
This post is part of a series detailing how Momento thinks about our developer experience. Getting started with our serverless cache is shockingly simple, but that is only half of the story.
We believe a delightful user experience includes writing and running code that interacts with your cache, and making our client libraries shockingly simple takes deliberate effort. To say it another way: our cache clients are a first-class concern.
For an overview on our philosophy about our developer experience, check out the first post in the series: Shockingly simple: Cache clients that do the hard work for you. We followed up with a deep dive into the tuning work we did for our JavaScript client. Today, we’ll do a similar dive into the performance of our Python cache client.
This post is for those of you who want to geek out with me about p999 latencies and gRPC channels. For everyone else, if you’re just interested in getting up and running with Momento…you’re good to go! Check out our Getting Started guide to get up and running with a free serverless cache in minutes, or head to our GitHub org to download the Momento client for your favorite language!
Previously, on Shockingly Simple
The exploration of the performance of the Python cache client is similar in many ways to the work we did for the JavaScript (Node.js) client. Here are some relevant highlights from the previous blog post:
- Momento clients are built using gRPC, a high-performance framework for remote procedure calls, created by Google.
- As such, a lot of our tuning efforts will be focused on gRPC configuration.
- Like Node.js, the default Python runtime only runs user code on a single CPU core, so CPU is likely to become our first and primary performance bottleneck.
- The more concurrent requests executed against our client, the more CPU is required to handle all of their network callbacks.
- Thus, it’s important for us to identify the maximum number of concurrent requests we can handle before a CPU bottleneck starts to impact our client-side latencies.
- gRPC “channels” are connections between the client and the server. Most gRPC servers are configured to limit the maximum number of concurrent requests per channel to 100.
- Therefore, when executing more than 100 concurrent requests, it can sometimes help to create more than one gRPC channel between the client and server.
Tuning the Momento Python gRPC Client
As we did for the javascript tuning, we started by investigating performance with 5,000 concurrent requests executed from a laptop (dev-style environment with higher latencies than prod). Knowing the server will only allow 100 concurrent streams per channel, this means that with a single gRPC channel, we will always have 4,900 requests stuck in a backlog. Therefore, we tested various different numbers of channels to see how performance was impacted. In JavaScript, we got a very significant performance improvement by increasing to 5 channels, so we expected to see the same with Python. Here are the results:
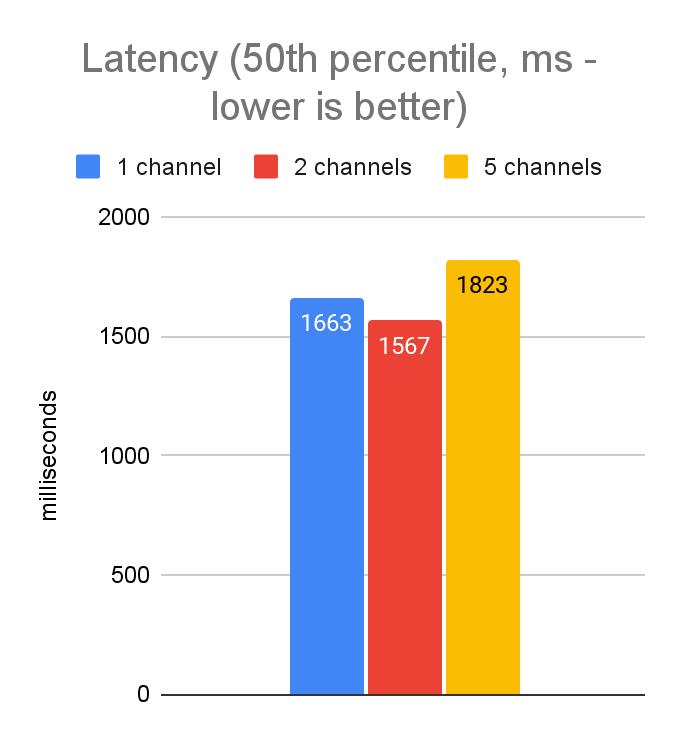
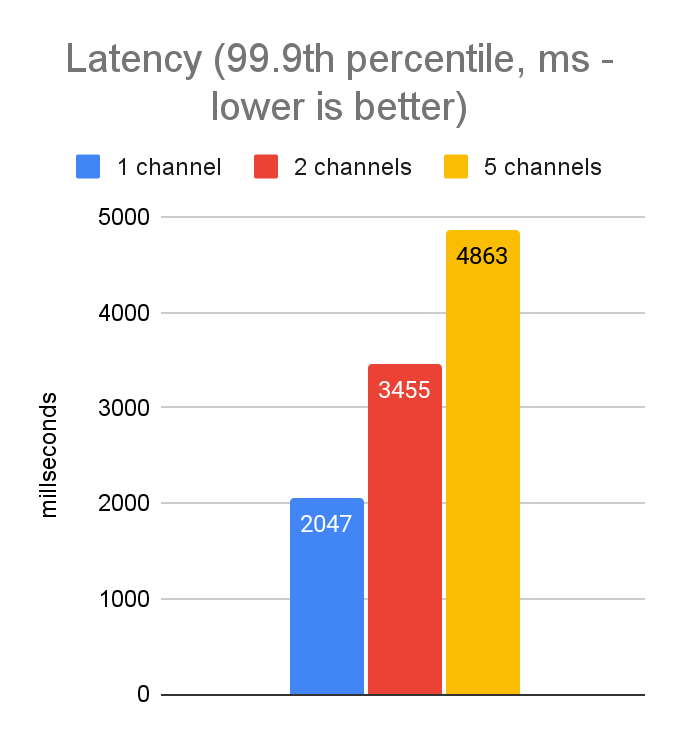
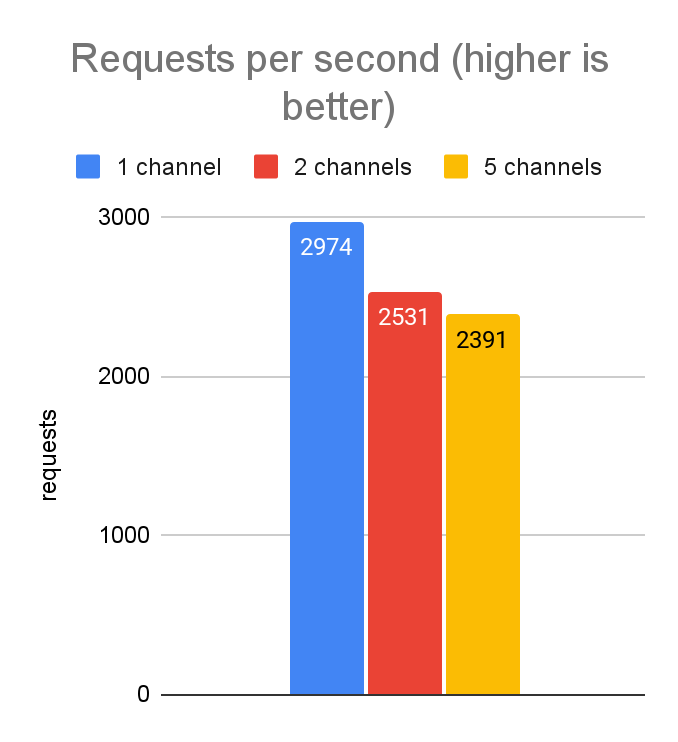
Unlike in our JavaScript tuning, these results show no improvement by adding additional channels. In fact, the variability of the results and the p999 latencies are actually better when using only a single channel. This is most likely an artifact of the differences in the gRPC libraries from language to language—e.g. the Python implementation is largely written in C++, whereas the grpc-js library is written purely in JavaScript. Thus, they have different capabilities with respect to low-level access to network resources.
(You may also recall from our JavaScript tuning we found a setting called grpc.use_local_subchannel_pool, and it made a major impact on performance when using multiple channels. In the Python gRPC implementation, this setting does not move the needle.)
Now we know a single channel is sufficient. However, these latencies are still unacceptably high, so we need to continue tuning.
Varying the number of concurrent requests
Now we know we will get the best results with a single gRPC channel, we can move on to investigating the ideal value for the maximum number of concurrent requests to allow. In our JavaScript tuning we found the best values to achieve a good balance between latency and throughput were in the 50-100 range, so we’re expecting the same in Python. Here are the results:
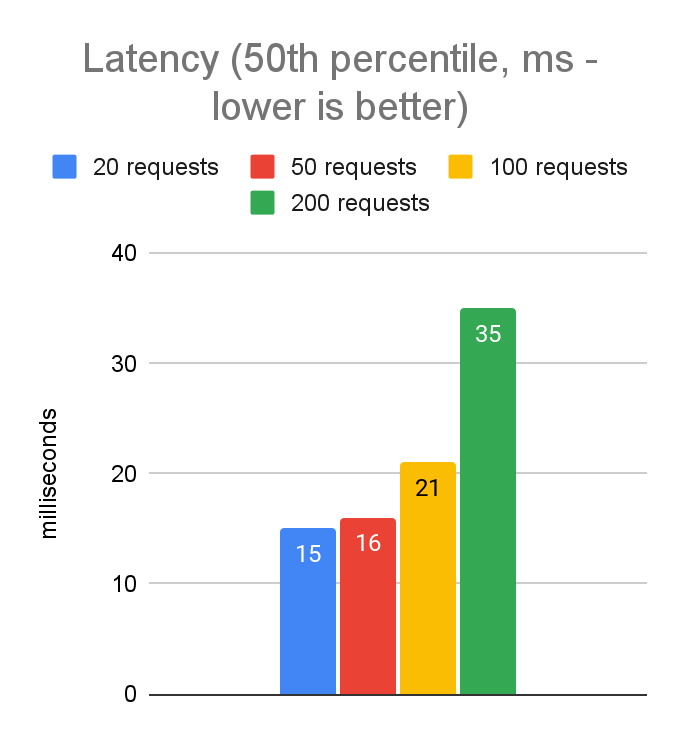
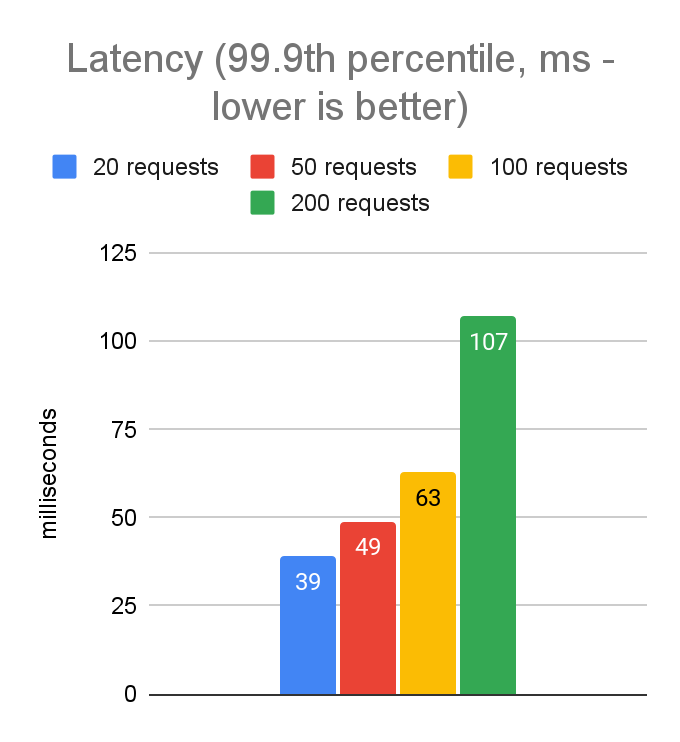
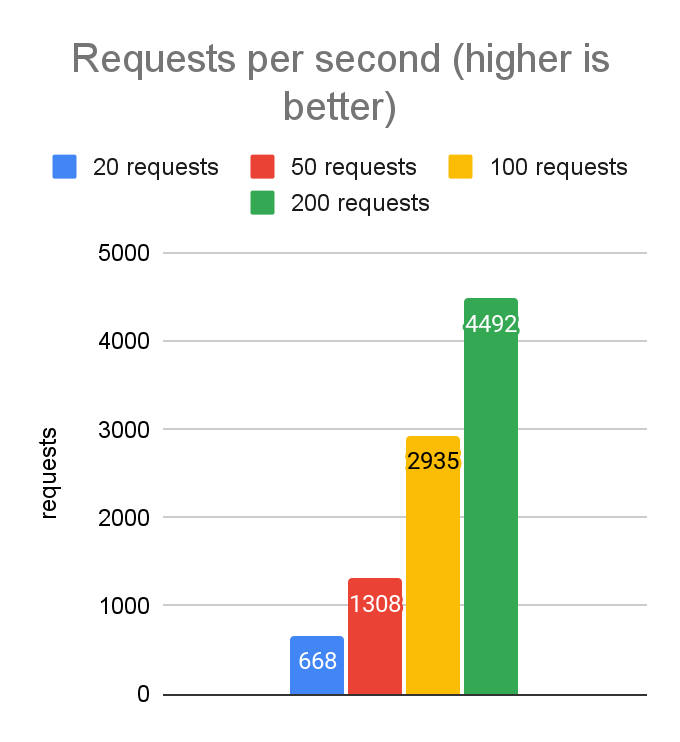
As expected, the best values are in the 50-100 range. Latencies increase slightly when moving from 50 to 100, but throughput increases quite a bit, so 100 looks like a good starting point for further testing.
Moving from the laptop to the cloud
Now we have an idea of how performance looks in a dev environment, let’s test things out from an AWS EC2 instance running in the same region as the cache service. This should eliminate most of the network latency, so we expect the client-side latency numbers to look much closer to the server-side numbers. (We use a c6i.4xlarge instance type because we have observed more consistent network performance in this class than with smaller instances.)
Tuning goals
We’ll use the same latency targets we used when tuning the JavaScript client:
- Client-side p999 latency of 20ms: This is a reasonable target for applications which are caching data that is extremely expensive to compute (e.g. a big JOIN query in a complex relational database schema) and when the application’s own latency requirements are lenient.
- Client-side p999 latency of 5ms: This is a better target for an application whose own latency requirements are absolutely critical.
asyncio and uvloop
Since we were tuning for maximum performance on a single Python process and we knew the bottleneck is CPU, we were looking for opportunities to reduce CPU usage. A lot of the overhead in our load generator program is driven through Python’s asyncio library, for which there are different engines available. Thus far in this post. we have been using the default engine.
We decided to experiment with the uvloop engine, which moves some of the work from Python into native code; specifically, it uses the same libuv C library that is used by the node.js event loop. Let’s take a look at how performance was impacted. We’ll compare the performance of 50 and 100 concurrent requests, with and without uvloop:
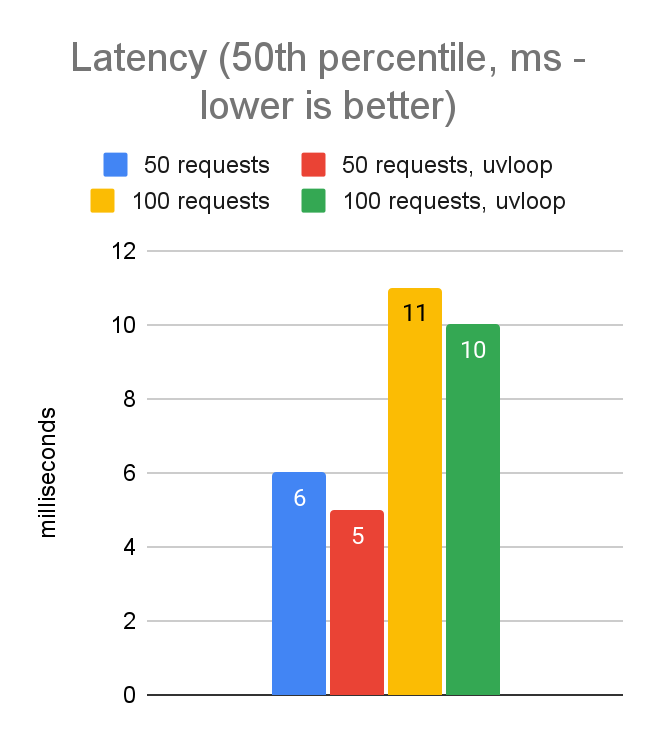
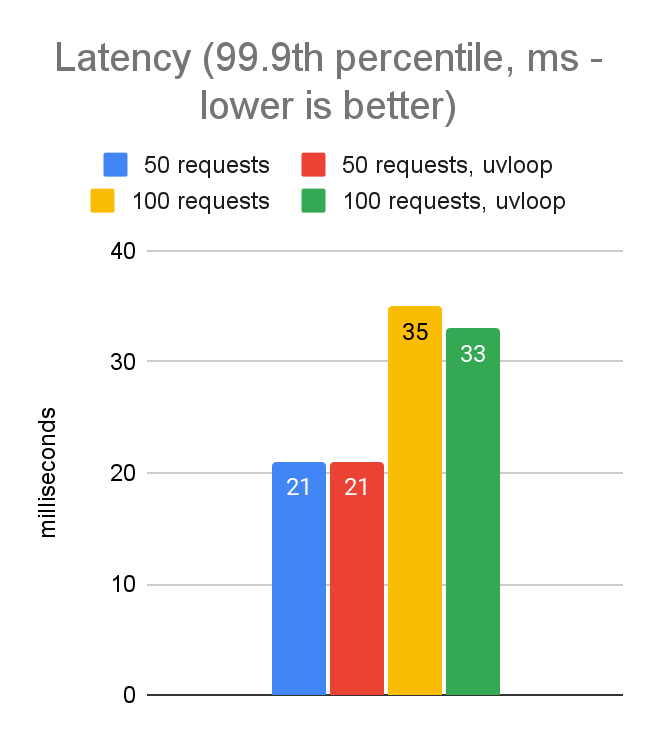
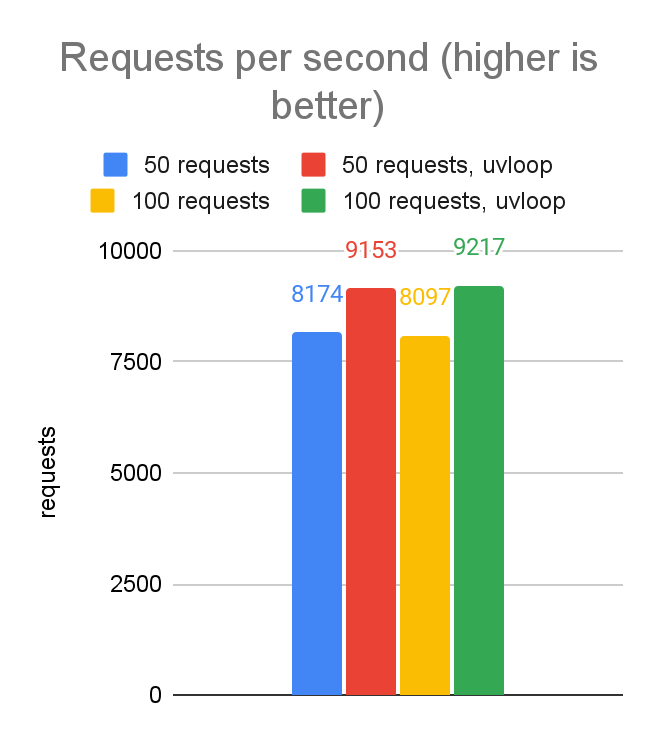
As seen in the data above, switching to uvloop gives us in the ballpark of a 10% performance improvement. Not bad for a 2-line code change! And now our performance numbers are pretty much on par with where we landed in the JavaScript client.
Revisiting the number of concurrent requests
Here are the data for client-side latency and throughput when running on the EC2 instance using uvloop with varying numbers of concurrent requests:
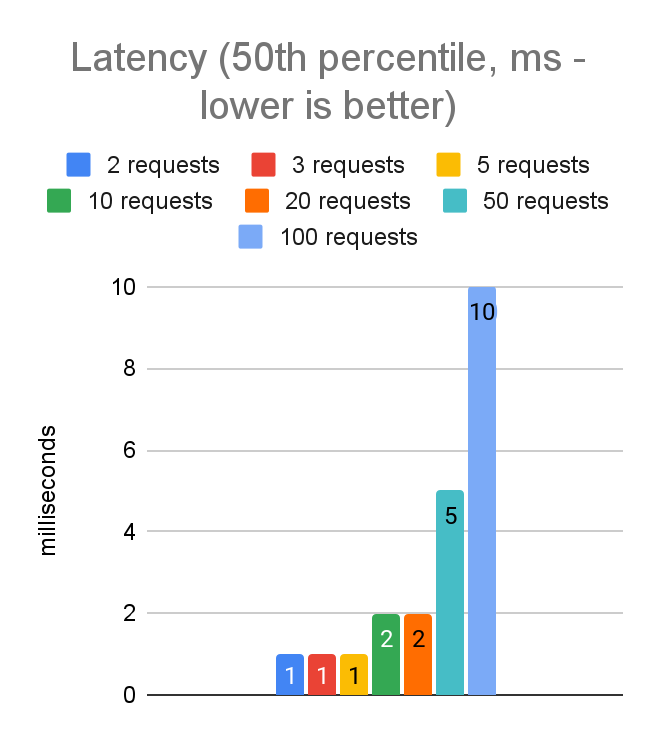
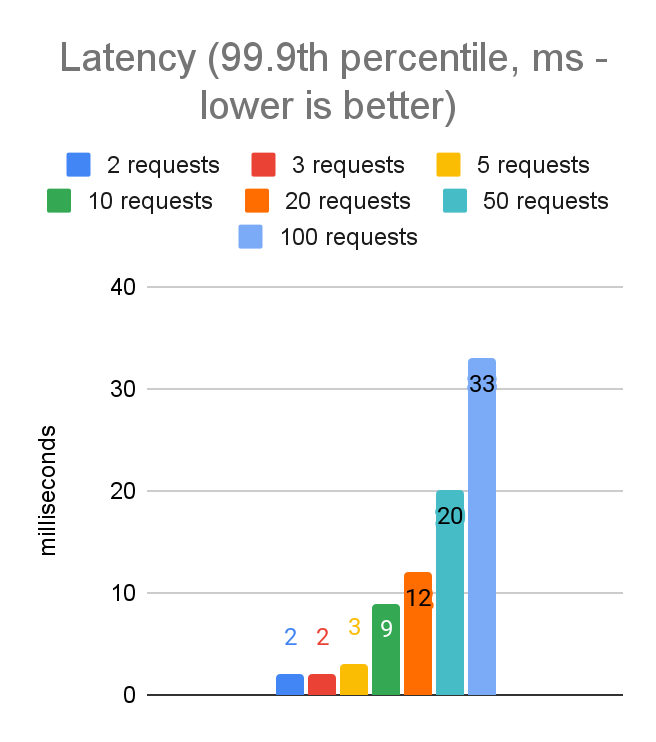
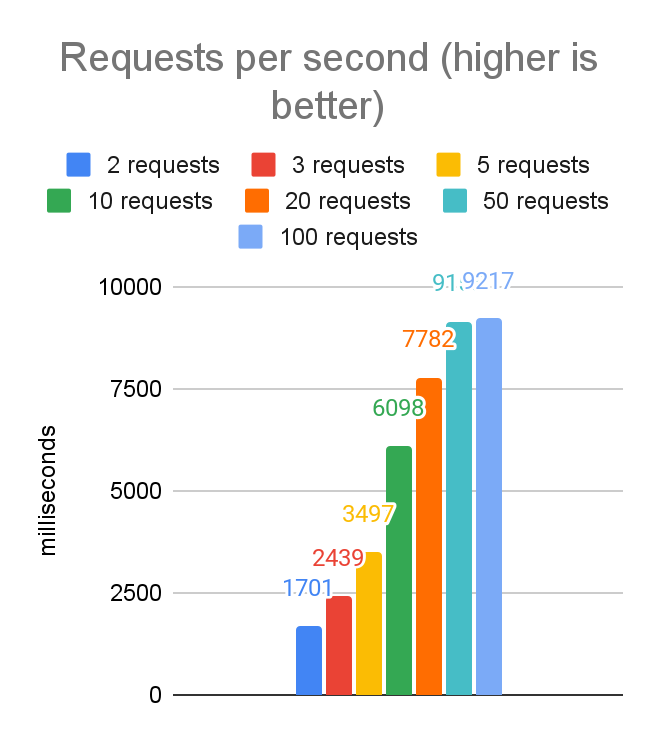
From these charts we can see we are able to hit our first latency target (p999 latency less than 20ms) with 50 concurrent requests.
For an application whose latency requirements are more stringent, we are able to hit our target of a p999 latency of less than 5ms with 5 concurrent requests. This does reduce the throughput from 9100 requests per second to about 3500, but the tradeoff will be the right choice for certain applications.
There are also options for increasing overall throughput on a machine by running multiple instances of your Python process. For today, we have focused on optimizing a single Python process, but in a future post we may do another deep dive to explore the performance tradeoffs that come into play with those options.
Conclusion
With these findings, we now have a solid basis for defining pre-built configurations for dev and prod environments. We used these to initialize the default settings in the Momento Python client, and in an upcoming release, you’ll be able to choose between the pre-built configurations like Configurations.Laptop, Configurations.InRegion, and Configurations.InRegion.LowLatency and ProdEnvironmentConfig.Of course, you’ll also be able to manually tune the settings as you see fit, but our goal is to cover the 90% cases so you don’t have to!
Next up: C#
The next post in this series will cover our tuning work for the C# client. This will be the first where we cover a language that supports using multiple CPU cores out of the box. This should provide some interesting twists, since CPU won’t become a bottleneck as quickly as it has in the first two explorations. Stay tuned!
Or…don’t! This is all just for fun and insight, and our position is that you shouldn’t actually need to worry about this stuff with Momento. We want to take care of it for you—so you can focus on the things unique to your business. Go check out our console, and see how easy it is to create a cache for free in just minutes.


