 カワジャ・シャムス
カワジャ・シャムス ダニエラ・ミャオ
ダニエラ・ミャオDespite having neither serverless nor caching in its name, S3 Express One Zone is truly a serverless cache. In this blog, we dive deep into S3, why it is slow for certain types of objects, and how S3 One Zone Express radically changes the landscape (for objects of a specific size). But it is not always a slam dunk: there are cases where other serverless caching solutions are much better fit for your workflow. We will conclude with the characteristics of your data that tell you whether to use ElastiCache Serverless, S3 Express One Zone, or Momento Cache.
What is S3?
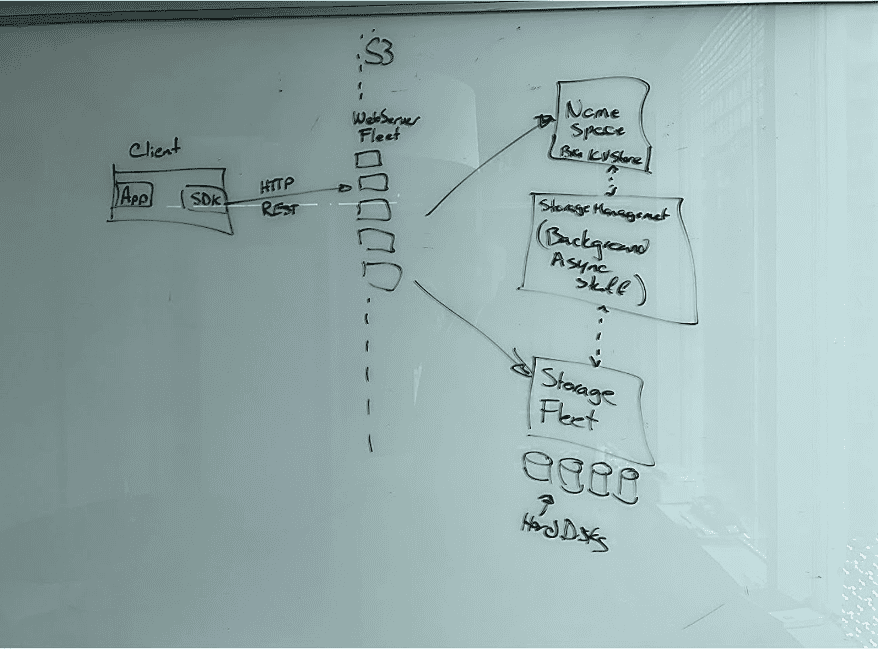
Contrary to popular belief, S3 is not the first AWS service. Multiple services, including SQS, predate S3. However, it is the most durable service at AWS in every sense of the word (although, DynamoDB does give it a run for its money on data durability)! It is highly available and it underpins pretty much every service at AWS. Ironically, despite not having serverless in its name, it passes the serverless litmus test better than any AWS service with the word “serverless” in its name.
S3 has traditionally been built for high throughput, highly durable, large objects retained over long periods of time. On the flip side, small, short-lived objects are not optimized for S3 due to cost and performance profiles. The cost of these objects is dominated by request pricing (as opposed to storage). The smaller and more short-lived an object, the higher ratio the request price becomes of your overall S3 bill. S3 also does not offer the lowest latencies on these tiny objects – but before diving into that, let’s do a quick primer on performance metrics.
A quick primer on latency
We all know that tail latencies matter – but latency of what? In high performance object stores, there are a few important latency metrics. Let’s cover a few quick ones:
- First Byte In: How long it takes a client to start receiving the data. It includes connection handshakes (if it is not the persistent connection), auth, and the network delays between client and server.
- First Byte Out: Everything in first byte in except the network cost between the client and server. This is measured at the server side: the clock starts once the request is received and stops once the first packet is sent to the client, regardless of whether the client receives it or not. It is an important metric because it covers the server’s performance regardless of where the client is.
- Last Byte In: How long it takes for the client to receive the entire object.
How does S3 perform against these metrics?
Like most engineering questions, the answer here is that it depends. While the performance of a large object is driven by the overall throughput (which is great between EC2 and S3), the performance of a smaller object is usually driven by time to first byte (aka First Byte In). If an object is large, you can make up lost time on getting the first byte by sending the data at a very high rate – but for a small object, you don’t have many bytes to send, so throughput becomes irrelevant. Time to first byte matters more as the object gets smaller. At an extreme, time to first byte for a 1 byte object is – well – the same as time to get the full object (Last Byte In).
So, small objects: S3 LBIs is suboptimal. On larger objects, it is wonderful! Side note: this is true for spinning drives vs SSDs too. You get great throughput from HDDs – but it takes a while for the heads to spin to the right location and start streaming the data back to you.
Why is S3 slower on time to first byte?
There are a few bottlenecks in S3’s design that slow the time to first byte. This is not an exhaustive list – but it includes auth, network, storage medium, and erasure coding.
First, every S3 request – even pre-signed URLs – go through IAM authentication. IAM is the central identity store for all of AWS – and while I remain impressed with how fast IAM works, there is only so fast you can make a centralized authentication in a large multi-tenanted system. Caching helps a ton here too – but that caching is done at the web server level. Unfortunately, due to the massive scale of S3, you are unlikely to hit the same web server across your clients.
Second, network hops are expensive. Going across AZs in AWS typically adds 500µs or more to your latencies. The physical distance between AZs is quite small, when comparing it against speed of light. However, going across AZs just requires your packets to hop through a lot more devices. More devices add inherent delays at p0 – but they also add more variance at your p999s. With S3, your request may get routed to the S3 web server fleet in a different AZ – and the web server that receives the request may not actually have the object available locally. As a result, your S3 request may end up hopping the AZ boundaries multiple times to fetch an object.
Third, the storage medium matters. As I speculate on the storage medium of S3, I consider the ridiculously low storage price of S3 (2.3 cents/GB) are 1/10th price of SSD storage in other serverless offerings (25 cents/GB on DynamoDB and 22.5cents/GB on Aurora). This makes me conclude that either S3 is using HDDs or SSDs with much lower throughput.
Fourth, erasure coding. Offering 11 9s of durability is not cheap or easy, and 2.3 cents/GB is a very aggressive price point! Making N copies of the data becomes untenable. When you grab an object from S3 – you are not simply grabbing the object from a disk. The object is spread across multiple devices and gets reconstructed in real time. It is pretty magical, but grabbing items from multiple disks on multiple nodes gets slow. You may be surprised to learn that there are tens of thousands of S3 customers that have their data spread on over a million drives!
What is S3 Express One Zone?
Simply put, S3 Express One Zone is a fast serverless object store. The sweet spot for item sizes on S3 Express One Zone is smaller objects under 512KB. It scales instantaneously, offers the same durability and availability characteristics as S3 (sans catastrophic datacenter level failures), and an amazing pay-per-use pricing model (no $90/month minimum like ElastiCache Serverless). It offers consistent single digit milliseconds of latencies for hundreds of thousands of requests per second (RPS). Note: The original version of this blog mistakenly mentioned a 128KB minimum billable unit for S3 One Zone Express. This has been corrected. Thank you Randall Hunt (@jrhunt) for helping us identify this error!
Why is S3 Express One Zone fast?
We speculated above that S3’s first byte out latencies suffer from authentication, network, and storage medium. Let’s dive into each of these for S3 Express One Zone.
S3 Express One Zone does away with IAM auth on every request. This has been a critical advantage that ElastiCache and ElastiCache Serverless have. Without IAM, you can auth really fast. S3 Express One Zone uses session-based authentication. You use a CreateSession API to request temporary, short-lived credentials that offer low latency access to your bucket. These tokens live for only 5 minutes – but if you use the official AWS SDK, it automagically renews these for you so you can keep getting lower latencies without worrying about auth.
The name says it all: S3 Express One Zone is a single AZ service. You do not have to hop AZs to get to the service – and the service does not have to hop AZs to get access to your data. To get the best latency and availability, you would use S3 Express One Zone in the same AZ as your compute nodes. This eliminates lots of hops, delivering better availability and meaningfully lower latencies. With ElastiCache and ElastiCache Serverless, the default high availability (HA) option is to go multi-AZ – which is a double-edged sword. On one hand, you get better resilience against AZ failure (but let’s face it, how often does that happen?), but on the other hand, you pay performance and cost (cross-AZ transfer = $$$) penalties with ElastiCache Serverless.
The storage medium here is most likely SSDs. Given the pricing of S3 Express One Zone of $.16/GB, I presume the storage medium isn’t RAM (ElastiCache Serverless is $90/GB) and it is not HDD (S3 is 1/5th the cost per GB). This looks awfully similar to DynamoDB ($.25/GB) – which is backed by SSDs. This is much faster than HDDs – and probably one of the key reasons why S3 Express One Zone promises consistent single digit latency, which may as well be code for SSD-backed stores.
Pricing for S3 Express OneZone vs ElastiCache Serverless
ElastiCache Serverless charges $90/GB of storage per month, which is pretty simple. This is justifiable given that they are likely storing all your data in RAM – with latency numbers to match. ElastiCache Serverless also appears to be more pragmatic in how your storage is measured. Meanwhile, the S3 Express One Zone pricing has a few key caveats that you should be mindful of.
Even if your object lives for 30 seconds, S3 will charge for the object as if it were around for at least 1 hour. So, if you modify an item every 30 seconds, you will be paying storage of 120x the data. In comparison, you can update a counter thousands of times per second on ElastiCache Serverless and only pay for the storage for the one item. The sweet spot for S3 Express One Zone is objects that are expected to be around for at least an hour – and rapidly changing items can result in a surprisingly large storage bill.
Lastly, S3 Express One Zone penalizes for objects above 512KB. PUTs are penalized by $0.008/GB above 512KB, while GETs are penalized by $0.0015/GB. The takeaway here is pretty simple: if you have a large object, your performance is likely driven by throughput anyway – and you may just get the best bang for the buck using S3 Standard.
Putting it all together: When to use S3 Express One Zone, ElastiCache Serverless, or Momento Cache
- If you have smaller objects around 512KB with a life cycle measured in hours, use S3 One-Zone express. If you have smaller objects that update often, use ElastiCache Serverless.
- If you have spiky traffic and do not want to wait for 10 minutes to handle 2x the throughput, use S3 Express One Zone. S3 is a multi-tenanted service and can absorb meaningfully larger spikes seamlessly without needing to scale up.
- If you have particularly spiky loads and a variety of object sizes from 100 bytes to 5MB, consider using Momento. It has the spike handling capabilities and true serverless-ness of S3 but without the $90/month surcharge for storage.


