Hien Luu
Hien Luu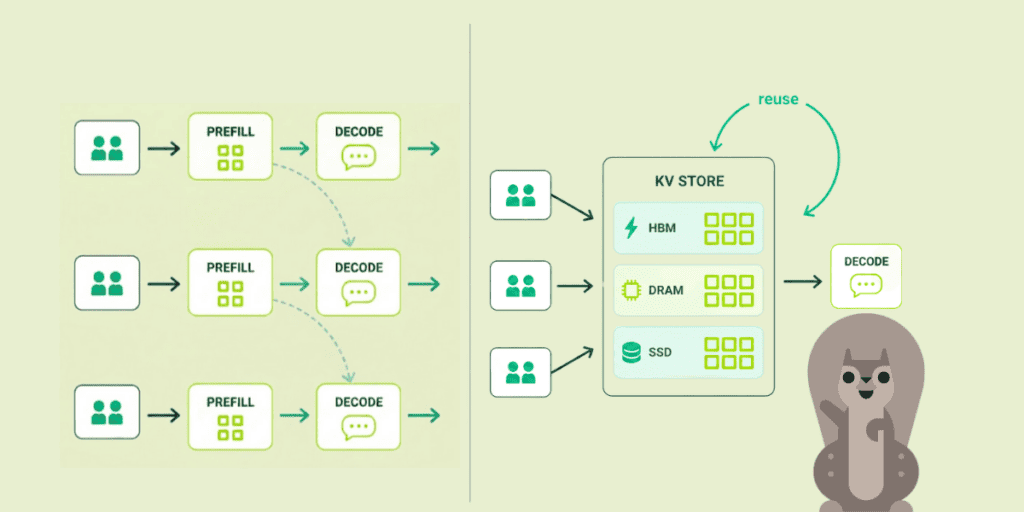
In Part 1 we covered when disaggregation is worth the trouble and how requests find the right GPU. Once a request is routed, the next problem is moving the KV cache between prefill and decode without stalling the decode stream.
A fast transport moves bytes from prefill to decode. It doesn’t tell you when to start sending, where the cache lives between hops, or how to reuse it across requests. Those are orchestration questions, and they’re where most of the practical performance lives.
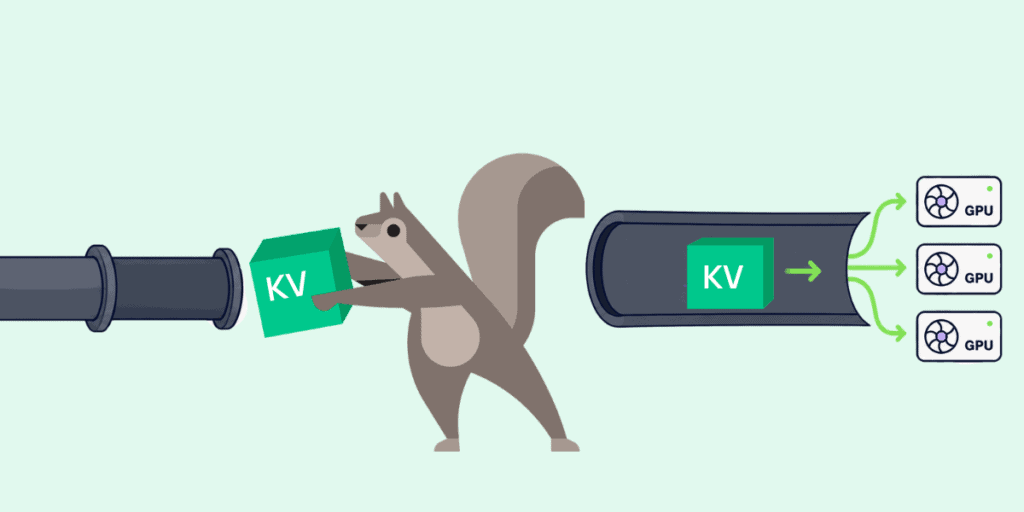
The first move is layer-wise streaming. Mooncake calls it “Layer-wise Prefill”: as soon as prefill finishes computing the KV cache for layer 0, that layer’s blocks start streaming to the decode node while the prefill GPU is still computing layer N. The transfer hides behind compute that would otherwise stall, dropping visible transfer latency significantly on long prompts.
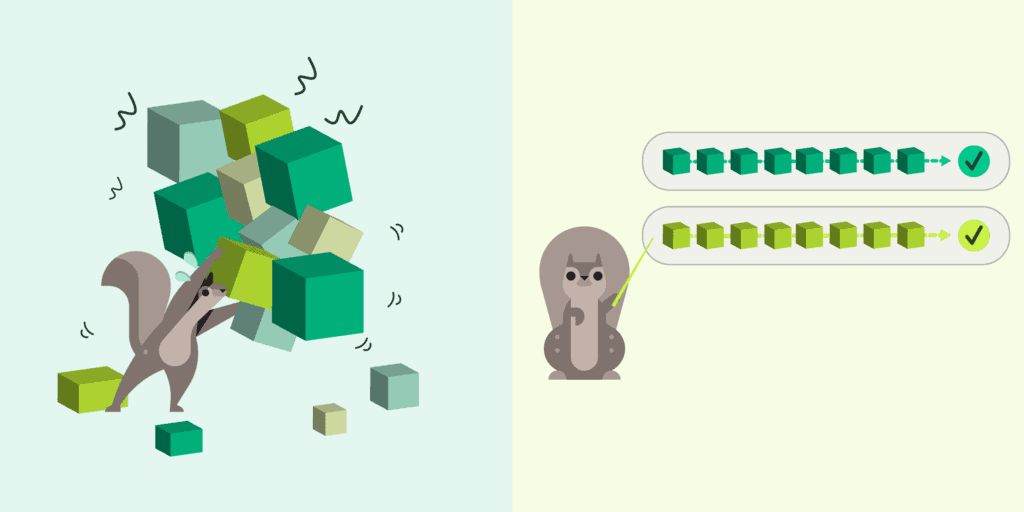
The second move is treating the KV cache as a tiered store, with hot blocks in HBM, warm blocks in CPU DRAM, and cold blocks on networked SSDs. Mooncake Store keys blocks by content hash, evicts LRU, and replicates hot blocks across nodes so a popular system prompt doesn’t bottleneck on one location. DeepSeek’s Fire-Flyer File System (3FS) takes it further, using NVMe SSDs over RDMA to break the dependency on node-local DRAM. A 180-node 3FS cluster delivers 6.6 TiB/s aggregate read throughput and 40 GiB/s per client for KV lookups, fast enough that “the cache lives on disk” becomes viable rather than a fallback.
The third move is choosing the handoff itself. DistServe pulls: decode fetches on demand, using prefill memory as a queuing buffer. Mooncake’s Conductor pushes: prefill streams each layer to decode and frees its memory. 3FS-backed designs use shared storage. Push minimizes decode-side latency at the cost of memory pressure on the prefill pool. Pull keeps memory pressure where the work is queued. Shared storage decouples both, at the cost of a network hop.
Perplexity’s KV Messenger shows what this looks like in production. Built on RDMA via libfabric, it polls a counter that’s incremented after the output projection of each layer. Because that projection reduces across tensor-parallel ranks, the counter implicitly synchronizes them, letting the system track per-layer completion without breaking CUDA graphs. The moment the counter ticks, RDMA writes start flying. The decoder doesn’t even need an explicit completion signal: it counts incoming RDMA operations against the expected total. Serving DeepSeek-R1, mixed prefill-decode struggled to exceed 50 TPS due to prefill interruptions; after disaggregating, a single prefiller kept three decoders saturated at 90+ TPS for a 100ms TTFT cost.
The payoff is reuse. Most tokens in a typical prompt have been processed before, by someone: a system prompt shared across all users of an app, earlier turns of an active conversation, the boilerplate of a few-shot template. When the KV store is content-hashed and tiered across HBM, DRAM, and SSD, those tokens don’t have to be prefilled again. The prefill work that would have been redone on every turn is instead amortized across every request that shares a prefix.
Combine that with the layer-wise streaming above, and the whole shape of the workload changes. This is how Moonshot AI runs Kimi at 100+ billion tokens per day, handling 115% more requests than non-disaggregated baselines on the same A800 hardware: orchestration turns what would be a compute problem into a cache problem.
Up next
Layer-wise streaming, tiered storage, and clever handoff semantics all assume the data plane underneath can actually deliver multiple gigabytes between GPUs in milliseconds. Picking the right transport for that, and understanding why the obvious choices fall short, is its own problem.
Next in Part 3: Why Your Networking Stack Might Not Be Ready.