is ideal because those APIs can be portable between clouds.
Keep your API routing cloud-agnostic
For example, in my demo repo, I use Serverless Express so that my routing has the same behavior regardless of whether I’m running it on AWS, GCP, or my dev laptop. Keeping your API routing agnostic makes it easier to bundle your application code to run in a Lambda, Container, or directly on a VM or dev laptop.
Pick fully managed services and serverless APIs
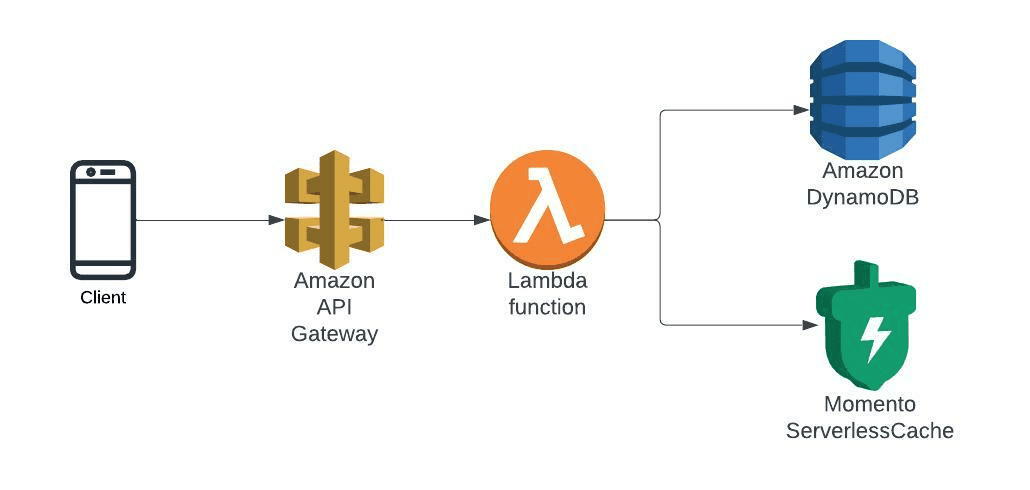
In AWS we end up with an architecture like this:
And in GCP like this:
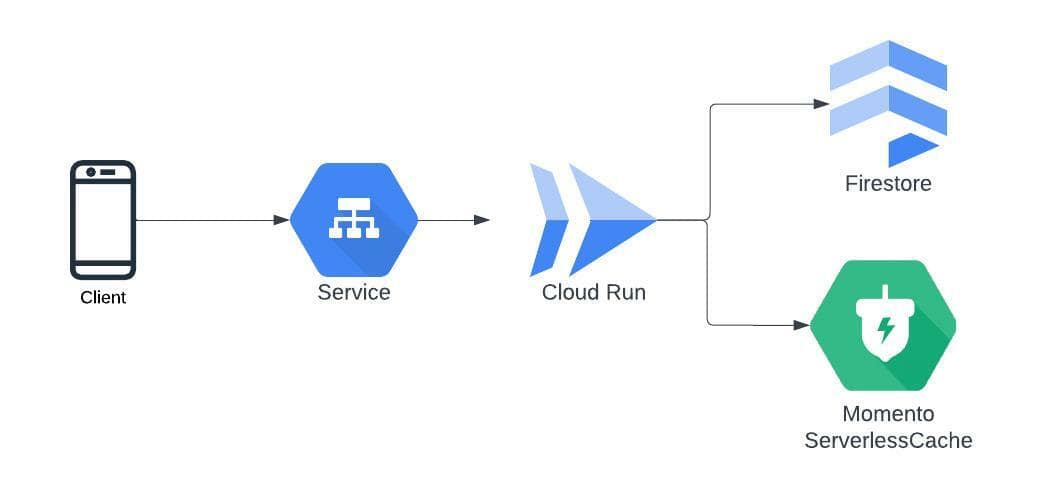
Using serverless API driven data models instead of cluster-based database and analytics infrastructure helps with the reduction of operational surface area by removing the complexities needed to operate within each cloud. In the above examples, we use Momento Cache as our fully managed cache across both AWS and GCP. This allows us to make the developer experience, operational model, and performance consistent across both clouds without dealing with issues like networking, autoscaling, cluster configuration, and the management differences between all that in GCP and AWS. Similarly, we use Cloud Run in GCP and Lambda in AWS for our compute layer and Firestore in GCP and DynamoDB in AWS for data persistence.
Use a higher level Infrastructure-as-Code (IaC) framework
This reduces the operational surface area by providing higher-level infrastructure constructs for spinning up a simple API with best practices baked in. Also, try to pick an IaC framework that supports multiple clouds like CDK and CDK-TF, Pulumi, Ampt, or Terraform so you get a consistent developer experience across both clouds.
Focus on creating good abstractions within your code
By focusing on making your code base flexible instead of your infrastructure, it makes switching vendors or implementations easier down the line (much like CBS found when they invested in facades). New technology will continue to come. By making your code base flexible to swap out different providers for storage, in-memory cache, and compute, it will allow you to quickly and easily try new things as the industry progresses—not to mention the added benefit of portability to your workload.
Here’s another example of an interface to increase portability, where I create one for my datastore so it’s easy to swap out DynamoDB or Firestore. First, I define a standard interface for my data clients.
export interface DataClient {
createUser: (user: User) => Promise
getUser: (userId: string) => Promise
}Then I can swap out the implementation at the start up of my API for each data client implementation.
DynamoImpl
import {DynamoDBDocumentClient, GetCommand, PutCommand} from "@aws-sdk/lib-dynamodb";
import {DynamoDBClient} from "@aws-sdk/client-dynamodb";
import {DataClient} from "../users";
import {getMetricLogger} from "../../../monitoring/metrics/metricRecorder";
// Clients --
const ddbClient = DynamoDBDocumentClient.from(new DynamoDBClient({}));
export class UsersDdb implements DataClient {
async createUser(user: User) {
await ddbClient.send(new PutCommand({
TableName: "momento-demo-users",
Item: user,
}));
}
getUser(userId: string): Promise {
return getUserDDB(userId)
}
}
export const getUserDDB = async (id: string) => {
const startTime = Date.now()
const dbRsp = await ddbClient.send(new GetCommand({Key: {id}, TableName: "momento-demo-users"}));
getMetricLogger().record([{
value: Date.now() - startTime,
name: "UpstreamProcessingTime",
labels: [{k: "upstream", v: "dynamodb"}],
}])
return dbRsp.Item as User
};FirestoreImpl
import {Firestore} from "@google-cloud/firestore";
import {DataClient} from "../users";
import {getMetricLogger} from "../../../monitoring/metrics/metricRecorder";
// Clients --
const firestore = new Firestore({
projectId: process.env['PROJECT_ID'],
preferRest: true, // Drops response times in cloud run env
});
export class UsersFirestore implements DataClient {
async createUser(user: User): Promise {
await firestore.collection(`users`).doc(user.id).set(user)
}
async getUser(userId: string): Promise {
const startTime = Date.now();
const dbRsp = await firestore.collection(`users`).doc(userId).get();
getMetricLogger().record([{
value: Date.now() - startTime,
labels: [{k: "upstream", v: "firestore"}],
name: 'Upstream'
}])
return dbRsp.data() as User
}
};Closing thoughts
Reducing your operational surface area makes it easier to jump between cloud providers without a heavy lift—which ultimately empowers developers to innovate independently, and positions your business for success at any scale.
If you have more questions about starting your journey with serverless and multi-cloud, join our Discord server—and if you’re ready to reduce operational surface area today, get started with Momento Cache!


