トニー・バルデラマ
トニー・バルデラマ カワジャ・シャムス
カワジャ・シャムスA decade ago, Snowflake demonstrated the value of separating storage from compute. It’s hard to overstate how much that single architectural choice transformed data warehousing and analytics. Decoupling systems with fundamentally different behaviors allows them to scale independently on dedicated hardware, with distinct optimizations and separate costs.
That pattern wasn’t unique to data warehousing. Since then, it has played out across event streaming, search, and every kind of database. Each time, decoupling storage from compute unlocks new efficiency and new architectures. Teams stop over-provisioning one resource to get more of another. Workloads that used to be impossible become routine.
Inference is on the cusp of this same transformation. The KV cache, which holds attention state produced during prefill and consumed during decode, plays a central role as the shared storage layer. As inference frameworks start to handle KV cache less like internal scratchpad and more like a durable platform resource, we are watching the same architectural shift unfold.
This piece walks through that evolution in three parts. First, how vLLM and the surrounding ecosystem are starting to decouple storage from compute. Second, the bandwidth wall that governs how far we can push that separation today. And third, what becomes possible once we break through the barrier.
Decoupling Storage and Compute
Prefill and decode are fundamentally different workloads. Prefill ingests context to produce the KV cache. It is compute-bound, hammering the GPU’s arithmetic units. Decode generates one token at a time, reading the entire KV cache on every step. It is memory-bandwidth-bound. Running them on the same GPU causes each phase to stall periodically, blocked by cross-phase resource contention.
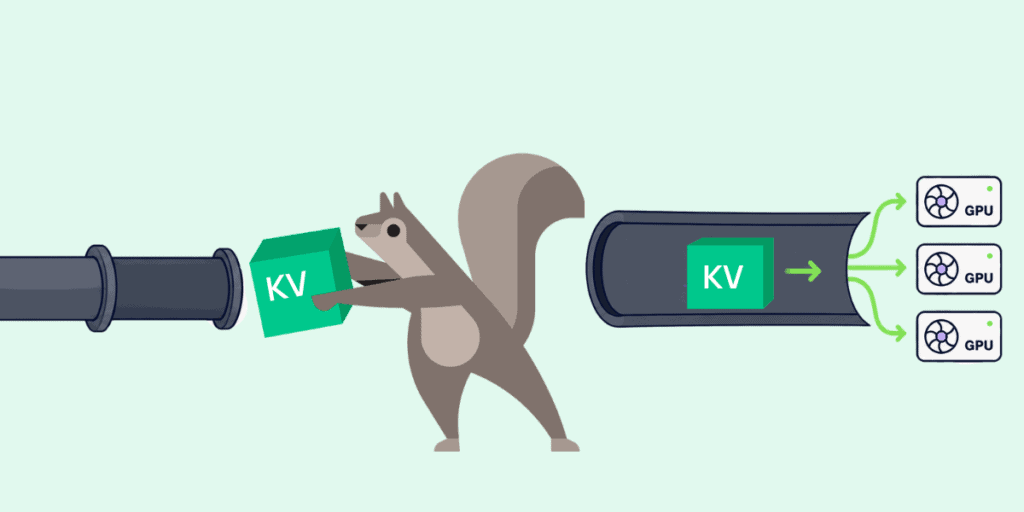
Once you separate the two phases, something interesting happens. You end up with a write path (prefill, producing KV), a read or query path (decode, consuming KV), with shared storage in between. In fact, vLLM implements prefill-decode disaggregation as a low-latency read-after-write sequence. The router stages a write to a prefill node, waits for that data to become available, and then queries for output from a decode node.
Separating prefill from decode in this way elevates the KV cache from transient internal state into a durable, shared artifact. Once it is shared, it can be stored, moved, reused, and managed like any other piece of valuable data.
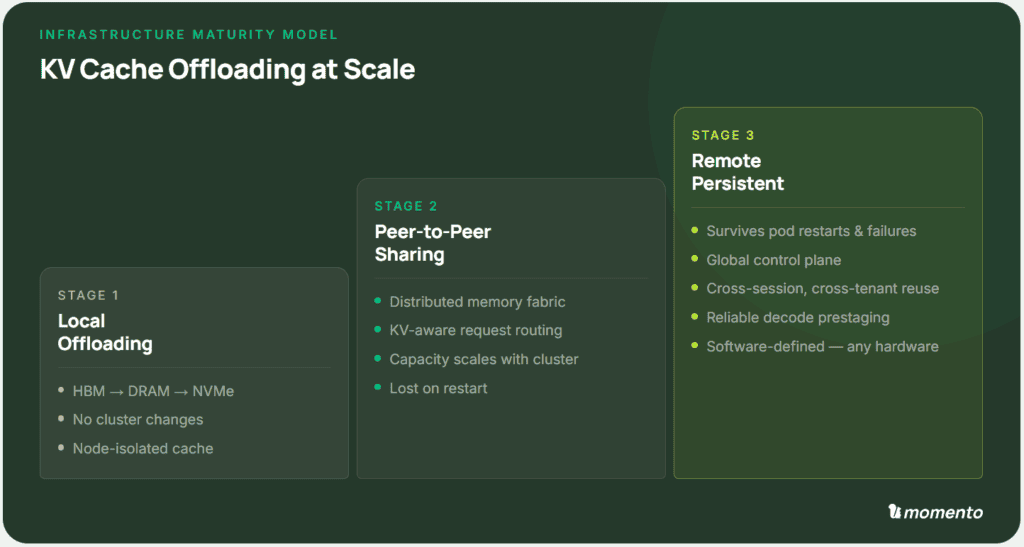
A simple maturity model captures where teams are on this journey today.
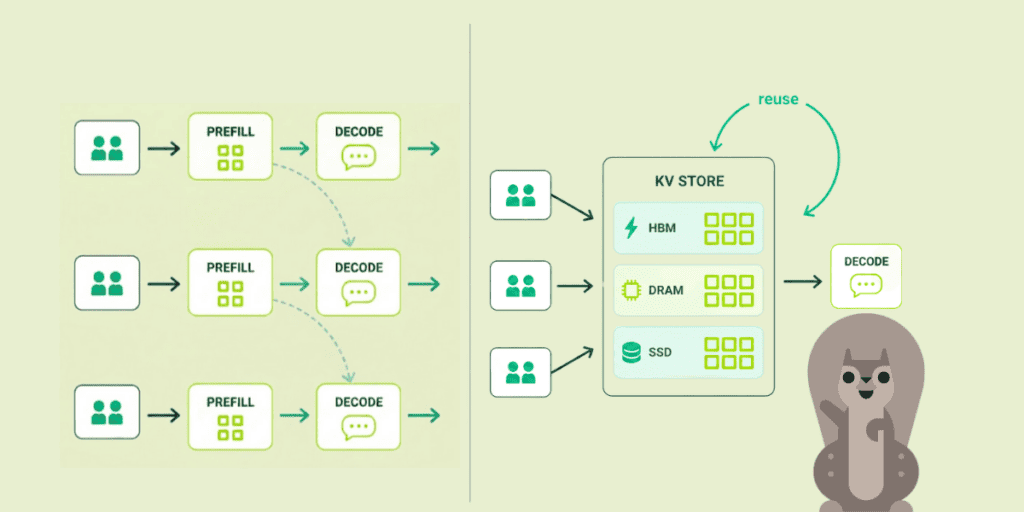
Stage 1 — Local Offloading. Local offloading is built into every modern inference engine. KV cache spills from GPU memory to CPU RAM and then to local NVMe. Most teams already have some form of this running. Capacity grows by orders of magnitude with no cluster changes. The catch is that each node’s cache is invisible to its peers, so the same context gets recomputed across machines.
Stage 2 — Peer-to-Peer Sharing. Once a node can fetch KV blocks from any other node, the cluster’s aggregate memory becomes a single shared pool. Capacity scales with cluster size, and cross-node reuse nearly eliminates redundant prefill. However, the cache lives in RAM and local disks, so a cluster restart erases it. Many hyperscalers are focused on shipping robust production deployments of prefill-decode disaggregation, a subtype of peer-to-peer sharing.
Stage 3 — Remote Persistent Storage. Ultimately, the KV cache will be fully extracted into a separate durable system that survives pod restarts, node failures, and cluster-wide upgrades. Cross-session and cross-user reuse become standard practice. The architecture is more complex, but the clear service boundary opens the door to more advanced features and optimizations.
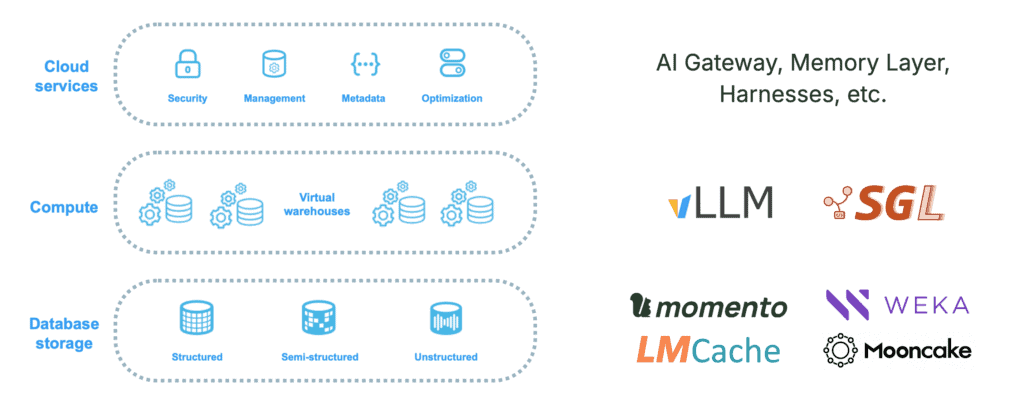
Mapped back onto Snowflake, the architecture looks familiar. Compute is the inference engine, led by vLLM and sglang. Storage is the tiered KV cache, with a growing field of vendors competing on performance, cost, and simplicity. Services are everything that builds on top, like AI gateways, memory layers, agent harnesses, and orchestration. Three layers, scaling independently, each free to evolve at its own pace.
This is the Snowflake moment, in which storage — the KV cache — has evolved into a first-class platform resource.
The Bandwidth Wall
Theory is easy. Implementation is where the constraints show up. And the hard constraint that determines how far you can separate compute from storage is bandwidth.
During prefill, the inference engine produces a volume of attention state proportional to model and context size. To keep the pipeline flowing smoothly, this KV throughput must fit into available network bandwidth, which depends on the underlying hardware link: HBM at 1+ TB/s, NVLink or InfiniBand at 100+ GB/s, and Ethernet at 1 to 10 GB/s. Achieving viable throughput has been a key factor in the co-evolution of new inference architectures and novel hardware.
If you’re building a datacenter, then you’ll need to choose among a variety of exotic networking and storage options. This greatly increases your options for system architecture, at the cost of significant capital investment. The rest of us get whatever our cloud provider offers. Typically that means NVLink within a node, InfiniBand within a cluster, and Ethernet for everything else, often without locality control.
Fortunately, commodity networking is more than good enough, if you know what you’re doing. High-performance distributed systems are a well-understood space, although they do require expert design and careful operation.
Process architecture matters, like running outside Python’s GIL. Zero-copy data paths, TCP tuning, pipelining, compression all compound to fully saturate data links. Tiered storage is the other half of the picture: layering Valkey or Redis with RAM and NVMe in front of object storage smooths out the long-tail latencies that plague pure object storage. Finally, routing and orchestration are key to fully utilizing any distributed system.
This is exactly the problem space we solve at Momento. Our data fabric was built for hyperscale workloads where every microsecond matters: from AAA games moving session state at scale, to live-streaming infrastructure for peak events like the Super Bowl.
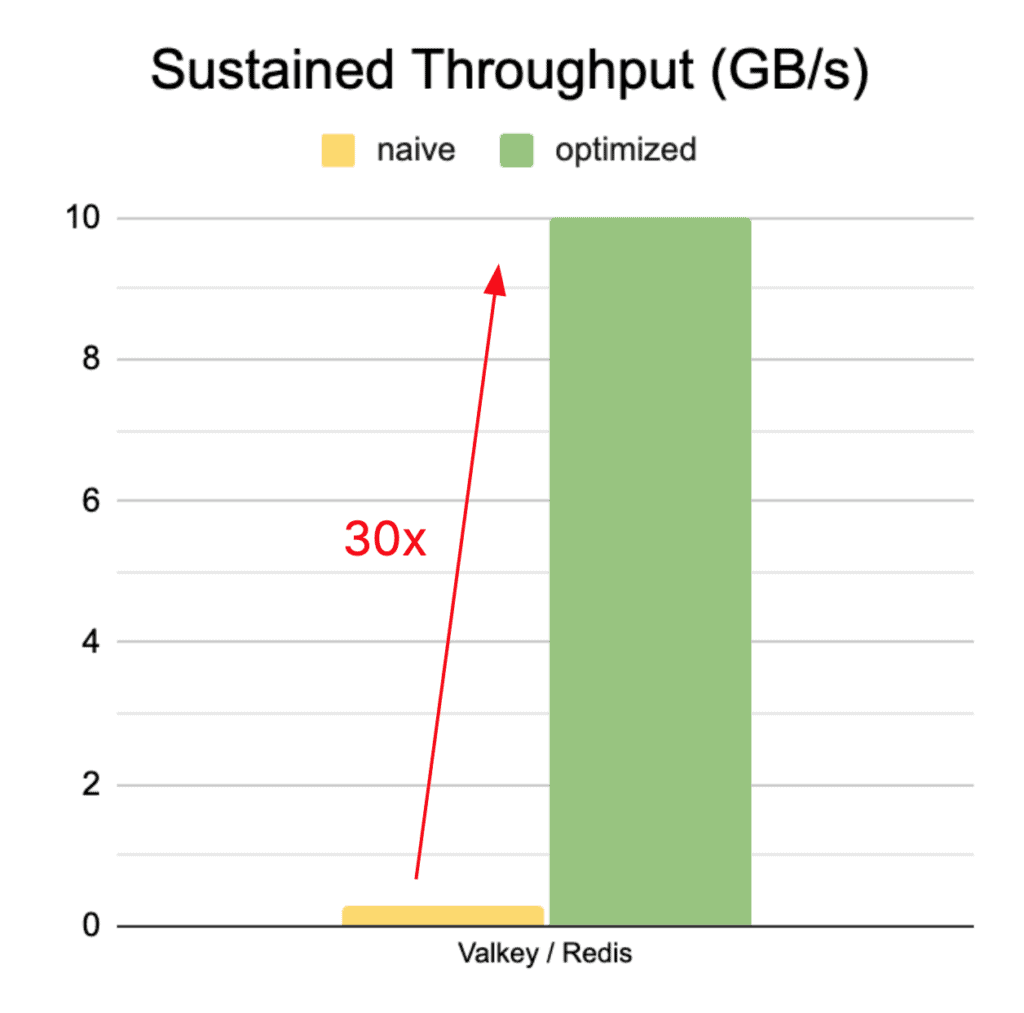
To make the challenge concrete, we tested a standard Redis-based KV cache against our hybrid storage that tightly integrates Valkey, S3, and a hyperscale router. The naive Redis approach delivers just 0.3 GB/s, a small fraction of available bandwidth. With a well-designed architecture and careful tuning, throughput on Momento jumped 30× to saturate a 10 GB/s Ethernet link.
Ultimately, coalescing multiple saturated links allows standard Ethernet to compete directly with exotic data fabrics, while being dramatically cheaper, more flexible, and more portable. As bandwidth and storage get smarter, it just makes sense to split out the KV cache into a distinct, commoditized service.
What Lies Ahead
Elevating attention state to shared, durable storage unlocks exciting, new possibilities for inference. Here are three trends to watch for in the next year:
Intelligence density is the most important Pareto frontier. KV throughput directly impacts the performance of distributed architectures. Fortunately, researchers continue to pack more intelligence into fewer bytes. Every week brings incredible advances in quantization, compression, and attention architectures. Deepseek’s latest v4 model even fits the state for 1 million tokens into just 10 GB! Intelligence density is the race to watch in 2026.
Productionized Prefill-as-a-Service. Researchers at Moonshot, the team behind Kimi and Mooncake, recently [pushed prefill-decode disaggregation](https://arxiv.org/abs/2604.15039) to the logical extreme. They achieved production-viable throughput with prefill and decode running in different datacenters on commodity GPUs. This definitively demonstrates that a distinct, remote storage layer works. The challenge that lies ahead is robust, production-ready deployment.
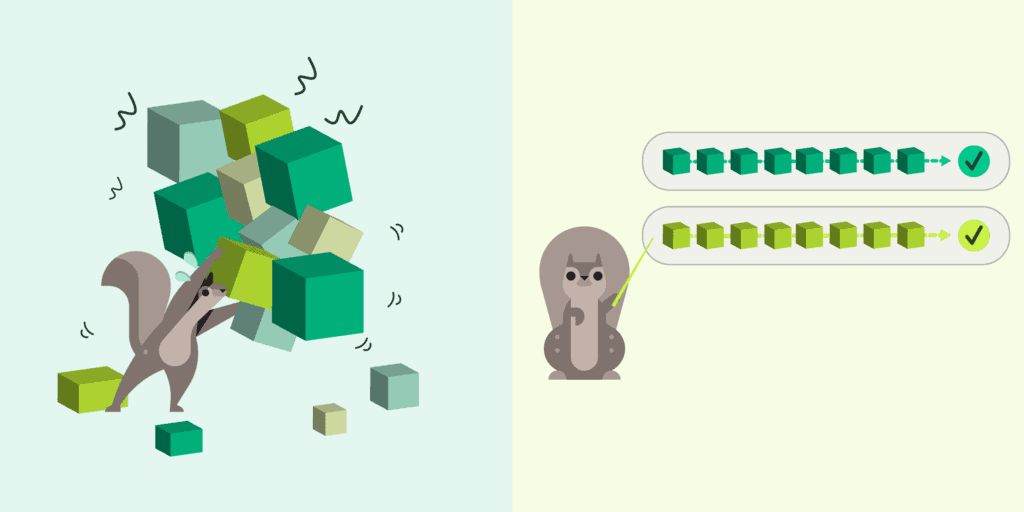
Composable attention fragments. Flexible reuse of KV cache blocks is the key to an efficient storage layer. This is critical for agentic workloads that constantly compact, reorder, and update context while running multiple models on diverse hardware. Look for innovations like CacheBlend (context reordering) and ICaRus (multi-model reuse) to enable fully-composable attention.
Together, these trends will enable inference systems to treat attention state like a warehouse data table that’s pre-computed, durably stored, joined at query time, and delivered in whatever configuration the application needs.
Context as a First-Class Asset
Ultimately, the Snowflake moment didn’t just separate storage and compute. That architectural shift reframed transient, discarded outputs as a durable, valuable asset in its own right.
The same shift is happening to context inside inference systems:
- Agentic workloads, with input-to-output ratios of 100:1, make context the dominant cost.
- Multi-turn, multi-session, and multi-user reuse makes context valuable to preserve.
- Rising intelligence density makes context cheap to move and store.
- Novel techniques demonstrate that context can be composed and distributed in real time.
The question is no longer how to compute prefill faster. It is how to treat context like a first-class asset — stored, transformed, composed, and never computed twice.