
Enterprises constantly seek ways to expedite software delivery without compromising quality or exhausting resources—all while preserving an agile product feedback loop. It can feel almost impossible to manage these competing interests, but serverless computing makes it feasible.
What is serverless?
At its simplest, serverless is a categorization describing a software component. These components provide the developer with a contract around price, consumption, scale, and reliability. Something is said to be serverless if it displays these attributes:
- Nothing to provision, nothing to manage. Serverless doesn’t mean the lack of infrastructure, just that the provisioning and maintenance of that infrastructure are abstracted away from the builder.
- Cost scales predictably with usage. With serverless, usage and cost have a linear relationship. As usage goes up, so does cost; and as traffic goes down, cost does, too—all the way to zero.
- No planned downtime. With no infrastructure to maintain, serverless means no maintenance windows, which means higher availability.
- Ready with a single API call. There can be some variation here from putting a file in S3 to launching a container in AWS Fargate, but serverless services are ready to be consumed on a moment’s notice.
Serverless is more than compute
If this sounds strangely like AWS Lambda or Microsoft Azure Functions, that’s because those two services are examples of serverless compute. But when leveraging serverless technologies there is a great deal more at an engineer’s disposal than just compute.
Serverless components exist at all levels of an application’s architecture. There are services for data, event management, workflow coordination, object storage, and API gateways just to list a few—like in this example of a web-based request designed to handle input, persist the output, and then propagate that change via change data capture. Every component here is serverless.
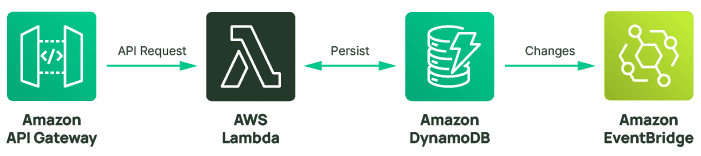
These single-purpose serverless components embody all the attributes listed above. They are assembled like building blocks to deliver robust architectures that perform everywhere from ultralight to massive scale.
But if components are single-purposed, how does a developer or architect design around these capabilities? This is where the enterprise needs to be prepared to invest in its people.
Serverless is more than technology
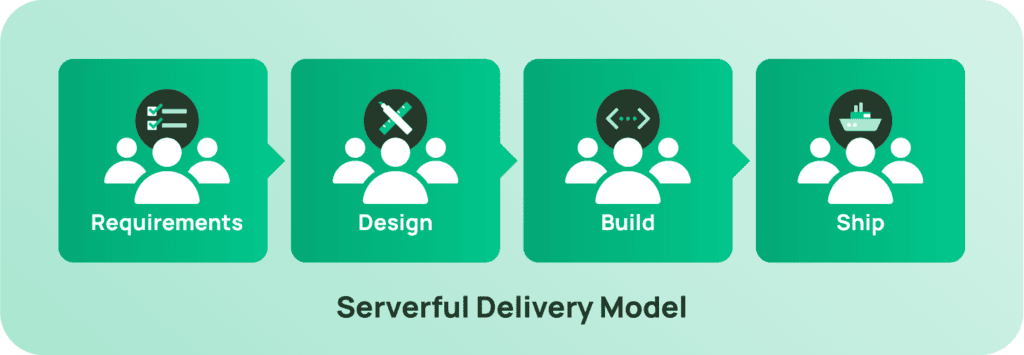
People are at the heart of every technology solution—the designers, builders, and operators. In a traditional “serverful” world, tasks to bring a software solution to market are often siloed and executed in a sequential or waterfall fashion. Engineers and operations teams work together but not always in harmony. In the case that a design doesn’t match the needs of the user workflows, teams must work back through the process to remedy the issue.
Contrast that with a design that has invested in serverless, and a couple of things will begin to happen. The first outcome is that the job roles and functions needed to ship a product will start to compress. Product people will start to understand cost and scale at a much more intimate level. Operations engineers who, in serverful delivery, are focused on strictly running infrastructure will now be assisting in the selection and configuration of serverless components.
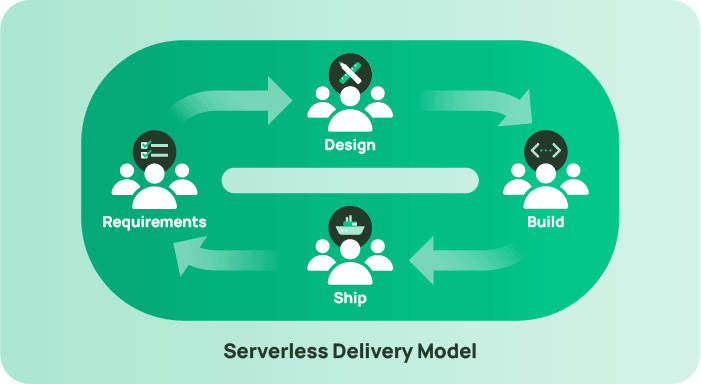
The second outcome is that delivery teams who are working with autonomy to ship value to their customers will be able to experiment and pivot much faster. These teams won’t be heavily invested in infrastructure or sunk costs, nor will they be constrained by a design that was built with a stream when all it needed was a queue. Serverless builds are adaptable, configurable, and modular, giving teams an advantage over competition working strictly with custom-built infrastructures.
So how can an enterprise take advantage of the serverless model?
Where to get started with serverless
The age-old “where to begin” question strikes people first. The start sometimes paralyzes even the most experienced enterprises, but that shouldn’t be the case with serverless. Two natural starting points hold whether the enterprise is shipping consumer software, business-to-business software, or providing software as internal tools to support its operations.
New Features
Building new software is the perfect place to begin an enterprise’s serverless journey. This endeavor doesn’t have to be large either. When trying out a new technology, starting at either end of the difficulty spectrum can be a good choice. If the build is easy, an enterprise can see a quick win and gain confidence. If the build is difficult and highly demanding, the enterprise tackles something challenging, gains confidence, and proves or disproves critical assumptions about the technology. However, if the enterprise wants to start with something difficult, it might be useful to bootstrap the organization’s capabilities by bringing in some seasoned experts. Serverless knowledge will spread like wildfire, so be prepared—in a positive way—for this engagement.
When introducing serverless on new builds, the following areas are generally good starting points:
- API development. This combines components like Amazon API Gateway, AWS Step Functions, Lambda, and DynamoDB.
- Data pipelines. Data movement is a common challenge in any application. Serverless components can turn traditional batch-based operations into nimble, real-time data moving powerhouses. Tools like Step Functions, DynamoDB, Amazon Kinesis, and Amazon SQS are all helpful in these workloads.
Existing Applications
Many enterprises don’t always have new features rolling out where they can try brand new patterns. This is why starting small with an existing application can be extremely valuable.
A common scenario ripe for a serverless build is the extension of an existing application. One such use case is adding functionality to an API. By leveraging Lambda, API Gateway, or even an existing load balancer, new functionality can be added without disturbing a monolithic component. Remember: Lambda and serverless are not synonymous, but using Lambda as an event-driven compute engine—as it was intended—is a very natural starting point.
The beauty of extending an API with Lambda is that an enterprise can bring its existing toolchain. Heavy on .NET Core? No problem, Lambda can do that. Does the enterprise lean into Java? Lambda can do that. Lambda also comes prepared with Linux-based runtimes to launch Rust and Go code. Or perhaps there’s already a heavy investment in containers? Lambda will run those too.
Once that first Lambda function is in place, the enterprise will have developed the skills and confidence to explore and expand the solution to other serverless components. The key is to start small, learn, adapt, and integrate.
Conclusion
With serverless technologies like Momento, it’s possible to achieve faster, higher-quality outcomes with fewer resources. The first steps to making it work for your business are cultivating a culture of experimentation and then picking a place to start—whether that’s a new feature or an existing application.


