This post is the fourth entry in a series detailing how Momento thinks about our developer experience. Getting started with our serverless cache is shockingly simple, but that is only half of the story.
We believe a delightful user experience includes writing and running code that interacts with your cache, and making our client libraries shockingly simple takes deliberate effort. To say it another way: our cache clients are a first-class concern.
For an overview on our philosophy about our developer experience, check out the first post in the series: Shockingly simple: Cache clients that do the hard work for you. You can also check out the other two previous posts, where we dig into the tuning nuts-and-bolts for our JavaScript and Python clients. In this installment we’ll explore what we learned while tuning our .NET cache client.
If you’re up for some nerdery related to gRPC clients and identifying performance bottlenecks, read on! However… if you are MORE interested in just getting up and running with a free serverless cache in mere minutes… you should feel free to forego my nerdery and get straight to the fun part. Visit our Getting Started guide and we’ll have you set up with a free cache in a jiffy. Then head to our GitHub org to download the Momento client for your favorite language!
Last time, on Shockingly Simple
In case you haven’t read the previous posts in this series, here’s a recap of season 1:
- Momento clients are built using gRPC, a high-performance framework for remote procedure calls, created by Google.
- Therefore, gRPC client tuning makes up a big chunk of the work for tuning each Momento client.
- In languages like Python and JavaScript, where the default runtime environment only runs user code on a single CPU core, CPU is often the first bottleneck we hit.
- Managing the number of concurrent requests in flight at one time on a single client node has proven to be one of the best ways to maximize throughput and avoid CPU thrashing.
- In JavaScript, creating more than one gRPC channel between the client and the server helps improve throughput and better utilize CPU.
- In Python, where the gRPC layer is written in C, there are usually no meaningful performance benefits to using more than one gRPC channel.
Tuning the Momento .NET cache client
As we did in the tuning work for the previous clients, we start off with the super naive approach of just spamming way too many concurrent requests by spawning a bunch of C# async Tasks in a loop.
Why? Because it’s fun!
Well, more seriously: because it shows us the performance in a pathological case and it gives us some important clues as to what resources will become our first bottlenecks under load. This was an especially interesting experiment since C# is the first language we’ve tested that can effectively leverage all of the machine’s CPU cores out of the box. While in Python and JavaScript we were expecting to hit a CPU bottleneck fairly quickly, this time around we were much less certain what to expect.
One bit of knowledge that we took into this experiment is that the Momento server will only allow 100 concurrent streams per channel. Therefore, since we only instantiated a single gRPC channel in our client code, I was expecting the same behavior we saw in Python and JavaScript, which was that 4,900 of our 5,000 concurrent requests would be blocked until we started experimenting with multiple gRPC channels.
This led to our first interesting observation!
Not all gRPC libraries are created equal
When I am running these tuning experiments I often use the lsof command to monitor how many connections are open between the client and the server. With the Python and JavaScript clients, I always observed a single connection open for each gRPC channel that I created.
This is not the case in C#! The .NET gRPC library is a good deal more sophisticated in how it manages connections to the server.
As soon as your client has more concurrent requests in flight than can be multiplexed over a single connection to the server, it will transparently open another connection and start sending some of the requests over that connection.
So, if I ran my code in a configuration that produced 100 or fewer concurrent requests, I would observe exactly one connection open via lsof. But if I increased it to 101 concurrent requests, lsof would show a second connection magically opened for me by the .NET gRPC library! At 201 requests, a third connection appeared, at 301 requests a fourth connection appeared, and so on.
Wow! I had to carefully manage and test the number of channels in Python and JavaScript, but here was the .NET library doing all the work for me. Neat!
This is great! Or is it?
This behavior is really helpful… to a point. It’s wonderful not to have to manage creating and destroying those connections explicitly, and especially wonderful not to have to worry about how to route requests to one of the open connections. But there is a down side…
This implementation meant that in my initial pathological code where I was bombarding the client with 5,000 concurrent requests at all time, the gRPC library was opening as many as 50 connections to the server. There is a point after which having so many connections open and so many requests on the wire yields diminishing returns, and the client’s overhead of dealing with all of those channels actually reduces performance and throughput.
Not to mention that it forces the server to deal with a bunch of extra connections that aren’t providing any value. One client with 50 connections open isn’t a big deal, but if the ideal number of connections is 5 or fewer, and every client is potentially opening 10 times that many, that just bogs everything down for everyone, for no good reason.
So the next step was to figure out how many connections (and concurrent requests) gave the best performance.
Laptop environment: Varying the number of concurrent requests
Here are some graphs showing the performance we got from running tests on a laptop with varying numbers of concurrent requests.
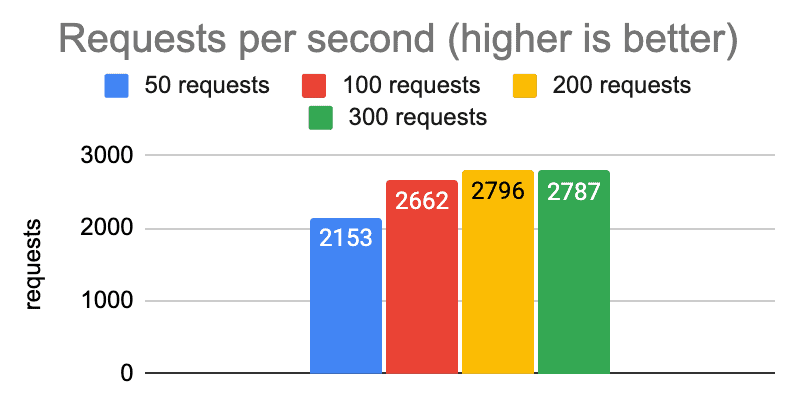
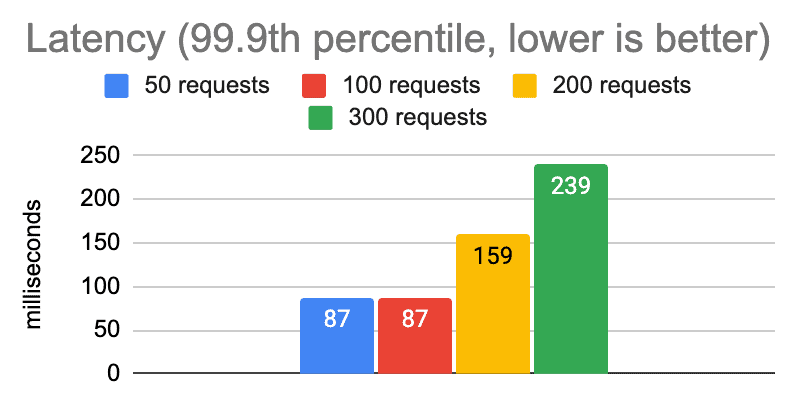
It’s clear that we get diminishing returns well before the 5,000 mark, and likewise that there is no good reason to ever allow the client to create so many connections in this environment.
To address that, we added some code to the Momento .NET cache client that would allow us to configure an internal limit for the number of concurrent requests in flight. We did this via .NET’s usual async Task API, so it’s invisible to you as a user of the Momento client, but it gives us the ability to cap the maximum number of connections that the .NET gRPC library creates to the server.
Even with that code change in place, there’s nothing we can do to prevent user code from issuing 5,000 concurrent requests against the Momento client; we can limit how many are on the wire at once, but not how many async calls are issued. Interestingly enough, running the test code again with 5,000 concurrent async calls, but with the Momento SDK limiting us to 100 concurrent requests on the wire at once, we still get much more consistent throughput and latency numbers due to less context switching. So capping the number of connections is a win all around.
Observations on throughput and resource utilization
As expected, we’re able to drive much more traffic through the Momento client in a single C# process than we were in Python or JavaScript, because we’re able to use all of the CPU cores and we don’t hit the single-CPU bottleneck. In fact, on my laptop, network I/O became the bottleneck before we even got close to maxing out CPU. This is not terribly surprising; on my laptop I was able to achieve 11,000 requests per second of throughput while only using about 20% of the CPU. With a single Python or JavaScript process we would peak around 6,000 (though we could obviously go higher than that with multiple processes).
Moving from the laptop to the cloud: Tuning goals
Alright, the laptop environment is interesting, but now let’s move to a more realistic production environment: an EC2 instance running in the same region as the Momento service. This should eliminate most of the network latency, so we expect the client-side latency numbers to look much closer to the server-side numbers. (We use a c6i.4xlarge instance type because we have observed more consistent network performance in this class than with smaller instances.)
We’ll start by establishing some latency goals for our tuning:
- Client-side p999 latency of 20ms: This is a reasonable target for applications which are caching data that is extremely expensive to compute (e.g. a big JOIN query in a complex relational database schema) and when the application’s own latency requirements are lenient.
- Client-side p999 latency of 5ms: This is a better target for an application whose own latency requirements are absolutely critical.
Cloud environment: Revisiting the number of concurrent requests
Here are some graphs showing the performance of the client in the cloud environment given various numbers of concurrent requests:
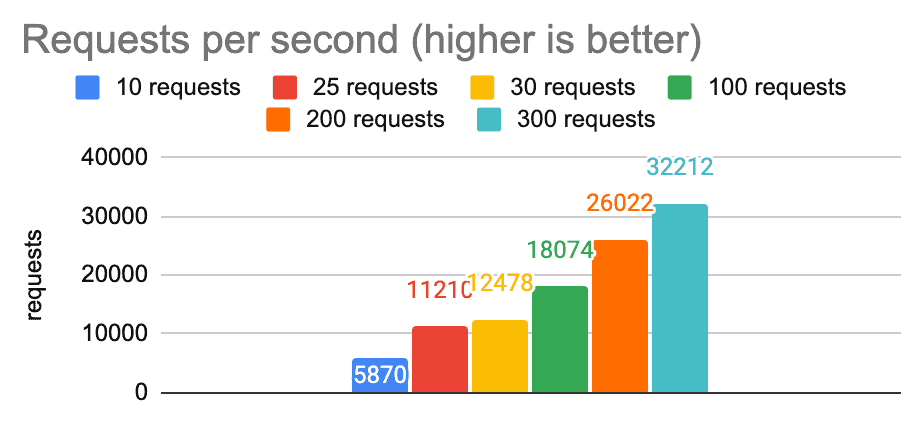
From these charts we can see we are able to hit our first latency target (p999 latency less than 20ms) with 200 concurrent requests.
For an application whose latency requirements are more stringent, we are able to hit our target of a p999 latency of less than 5ms with 25 concurrent requests. Our throughput goes down from about 26,000 to about 11,000, but this will still be the right trade-off for environments that are extremely latency-sensitive.
One more interesting observation on this data can be had by comparing it to the results we got when tuning our JavaScript and Python SDKs. Here are the throughput numbers that we got for the 20ms p999 latency goal for each language:
- JavaScript: 8,300 requests per second
- Python (with uvloop): 9,100 requests per second
- .NET: 26,000 requests per second
The JavaScript and Python numbers aren’t an apples-to-apples comparison with the .NET numbers because, for those runtimes, a single process can only exercise a single CPU core. So it’s not unexpected that we’d have much higher throughput with a .NET process. But it’s interesting to note that the value does not scale linearly with the number of CPU cores; since we were running these tests on a c6i.4xlarge, we had 16 CPU cores, but we only got around a 2.5x throughput improvement compared to the Python run. This illustrates that our bottleneck moves from CPU to network I/O very quickly once we are able to leverage more than one CPU.
Conclusion
With this data in hand we were able to establish good default values for configuring the Momento client for various environments and workloads. In the Momento .NET SDK, you can now choose between these pre-built configurations: Configurations.Laptop, Configurations.InRegion.Default, and Configurations.InRegion.LowLatency. Of course, you can always customize the configuration for your specific needs, but we hope to provide pre-built configs that will cover the 90% cases so that you can spend your time working on things that are unique to your business.
If you try out our .NET cache client and find any situations where the pre-built configs don’t give you what you need, please file a GitHub issue or reach out to us and let us know! We’d love to fill in whatever gaps are missing.
We enjoy pulling back the curtain a bit to give a glimpse into how we are approaching our client software—taking it just as seriously as our server products. But this is all just for fun and insight, and our position is that you shouldn’t actually need to worry about this stuff with Momento.