The fastest inference is the one that happens right next to the data, with no network hop. But the models worth running rarely fit where the data lives. An 8B model weighs 16 GB in FP16. Even quantized to 4-bit, it barely squeezes onto edge hardware.
PrismML emerged from stealth on March 31, 2026 with the Bonsai family of 1-bit language models: an 8-billion-parameter model in 1.15 GB, generating tokens 8x faster than FP16, scoring competitively against full-precision models. The lowest-latency path to useful inference just got a lot shorter.
Why 1-Bit Has Been the Holy Grail Nobody Could Reach
Binary-weight neural networks have promised dramatic efficiency gains for decades. In practice, they’ve been a graveyard of broken promises. The failure mode is not that 1-bit models can’t produce fluent text. It’s that they become brittle on multi-step reasoning, tool use, and edge cases. A model that fails unpredictably gets ripped out.
Previous near-1-bit approaches also introduced deployment friction that killed adoption: curated calibration sets, custom layer handling, bespoke runtimes. PrismML’s approach, built on proprietary Caltech IP, takes a different path. Instead of ad hoc heuristics applied layer-by-layer, the Bonsai models use a mathematically grounded compression framework designed to preserve model behavior under aggressive quantization.
What End-to-End 1-Bit Actually Means
Some “1-bit models” keep embeddings or attention heads at higher precision. Those escape hatches preserve quality but dilute the efficiency gains. Bonsai 8B applies 1-bit precision everywhere: embeddings, attention projections, MLP projections, and the LM head. One sign bit per weight, one shared FP16 scale per 128 weights. Effective storage: 1.125 bits per weight, yielding a 14.2x compression ratio over FP16.
This matters because LLM inference at small batch sizes is bottlenecked by memory bandwidth, specifically how fast weights move through memory during token generation. One bit per weight directly attacks that dominant bottleneck.
The Numbers That Earn Credibility
PrismML evaluated Bonsai 8B against 11 models in the 6B-9B range using identical infrastructure on H100 GPUs. The average score spans six benchmarks: knowledge (MMLU-Redux), reasoning (MuSR), math (GSM8K), coding (HumanEval+), instruction following (IFEval), and tool calling (BFCLv3):
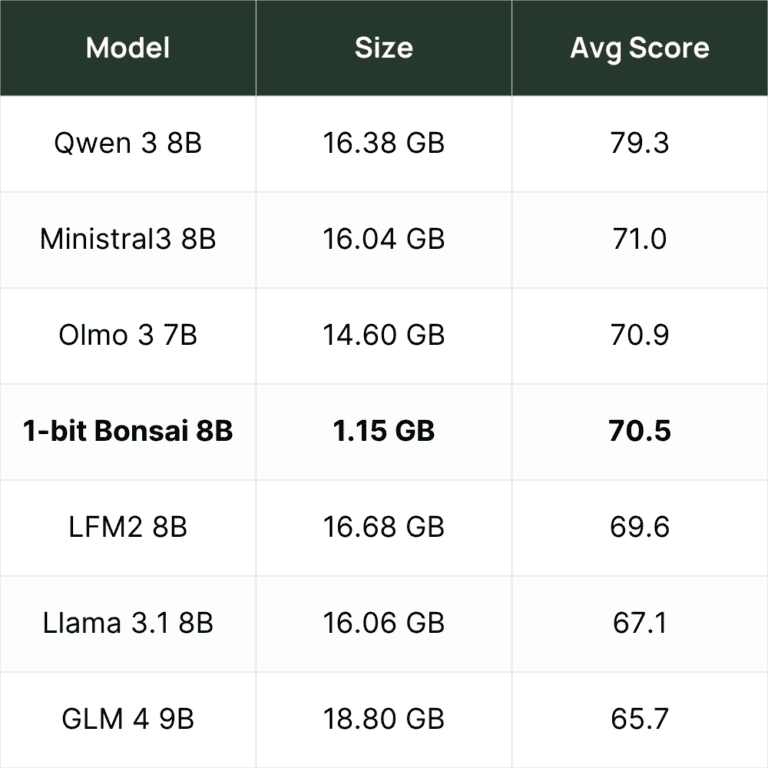
A 1.15 GB model outperforms Llama 3.1 8B and lands within 0.5 points of models 14x its size. On hardware, it generates 131 tok/s on M4 Pro (8.4x faster than FP16), 44 tok/s on iPhone 17 Pro Max, and uses 5.6x less energy per token on Apple Silicon.
The whitepaper introduces “intelligence density,” defined as intelligence per GB and formalized through rate-distortion theory. Bonsai 8B scores 1.060/GB. The next closest conventional model scores 0.549. The Bonsai family doesn’t nudge the efficiency-performance tradeoff. It redefines it.
What This Unlocks
When an 8B model fits in 1.15 GB, deployment constraints change fundamentally. Medical devices and field hardware can run inference locally without cloud roundtrips. Enterprise teams with data residency requirements can deploy on commodity hardware. Datacenter operators fit more models per GPU at lower energy cost. And Bonsai runs on a Samsung S25 Ultra, a device where even a 4-bit 8B model doesn’t fit.
As Bill Jia, VP of Engineering for Core ML/AI at Google, put it: “When advanced models can run on constrained devices, it reshapes system design end to end. Efficiency at the model level compounds across infrastructure.”
PrismML is transparent about limitations. Results are on general-purpose hardware with software and kernel optimization, not native 1-bit silicon. But the methodology is architecture-agnostic, and the roadmap extends beyond transformers. Everything ships under Apache 2.0 with unrestricted commercial use.
The question is no longer whether 1-bit models can work. It’s what you build when they do.
1-bit models shrink the problem. Infrastructure still determines the outcome.
If you’re building low-latency inference systems, talk to Momento.