Prefill builds the KV cache. Decode reads it back, over and over, to generate each token. One is compute-bound. The other is memory-bandwidth-bound. In many deployments, even when operators split them onto separate GPUs, both chips still come from the same vendor.
An analysis from Gimlet Labs, Splitting LLM inference across different hardware platforms, evaluates a multivendor B200:Gaudi 3 setup shows about 3x TCO benefit on a prefill-heavy workload and up to 4x on a decode-heavy workload relative to a disaggregated H100:H100 baseline. In those modeled cases, it also beats an all-NVIDIA B200:B200 disaggregated setup.
Those gains do not come from minor tuning. They come from matching different chips to different phases of inference.
The setup
Two phases, two profiles:
- Prefill ingests the prompt and builds the KV cache. Compute-bound. Rewards high FLOPS.
- Decode generates tokens by repeatedly reading that cache. Memory-bandwidth-bound. Rewards high GB/s.
Run both on the same GPU and they interfere: prefill pins the compute units, decode starves on memory bandwidth. The silicon is never fully busy on either.
Prior work (Splitwise, DistServe) already showed 2-7x throughput gains from splitting the phases onto separate GPUs. The new contribution is to ask whether the two pools should also be allowed to come from different vendors.
The Pareto frontier they land on:
- Prefill winner: NVIDIA B200. In this analysis, it is the strongest option on cost-effective FP8 compute capacity.
- Decode: Three chips sit on the Pareto frontier for cost-effective memory bandwidth: Intel Gaudi 3, AMD MI300X, and NVIDIA B200. Gaudi 3 looks best if roughly 3000-4000 Gbps of total bandwidth per device is sufficient.
B200 prefill + Gaudi 3 decode lands at about 3x TCO benefit on their prefill-heavy workload and up to 4x on their decode-heavy workload. In the decode-heavy case, the all-B200 disaggregated configuration is closer to 2.5x. For these modeled scenarios, the heterogeneous option beats the homogeneous one.
Why 4x is bigger than it sounds
If results like these hold in production, the impact is larger than a routine efficiency gain.
Agents get more interesting. Many agentic workflows are decode-heavy: lots of short generations across tool calls. Cheaper decode would directly improve that cost profile.
Long context gets easier to justify. A task like “summarize this 100-page PDF” is more prefill-heavy, so lower prefill cost improves the economics of generous context windows.
The control point may shift. If heterogeneous inference becomes practical, more value accrues to the runtime and scheduling layer that decides where each phase runs.
The broader takeaway is that cost per token under a latency target is becoming a primary systems constraint. A large decode-side cost reduction would materially change the economics of serving inference at scale.
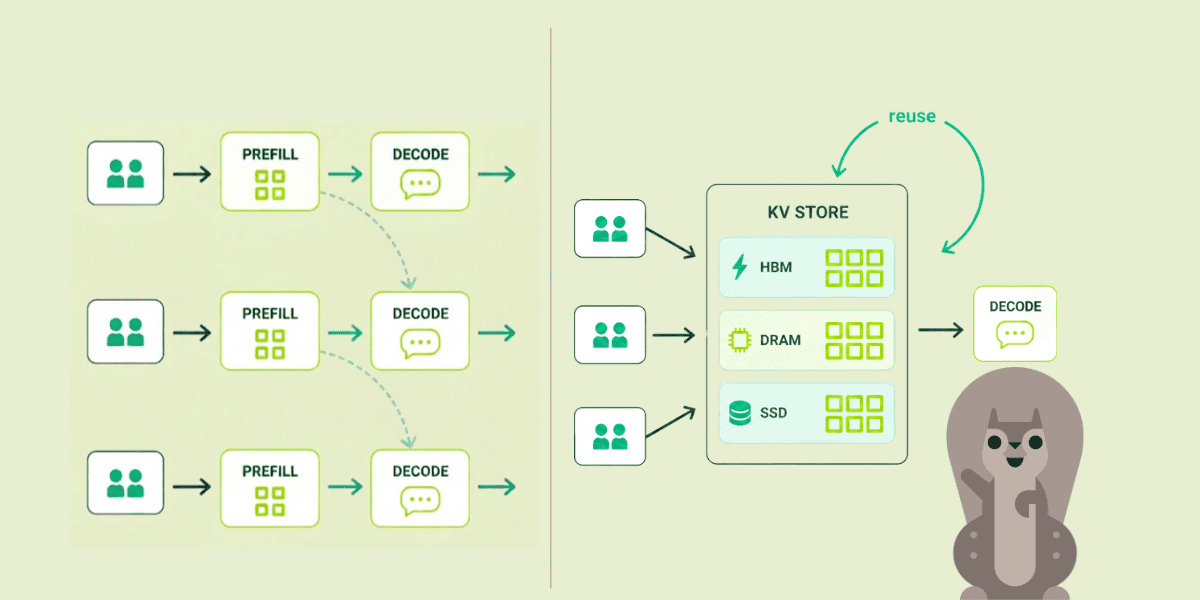
KV cache is becoming a networking primitive
The obvious objection to cross-vendor inference: moving the KV cache between chips has to be slow.
The numbers say no. Pipelined layer-by-layer transfer adds 5–10 ms. Translating NVIDIA’s cache format to Intel’s takes 20–50 microseconds. Rounding error against a multi-hundred-ms budget.
The deeper implication is more architectural than numerical: the KV cache starts to look less like an in-GPU detail and more like a system-level object that has to be moved, translated, and scheduled. That does not by itself prove every caching pattern is practical, but it does make them easier to imagine.
Whoever owns that data plane format translation, placement, eviction, and pipelined transfer could end up controlling an important layer of the inference stack.
The part nobody’s ready for: the software
The physics works. The economics work. The runtime doesn’t.
vLLM and llm-d support multivendor deployment, but support is still uneven and that disaggregating the same workload across multivendor accelerator types remains challenging today. That appears to be one of the main blockers to production use.
Which is also where a moat could form. Cross-vendor fleets mean multiple driver stacks, firmware cadences, and operational failure modes. This is not a flip-a-switch migration.
The teams that ship a real cross-vendor scheduler, with KV cache movement handled cleanly behind a unified serving layer, could capture a meaningful cost advantage. The exact size of that advantage will depend on how closely real workloads resemble the modeled ones in this analysis.
Agentic workloads break the binary
The prefill/decode split works for chat and RAG. Each is one LLM call: ingest the prompt (prefill), stream the response (decode). The split matches the shape of the workload. For agentic workflows, it’s not enough.
Agentic workloads do not have one prefill and one decode. They have many short generations interleaved with tool calls, retrieval, and often other model stages. Different steps can want different hardware profiles, which makes a simple “prefill pool” plus “decode pool” abstraction feel limited.
The analysis gestures at this with dynamic partitioning across heterogeneous pools.
Static hardware pools may be a transitional architecture. The logical direction is schedulers that route work by workload profile across heterogeneous pools, rather than by vendor name.
My read: that scheduler does not fully exist yet, and building it may become one of the more important infrastructure problems in AI serving.
What to do with this
If you operate inference at scale: it is worth re-testing the all-NVIDIA default against heterogeneous options. The modeled workloads suggest the premium can be substantial.
If you build inference software: an important opportunity is the cross-vendor scheduler and KV-cache data plane that makes heterogeneity operable for teams without a large platform org.
If you build products on top of inference: lower inference cost on some workload shapes could make previously marginal features worth revisiting.
The bundle held because unbundling was hard. This analysis suggests the hardware economics can support a different design. What still looks hardest is the software.
If you’re working through this problem, we’d love to compare notes.