3 crucial caching choices: Where, when, and how
The right questions determine the right caching strategy.

Share
Caching is fast. With an in-memory system optimized for key-value access, you can get sub-millisecond p99 response times as measured by the client. Because it’s so fast, caching is fun. It can be the difference between a high-latency experience that frustrates users and a smooth, delightful one that creates repeat customers.
But caching can also be a footgun. There are effective ways to use caches, and there are ineffective ways to use caches—and even worse than ineffective caching strategies are harmful caching strategies: ones that confuse your users via stale, inconsistent data or that reduce your application availability.
So how can you settle on a caching strategy that gets all the customer delight and none of the footgun? It’s a great question—one I’ll be answering over the course of two blogs. The second installment is where I’ll cover actual strategies and patterns for caching in your application. In this first one, I’ll cover three key choices that will determine your strategy:
- Where to cache: local vs. remote
- When to cache: read vs. write
- How to cache: inline vs. aside
Where to cache—local vs. remote caching
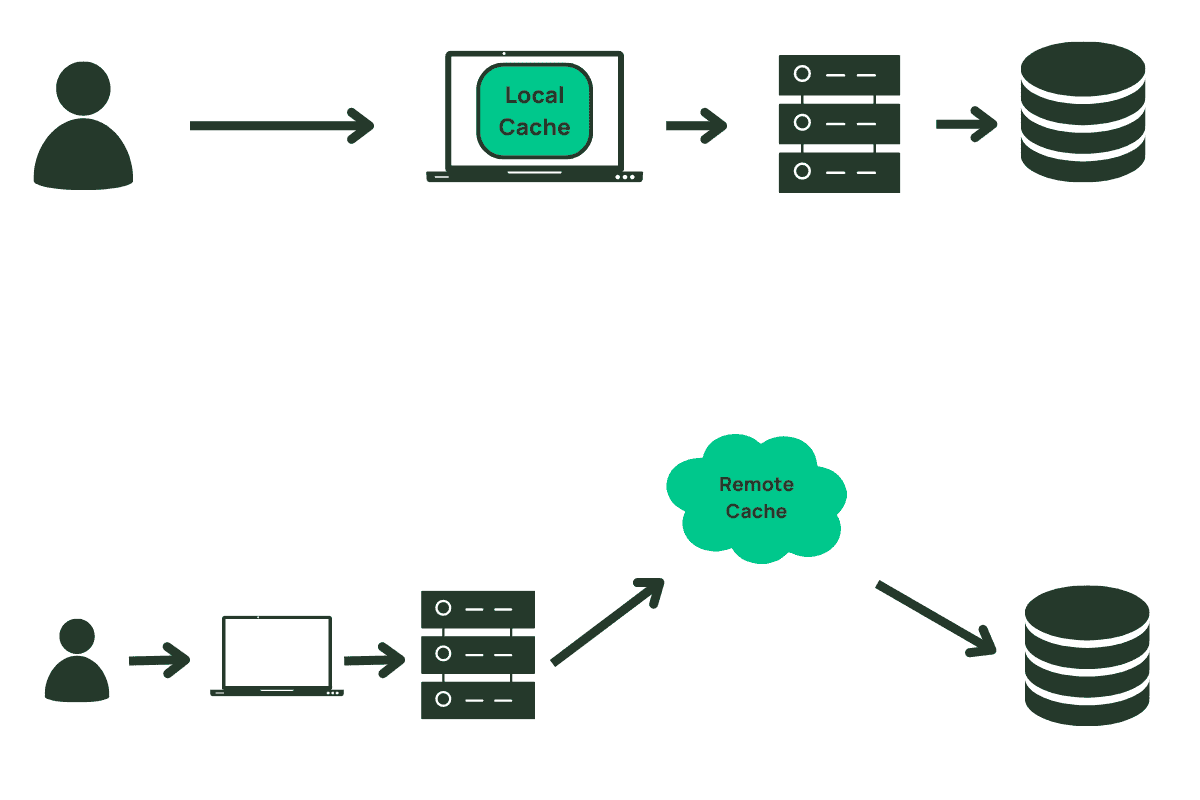
When thinking about caching, we often jump to a centralized, remote cache that is used like a faster, less durable version of our database. But a cache need not be a separate piece of infrastructure. You can add caching locally to your application, whether on your backend servers or even on your users’ browsers. When we say ‘local’ caching, we mean caching that is local to some compute and that is inaccessible from other compute instances.
In general, the question of a local vs. remote cache comes down to utility vs. simplicity. A local cache is usually easier to add to an application than pulling in a new piece of infrastructure. Additionally, a new piece of infrastructure brings additional challenges around availability and application uptime that a local cache will generally avoid.
On the other hand, a local cache is less useful than a centralized cache. If you are caching on your backend servers, the chance that a request will be served by a machine that has previously cached the data is reduced as the size of your fleet increases. This is even more true due to the ephemerality of modern cloud-based applications. Serverless functions, containers, or instances are becoming more and more short-lived as applications scale up and down dynamically to match demand. A fresh instance of your application has no local cache and thus has no benefit for the initial requests to the application.
Finally, a local cache can make it harder to manage stale data. When data is altered or deleted, it is easier to make a corresponding update to the cached data in a centralized, remote cache. It is more difficult to indicate updates to cached data that are distributed on local application instances or client browsers. Because of this, a local cache may only work for certain types of cached data or with low time-to-live (TTL) configurations.
A remote, centralized cache does not have these downsides. It can be used by any servers that are handling a piece of work, making it more broadly useful for your application. Further, remote caches generally have mechanisms to expire data on-demand, allowing your write path to purge data after it has been altered. The downsides of a remote cache are centered on the operational challenges of maintaining a separate piece of infrastructure (though it’s worth noting that Momento Cache solves this problem). If you want a deeper dive on where to cache, check out another blog I wrote: Cut the caching clutter: understanding cache types.
When to cache: read vs. write caching
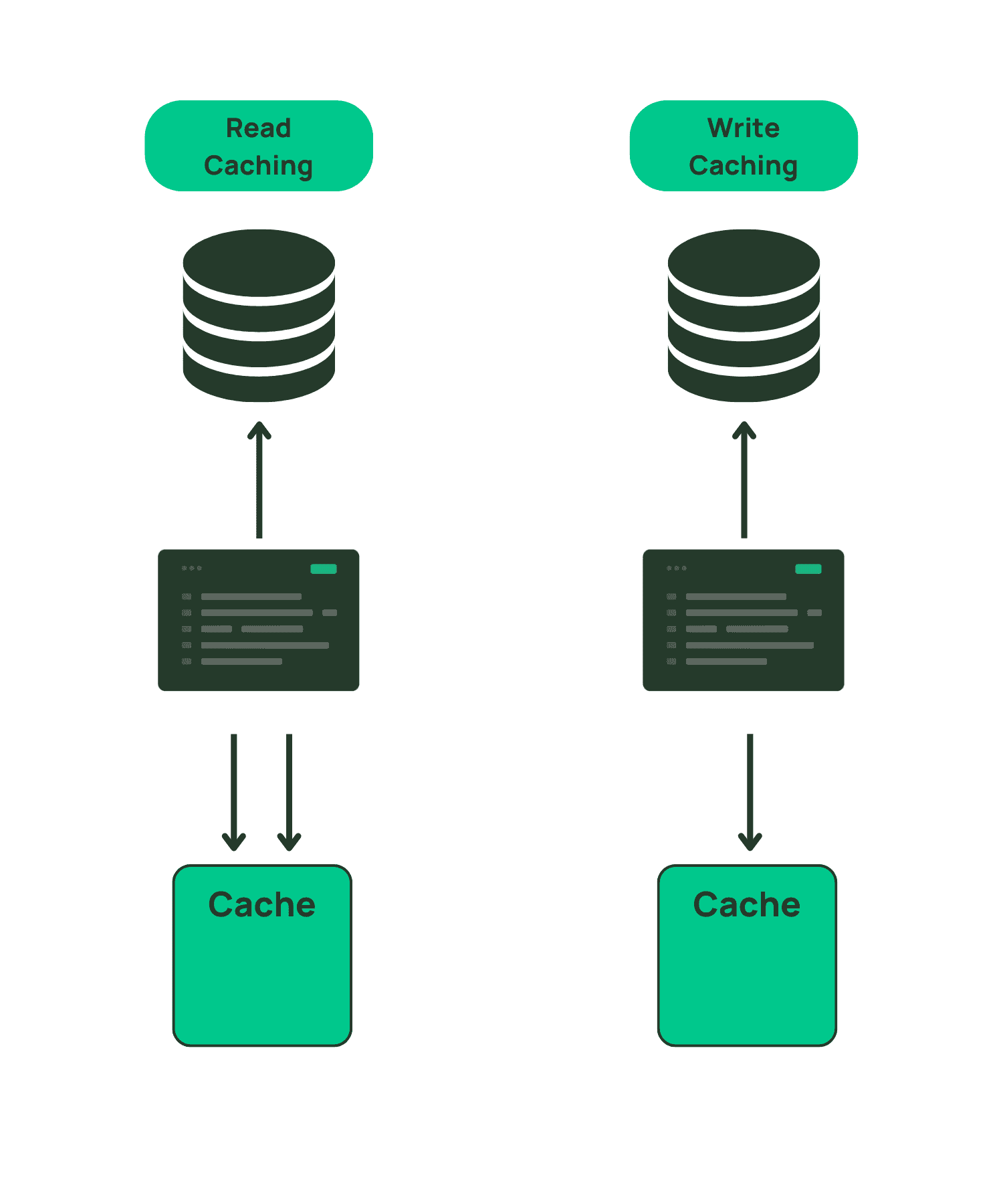
Again, you have two choices: cache the data when it is read the first time (often called “lazy-loading”), or cache the data when it is written.
The most popular caching pattern is likely the read-aside pattern. For this pattern, your application first attempts to read and return data from the cache on a request. If the data is not currently in the cache, the application falls back to the database to read the data. It then stores it in the cache before returning the response so that the retrieved data is available for the next request that needs this data.
The opposite pattern is to load your cache following a successful write. After a write succeeds, you would proactively push it to the cache in anticipation of imminent use.
The benefits of caching data when it is read are its flexibility and space efficiency. Lazy loading is a flexible pattern that can work for almost any dataset. You can use it to cache individual objects, a result set of multiple objects, or an aggregated value. Whether caching results directly from a database or some results after computation, read-aside caching is easy to implement as you simply cache the final response before returning to the client.
This is more difficult when proactively caching on the write side. While caching individual items on writes can be straightforward, it is more difficult to proactively cache result sets or aggregated values as it requires a deeper knowledge of what the read patterns are and how those patterns are affected by writes.
Additionally, lazy loading is a more space-efficient use of your cache. Rather than loading data into your cache at write time, regardless of whether it will be read again, you are only caching data once it is read. In many applications, reads of individual data are correlated across time. Something that is read once is more likely to be read soon after. By only caching data once it has been requested at least once, you are optimizing for caching more frequently accessed data.
The downsides of caching data when it is read are the slowness of the initial read along with the possibility of returning stale data. Because you are only loading the cache once data is read, it means that each piece of requested data will need to make at least one request through the slower, non-cached path. Depending on your application needs, this may be suboptimal.
Further, a pattern that only caches data on the read side will be subject to returning stale data to clients. If the underlying data has changed without a corresponding eviction of the cached data, users could see confusing results. Applications can mitigate this by caching data for a shorter time, though that exacerbates the downside noted above where there is a cache miss.
How to cache: inline vs. aside caching
In the previous section, we talked about a read-aside cache. An aside cache is the most straightforward type of remote cache, where it stores data explicitly given to it by your service. It usually has simple get and set semantics that can flexibly store any piece of data that you want, but you must store that data specifically. If the data does not exist in the cache, your service is responsible for finding the underlying data elsewhere and updating the cache, if desired.
On the other hand, an inline cache is one that is transparent to your service that is calling to retrieve the data. Your application will hit the inline cache directly to retrieve the item. If the cache does not have the requested data, the cache itself will do the work to fetch the data from the upstream data source.
You can see why these caches get the name from the architecture diagrams below. The aside cache sits aside your application and is called separately from your data source. Alternatively, the inline cache is used inline with your request to the data source.
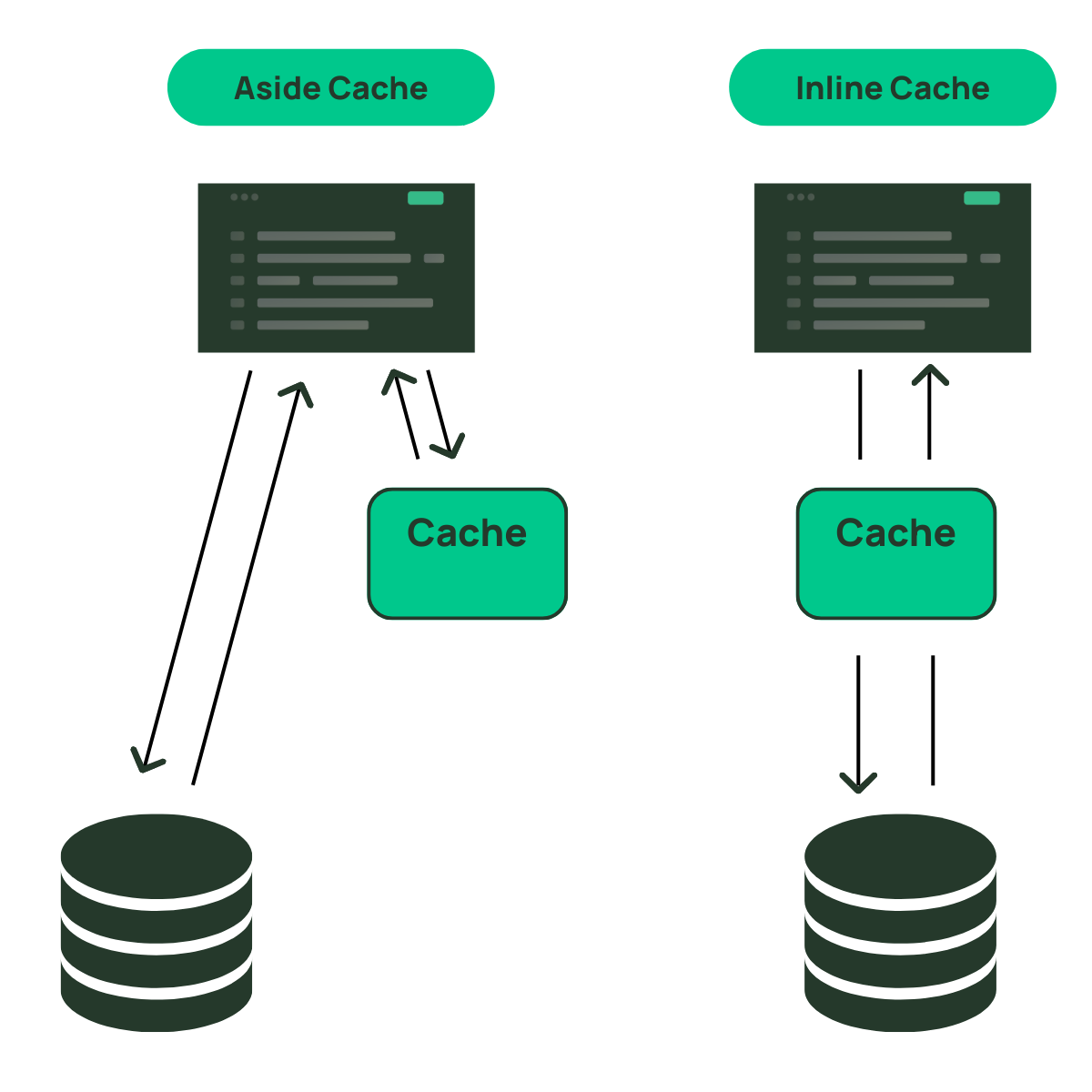
Aside caches are more common due to their flexibility for nearly any use case. Additionally, they are decoupled from your end datastore and allow you to choose how to handle failures at the caching layer.
The benefit of an inline cache is simplicity within your application. Your application doesn’t need to worry about multiple different stores and the corresponding logic to fallback to a database in the event of a cache miss.
The downside of an inline cache is the reduced availability for your application. You’re adding in an additional piece of infrastructure that not only adds caching functionality but also takes responsibility for talking to your database. If your cache goes down, you may have trouble falling back to your database as the cache itself was talking to your database.
Another downside of the inline cache is the availability of such services. An inline cache has a tight integration with the downstream data source that it is fronting. As such, someone needs to specifically build a cache that integrates with the primary data source. Because of this, inline caches are generally reserved for generic protocols or as proprietary add-ons to a specific database.
Conclusion
Considering key caching choices is a critical step that will largely determine the caching strategy that’s right for your use case. I’ll cover the actual caching strategies and patterns in the next blog, so stay tuned!
If a remote, centralized, read-aside cache with none of the operational challenges sounds perfect, Momento Cache will be a great fit. Even if your needs differ, you can get in touch with them to discuss your use case and find a solution.
Download our guide to find out if your enterprise is ready for serverless.

Share





