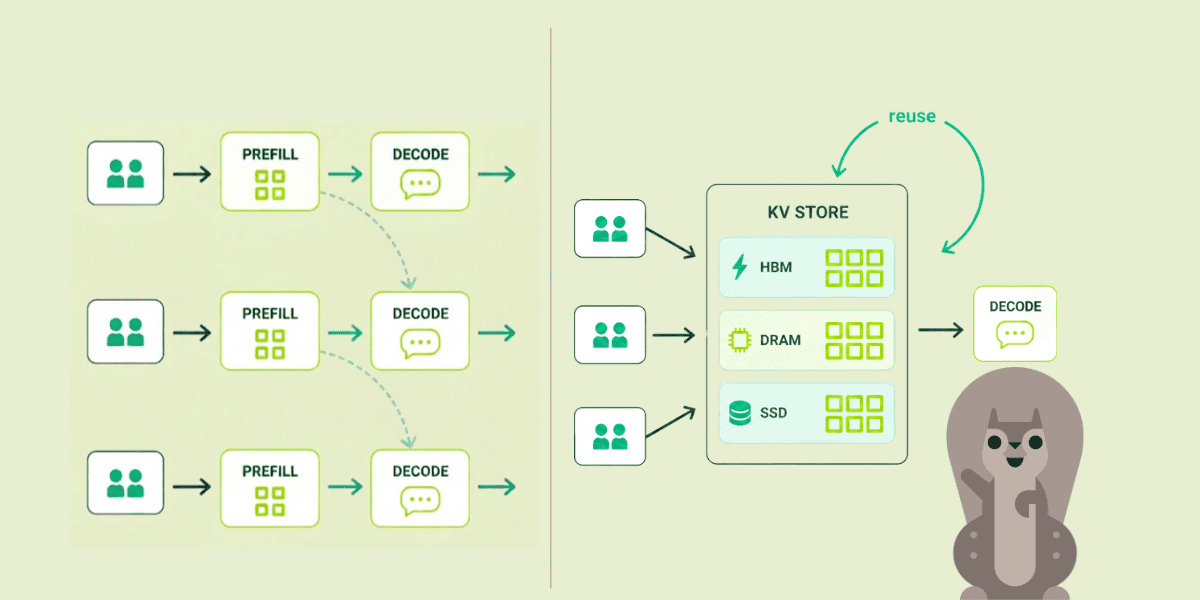
Parts 1 and 2 covered when to disaggregate, how requests find the right GPU, and how the KV cache moves between phases. All of that assumes a data plane that can actually carry the bytes.
Even with smart routing above and orchestration policy in the middle, you still have to move multiple gigabytes between GPUs in milliseconds.
The baseline is unambiguously bad: standard PyTorch serialization tops out below 1 GB/s, or three-plus seconds of dead air for a 3 GB KV cache. The next instinct is NCCL, but NCCL was built for training: collective patterns (AllReduce, AllGather) across a static topology known at startup. Disaggregated inference wants point-to-point transfers between prefill and decode nodes picked per-request by the router.
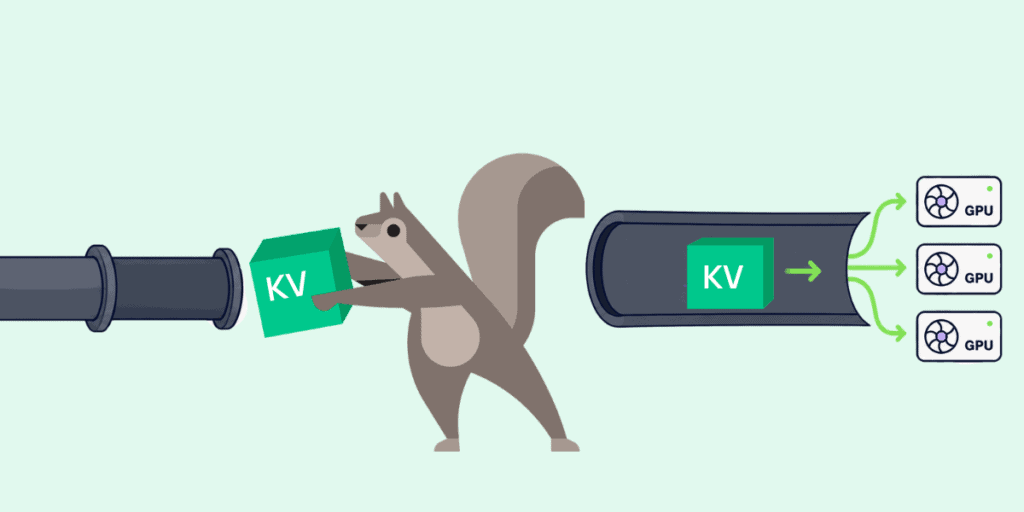
Three purpose-built alternatives have emerged, each solving a different pain point. NIXL (NVIDIA Inference Xfer Library) is the memory-abstraction layer: it exposes HBM, DRAM, NVMe, and S3 as uniform “memory sections” and negotiates the optimal transport underneath (NVLink, GPUDirect Storage, InfiniBand, RoCE) without the application caring which one is used. UCCL (Unified Collective Communication Library) handles P2P transfers without burning GPU compute on data movement (NCCL uses streaming multiprocessors for the transfer itself; UCCL doesn’t), supports both NVIDIA and AMD GPUs, and exposes both NCCL-style collective and explicit read/write APIs, so you get NCCL’s ergonomics without its SM tax, and skip the out-of-band metadata coordination that NIXL’s read/write path requires. Mooncake’s Transfer Engine is the bandwidth specialist, consulting a hardware topology matrix to pick the most proximate NIC per transfer and route around NUMA bottlenecks. It hits 87 GB/s on 4×200 Gbps and up to 190 GB/s on 8×400 Gbps, roughly 2.4× to 4.6× faster than optimized TCP.
How do they actually stack up? The UCCL team benchmarked all four on a pair of 8-GPU AMD MI300X nodes wired with 400 Gbps NICs (50 GB/s per link). On the 256KB–1MB messages typical of KV transfers, NIXL and UCCL P2P both saturate the link; NCCL/RCCL runs 30–50% slower: the SM tax. The gap closes at 10MB+ messages, where SM overhead amortizes. The surprise: Mooncake TE couldn’t saturate even a single 50 GB/s link at 100MB messages, a tension with its impressive multi-NIC aggregate numbers that the UCCL authors flagged but couldn’t fully explain.
Which one you pick depends on your actual pain: NIXL for heterogeneous memory tiers, UCCL for GPU-efficient P2P transfers across vendors, Mooncake TE for raw aggregate bandwidth when you can parallelize across many NICs.
Where This Is All Going
Disaggregation doesn’t eliminate the bottleneck in LLM serving. It moves it. The monolithic era of “buy a bigger GPU” is turning into a distributed-systems era where your scheduling sophistication, the policies governing your cache tiers, and the quality of your data plane matter more than which accelerator you bought. Cache-aware routing, content-hashed tiered storage, RDMA transports: none of these are ML concepts. They’re the same primitives distributed caching platforms have been refining for a decade.
The clearest production signal so far: in March, AWS and Cerebras announced a Bedrock service that runs prefill on AWS Trainium and decode on the Cerebras CS-3 (different vendor, different chip, different phase), stitched together over Elastic Fabric Adapter. The architectural pattern this series has been describing is shipping as a managed product, not a research demo. And when the chips on either side of the wire are built by different companies, the data plane connecting them stops being an implementation detail and becomes the product.
LLM serving infrastructure is becoming a globally-addressable, tiered cache network with a compute layer bolted on top. The teams that ship the best user experiences won’t be the ones with the most H100s. They’ll be the ones who treat their inference pipeline like a cache first and a model-execution engine second, with all the operational discipline that implies. At Momento we’ve watched that discipline emerge in caching systems the hard way, over years of chasing tail latency, congestion, and hit-rate math. It’s surprisingly familiar watching it happen again, one layer up.