 Alex DeBrie
Alex DeBrieCaches are powerful because they provide lower latency and happier customers, and Momento is continually pushing the envelope to provide a cache with consistently fast performance that’s easier to use and more reliable than what’s available elsewhere.
But it’s important to point out that caches aren’t right for all situations, and a central cache like Momento isn’t the right solution every time you need a cache. There are different types of caches, and the type of cache you use should match your needs.
In this blog post, we’ll review three different types of caches and when you should use them. First, we’ll look at classifying caches based on how centralized the cached data is. Then, we’ll review central caches, edge caches, and local caches to see examples of different points on the centralized vs. decentralized cache spectrum.
Centralized or decentralized: how distributed is my cache?
You can find comparisons of various caches based on features (“does this cache support multi-set?”), based on performance (“how many requests per second can it handle?”), or based on the operational model (“does my team have the expertise to manage it?”). But these are all comparisons of similar types of caches—”central caches”—and a central cache may not be right for your needs.
Two other types of caches are “local caches” and “edge caches”. There are a variety of reasons to use caches, but the most popular one is to reduce latency to your users. One of the clearest ways to reduce latency is to reduce the distance your application needs to go to retrieve data. This is the main impetus for local caches and edge caches.
To reduce the distance for an application client to retrieve the data, we often need to push that data further from its primary source. Rather than making the clients come to a single, central location to retrieve the data, we decentralize the data to a number of locations.
But, like all choices in computers and in life, there are tradeoffs to decentralization. A cache is almost always a secondary representation of your primary data. Accordingly, updates to your primary data can mean your cache is stale and out-of-date. The difficulties of cache invalidation are highlighted by the most famous joke in computer science, and these difficulties are compounded as you distribute your data further. The more distinct nodes holding cached data, the more difficult it is to purge that data as it changes.
In the sections below, we’ll walk through three different types of caches—central caches, local caches, and edge caches. As we go, we’ll use an example application to illustrate where these types of caches would apply and how they would help.
For this example, imagine you’re building a standard SaaS application with a tiered architecture that looks something like the following:
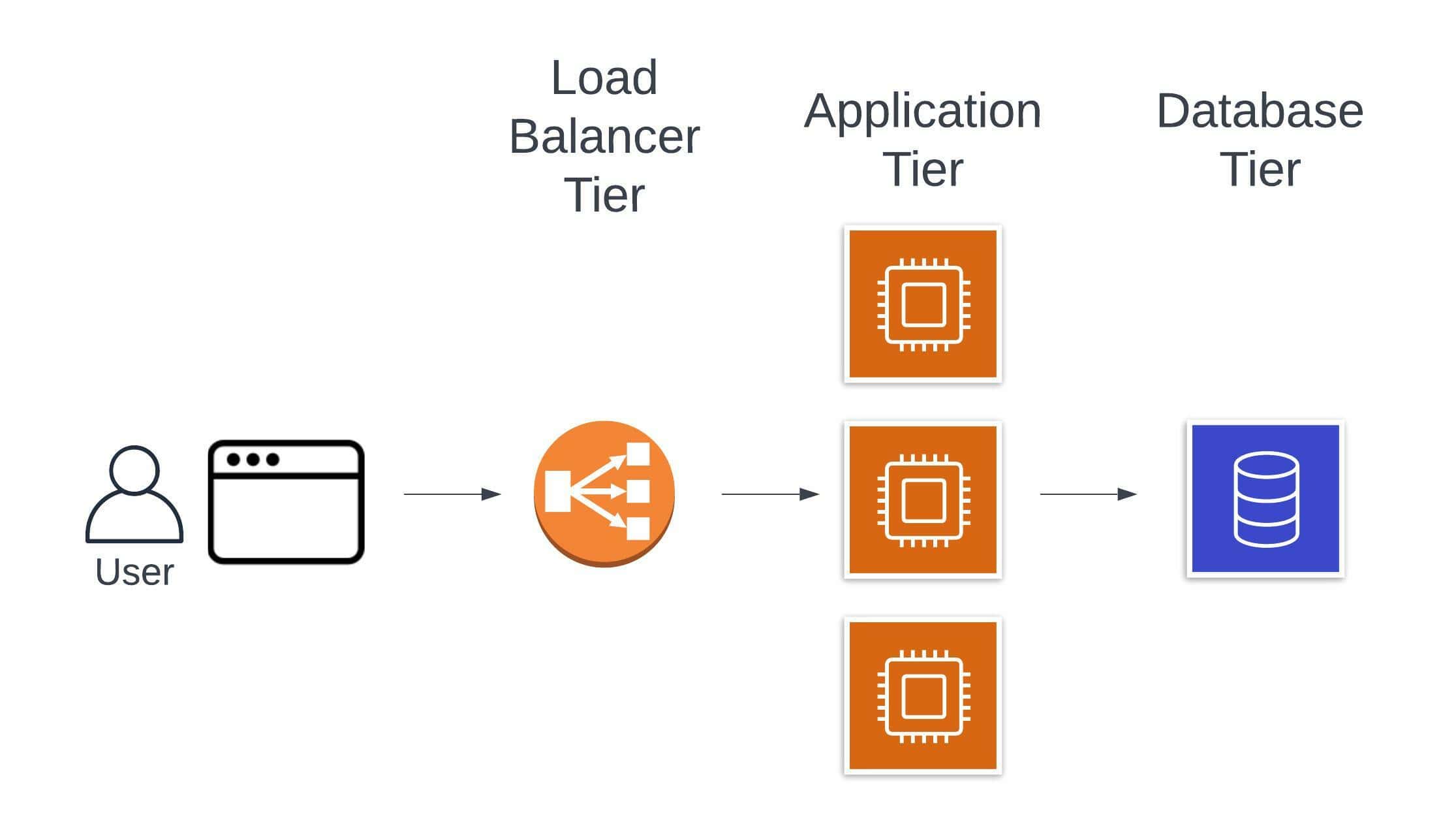
Users will use their web browsers to interact with the application. The browser will make HTTP requests that go through a load balancer to the application layer responsible for business logic. Persistent data will be stored in a database for use by the application layer.
The specifics of this architecture can vary greatly. You may be using a LAMP stack with an Apache web server to handle load balancing, a PHP application running on a Linux machine, and a trusty MySQL database for the data layer. In a more modern, “serverless” architecture, you might use AWS API Gateway for load balancing, AWS Lambda as your application tier, and Amazon DynamoDB as your database.
In the following sections, we’ll see where and when you would place different types of caches in your architecture.
Supercharge your application with a central cache
The first kind of cache is the central cache, which is the type that typically comes to mind when you consider adding caching to your application. Momento is a central cache, as are traditional options like Redis and Memcached.
As the name implies, central caches live in a central location near your application servers and primary databases. If you’re running in a public cloud, they’ll likely be in the same region as your core infrastructure.
In our application example, central caches show up as follows:
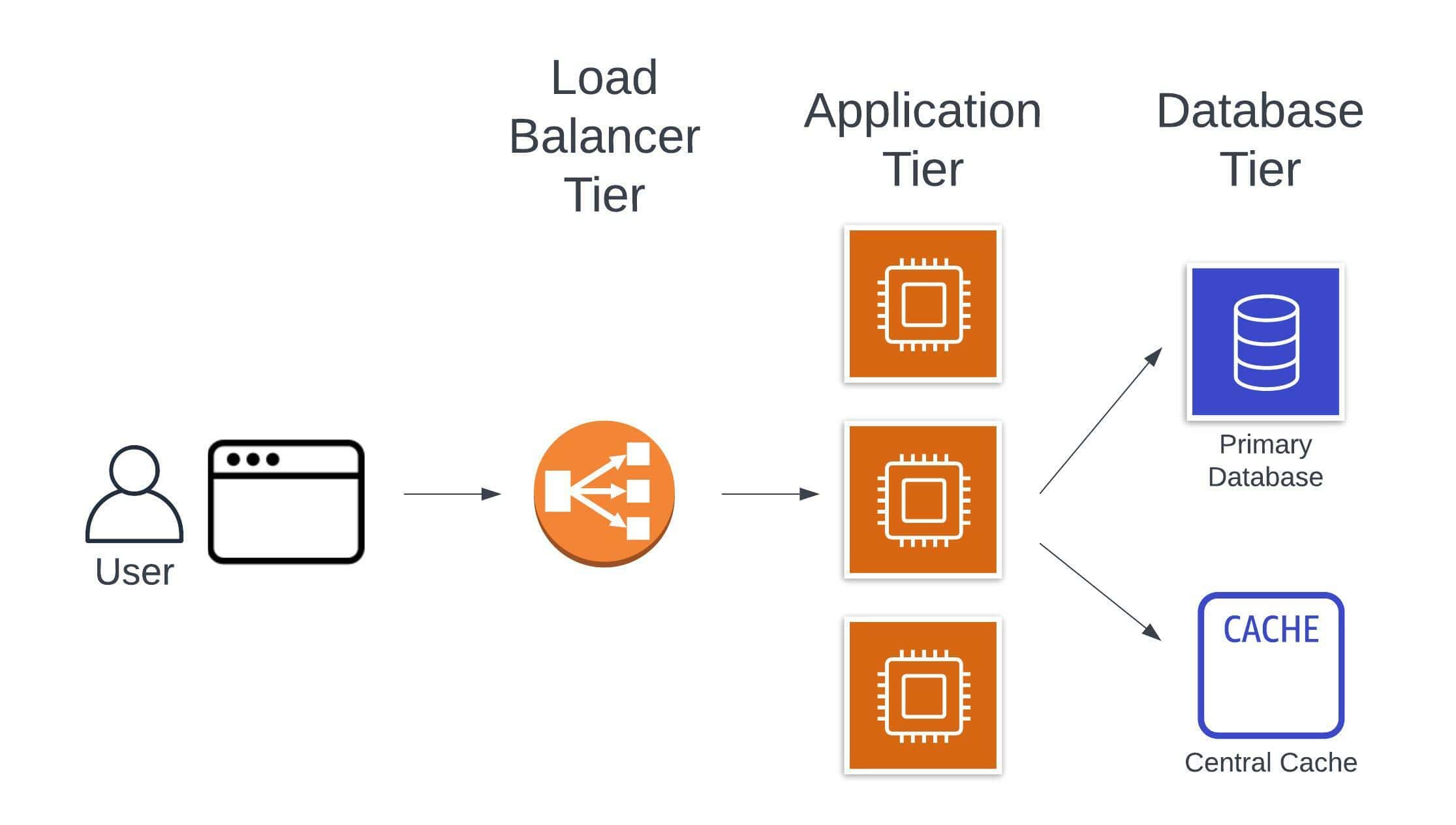
In most cases, central caches are used as supplements to other systems, such as a primary database or another service. You can realize a number of benefits by using a central cache.
A key benefit of central caches is to reduce overall application latency. Caches have fundamental design differences than primary databases. Central caches tend to store data in memory without on-disk persistence. This means they’re less safe against data loss than a primary database, but this tradeoff is acceptable because they’re not meant to be a primary store of the data. Further, they typically use a key-value data model that doesn’t allow for flexible query patterns.
A central cache can also be used to reduce the load on your primary database or other downstream system to improve availability and reduce cost. This can be done to avoid specific limits of other systems, such as partition throughput limits in DynamoDB that limit concurrent requests to individual items. Or, a cache can simply help add read scalability to any database. If using a cache to improve read scalability, the tricky part is in avoiding metastable behavior in your caches, where quick changes in cache hit rates can quickly overwhelm your downstream systems.
As we’ll see, data invalidation is easier with a central cache than with other caches. When an application changes data in the primary database, it can also issue a command to evict a corresponding cached item. You can also proactively cache data more easily by inserting records into the cache as they’re written to a database.
Further, central caches are the most dynamic option for storing lots of data. Centralized, in-memory caches are designed to handle hundreds of thousands of requests per second at extremely low latency. They have time-to-live (TTL) configuration to automatically expire items after a period in addition to the explicit invalidation features discussed above. You can store the exact version of the records in your database, or you can store the results of expensive computations like aggregations or combinations of multiple records. This flexibility makes central caches popular for a variety of use cases.
The biggest downsides to a central cache are the added operational burdens and the availability impacts from a central cache. Any piece of infrastructure brings operational burdens, and you must factor that in when adding a central cache to your architect. Further, you need to consider the impact on your upstream datasource and your overall application availability if your cache has an outage. See Meera Jindal’s detailed blog post about key considerations to take into account before adding a central cache.
Removing network latency with local caches
For the second type of cache, let’s move to the other end of the centralization spectrum. Rather than centralizing cached data in a single location, a local cache stores cached data in a decentralized way, as close as possible to the client that needs the data. With a local cache, you can store the needed data directly on the same machine that will need it in the future. By doing so, you eliminate the network request that may be the slowest part of your application workflow.
There are two places you commonly see local caches in your architecture. The first one is to borrow space on your users’ machines. You can cache data in the browser’s local storage, session storage, or other built-in storage mechanisms.
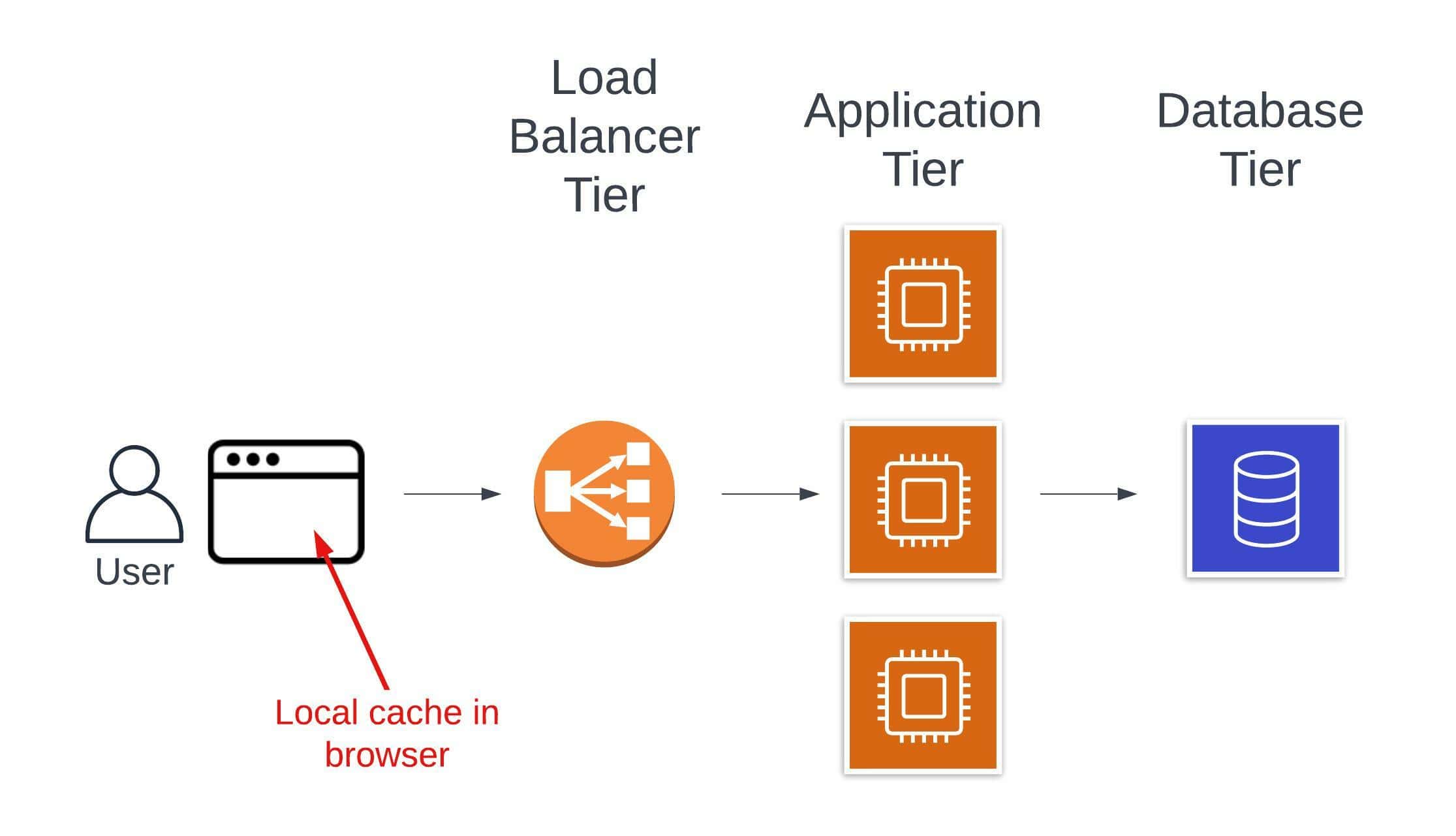
Browser-based storage can be a nice way to store user-specific information, such as their name, username, or group memberships. These may be used across most pages in your application, and storing them locally can reduce the number of network calls for slow-changing data.
A second place to use a local cache is in your own application servers. Each application server can store data in memory or on disk to avoid making network requests to downstream services.
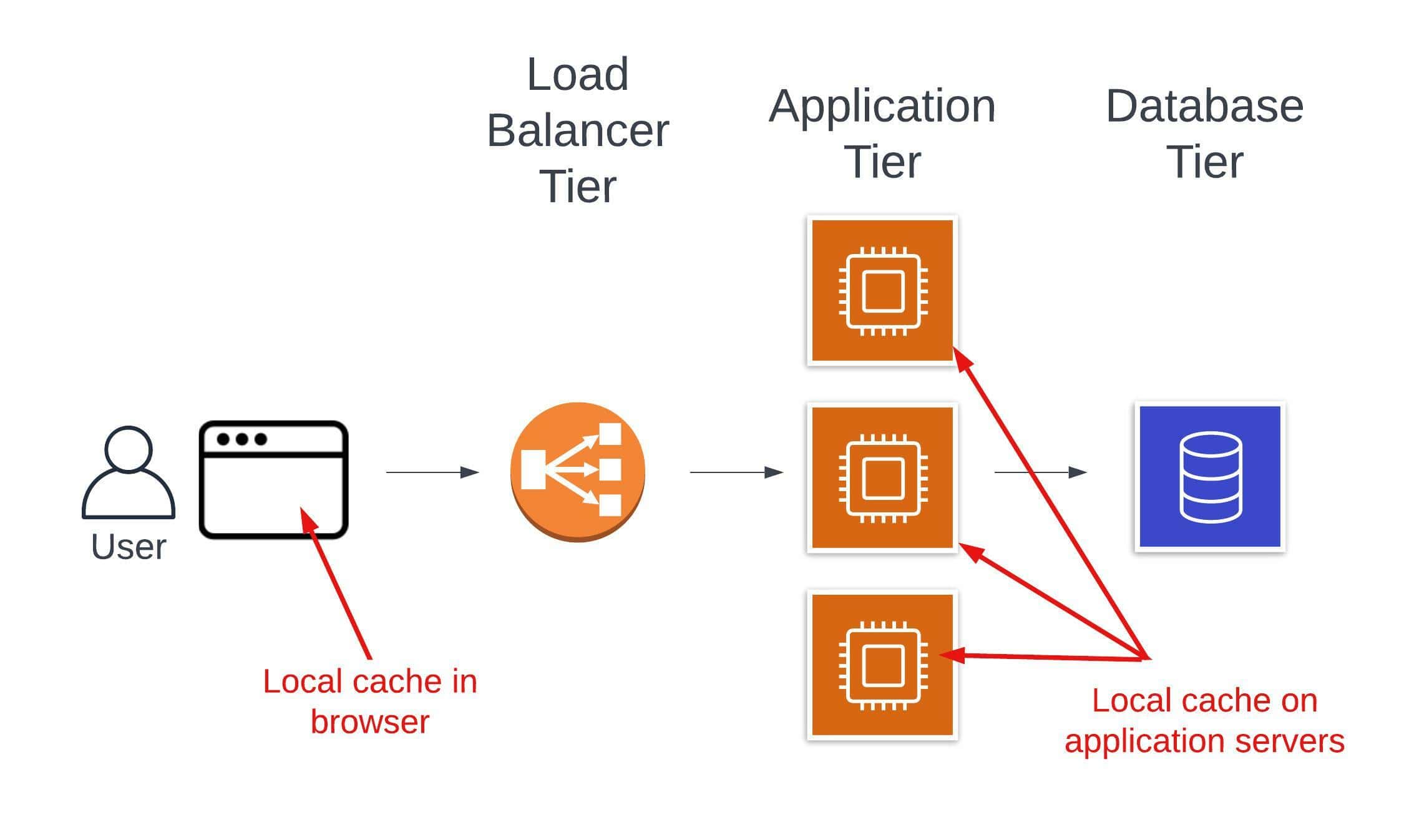
A common example here is to cache slow-moving configuration values or service discovery information. If you’re building with AWS Lambda functions, it’s common to cache secrets and other configuration across function invocations. For a complex distributed system example, you can look at the DynamoDB Paper (2022) to see how DynamoDB’s request routers cache table metadata locally to reduce latency on data processing requests.
Even aside from configuration values, application servers can cache application data to accelerate response times. Popular Java caching libraries like Caffeine or Guava are commonly used for this purpose.
The main benefit of a local cache is that you can remove a network request entirely. Reading a value from memory is orders of magnitude faster than making a network request, even on an established connection. In the right situation, a local cache can be the easiest way to improve your performance.
Another benefit is the ease and cost of adding a local cache. On your application servers, you’ll often have available memory that can hold some cached values. If you’re caching on your users’ browsers, you don’t have to pay for anything at all! In both cases, caching data can be as easy as adding a few lines of code to your existing application.
But local caches aren’t right for all situations. The biggest problem is a function of their decentralization—it can be hard to proactively purge cached values when the underlying data has changed. This task is difficult when you control the underlying caching hardware, and it’s nearly impossible when you’ve distributed cache data to your users’ browsers. Accordingly, you need to think carefully about how often to hold cache data and how to deal with the possibility that your cached data may be stale.
For this reason, local caches work best for slow-changing data, such as user information in the browser, or for frequently requested “hot data” where caching for even brief periods can result in high cache hit rates.
Meeting your users in the middle with edge caches
Local caches are great, but they’re limited in their application. If you have data that changes more frequently or is used by a larger number of users, you will want a bit more centralization of your cache. However, the full centralization you get from a central cache may result in a significant network latency to your globally distributed users.
Edge caches are the midpoint on the centralization spectrum. With an edge cache, you’re storing content at multiple different locations at the edge of your network.
The key point with an edge cache is geographic distribution. We are moving cached data closer to the users that want it. We can’t remove a network request entirely, like we did with a local cache. But we can reduce the distance that a network request has to travel for a response. Rather than forcing clients in Chicago, Berlin, and Mumbai to all visit our primary database in northern Virginia, we can cache this data in locations closer to them.
In our application example, edge caches show up as follows:
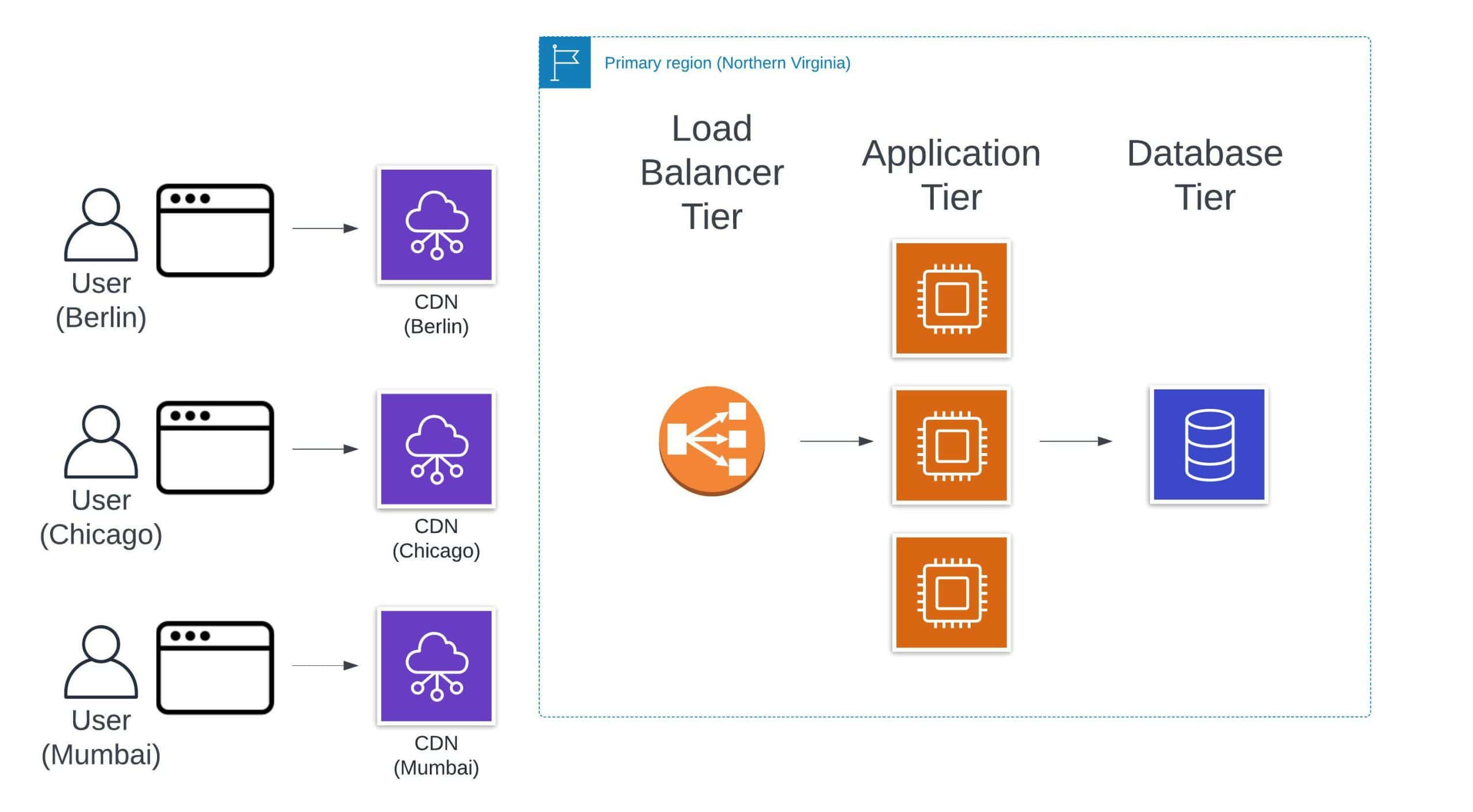
Notice that we needed to expand our diagram to account for users in different locations to demonstrate the value of an edge cache.
The most common type of edge caches are content delivery networks (CDN) which are used to store static files like images (think Snapchat), videos (think Netflix), or JavaScript application bundles (think every single-page application you visit in your browser). Another commonly used edge cache is the domain name system (DNS) that is used to route a website domain to a specific server to handle the request.
User-facing latency is one reason to use an edge cache, but cost and reliability can be another one. For most products, using an edge cache means choosing a CDN provider like Cloudflare, Fastly, or Amazon CloudFront. These are ultra-reliable, reasonably priced systems with many locations around the globe. Requests that hit a CDN can reduce the load on your application servers and allow you to focus on the more difficult aspects of your application.
Because edge caches are more centralized, invalidation is easier than on distributed local caches. However, invalidations on edge caches are not expected to happen at a high rate, and some CDNs even charge money for each invalidation. If you need a more dynamic cache, you’ll want to rely on the popular central cache discussed previously.
Conclusion
Caching is a great way to reduce latency and to alleviate burdens on your application architecture. But not all caches are alike, and the use cases vary. In this post, we looked at caches from the perspective of how centralized they were compared to their end users. In doing so, we examined the three main types of caches—central caches, local caches, and edge caches.
Momento is a cloud-native central cache built for the serverless era. It offers blazing-fast performance, instant provisioning, and a fully managed operational model. It works with all types of application architectures, from VM-based workloads to serverless, function-based APIs.


