

We recently launched Momento Topics, an easy and fast serverless pub/sub service helping you build event-driven architectures that scale. A customer asked us if we could support a 3.75 million subscriber game chat….we built it in an afternoon! Whether you’re launching the next big game or the next hot generative AI chat bot, chat platforms are a foundational capability now more than ever. Let’s walk through the test setup, then scale up some load, and finally show off some metrics.
Test Setup
When you’re operating a high-scale service, what you really want is consistency so it’s easy to predict how your system will perform under load—so for this test we’ll be looking closely at client-side p999 latencies. Looking at the client side is important since that’s where latencies typically start to creep up as you scale. You can read more about why tail latencies matter here.
We want to represent 75,000 game room chats you might find alongside a game session with a set number of players. Each message received by the chatroom will be broadcast to the subscribers in the room. I’m going to model a scenario where on average each chat room is receiving a new message approximately every 6.5 seconds and broadcasting it to 50 subscribers. We’re going to have 75,000 of these rooms at once for a total of 3.75 million users subscriptions and a message receive rate of 575K sessages/second!
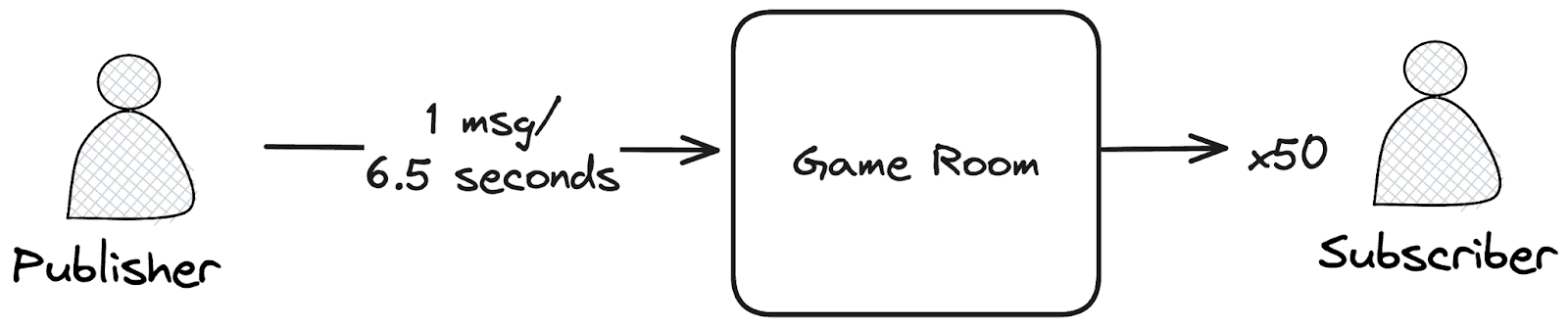
The exact targets i’m going to try to hit during this test are:
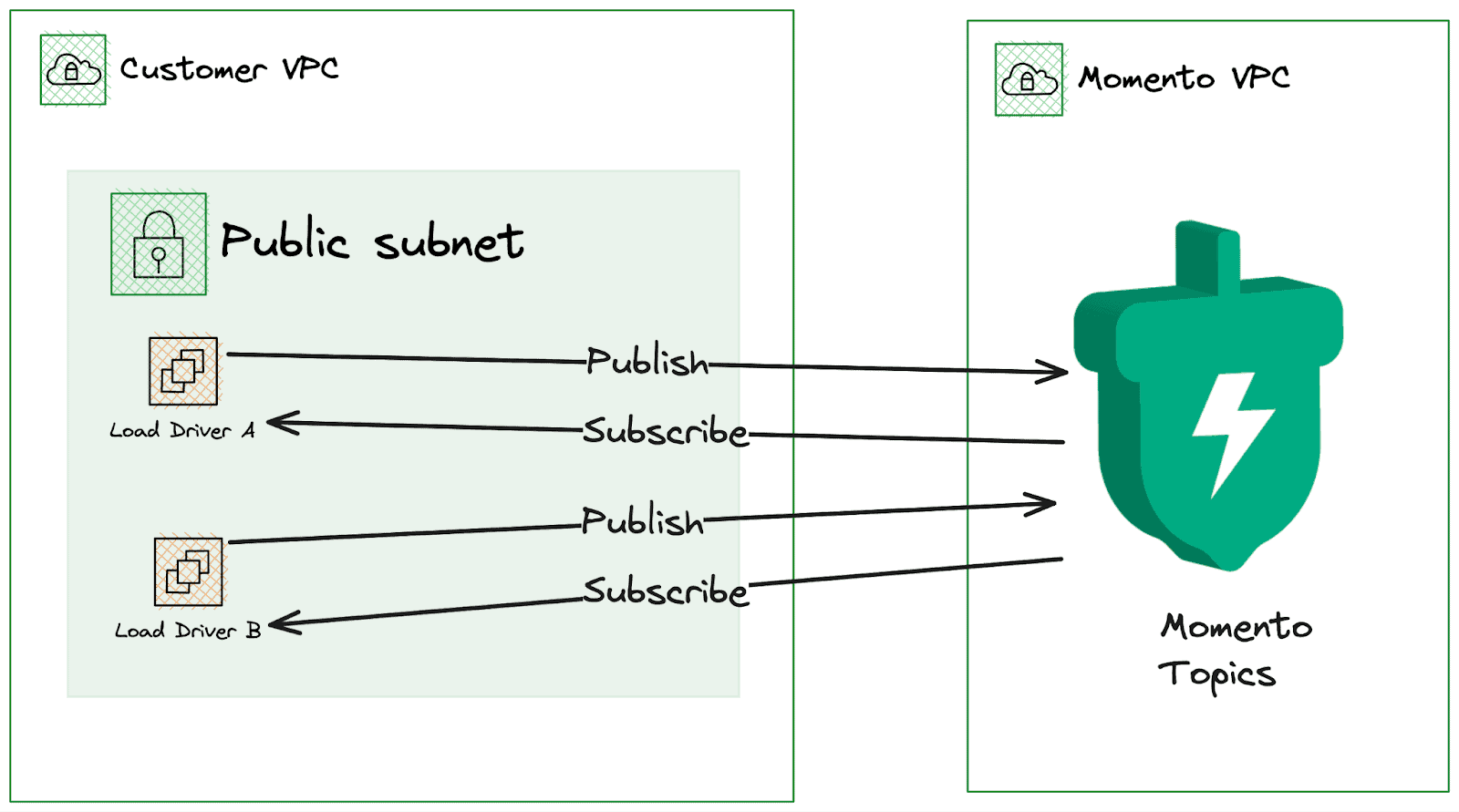
To cost-optimize the test I’ll be driving load from 4 c7gn.4xlarge EC2 instances using rpc-perf—an efficient load generator written in Rust that leverages the Momento Rust SDK under the hood. This will allow us to scale out to large numbers of topics, publishers and subscribers at reasonable cost.
We will end up with a setup that looks like this:
Test Results
With my test parameters defined,I kicked off the load drivers for the test. I wanted to do an endurance test which is where we run our test for several hours. This is to see how consistent the performance is and ensure latency or error rates don’t creep up over time. Ultimately, I left my test running for more than 2 hours, which allowed me to collect some solid data about the service.
Message Rates:
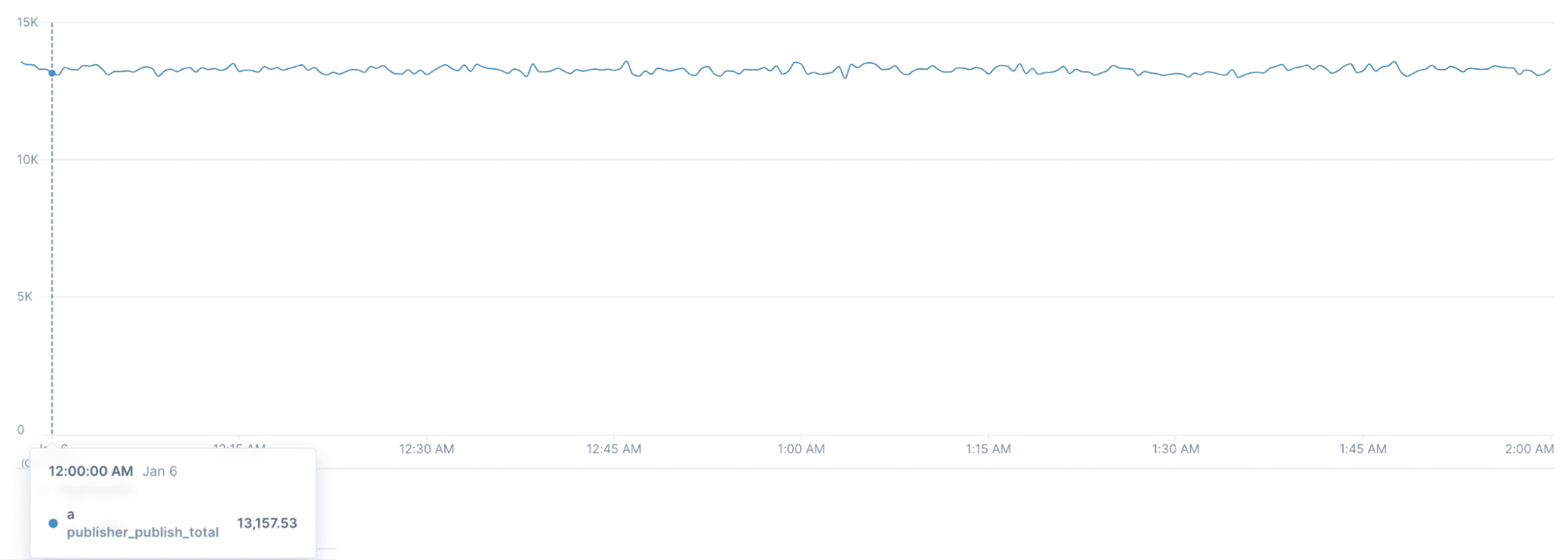
Publishers (message sent/second):
Here we can see our message publish rate has stayed steady above our target of 11,500 messages per second for the entire test.
Subscribers (message received/second):
Our message received rate stayed steady above our target of ~575K messages received a second for the entire test.
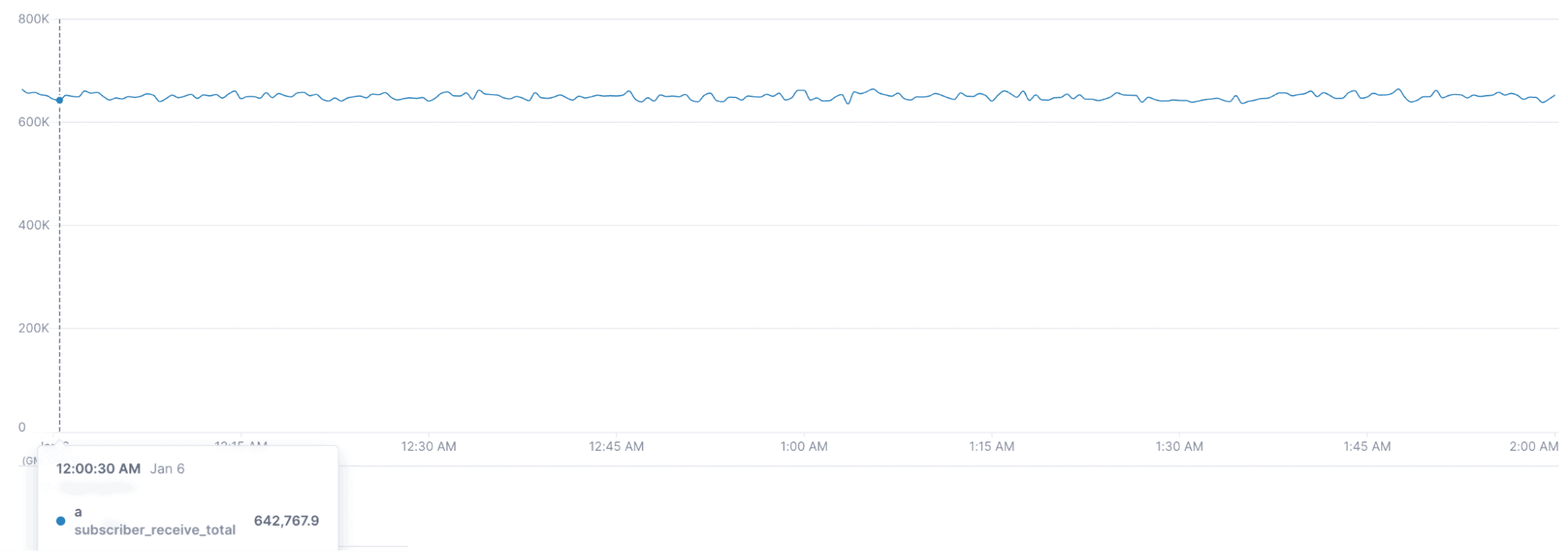
Subscriber Count
We maintained ~3.7 million subscribers for the entire duration of the test.
Latencies
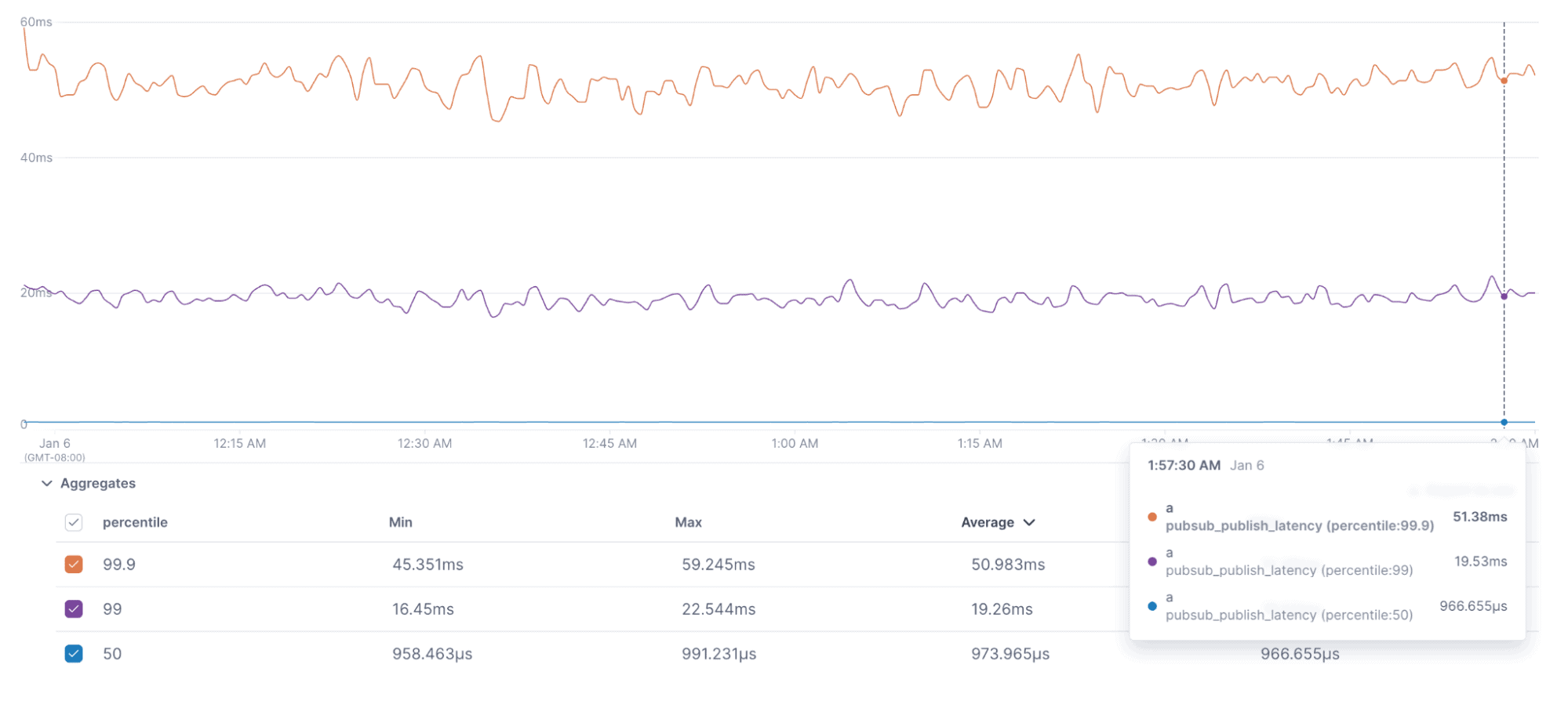
Publisher Latency
We can see our p99.9 client latency stayed at ~51ms for most of the test, while the p50 client latency was below 1ms for the entire test.
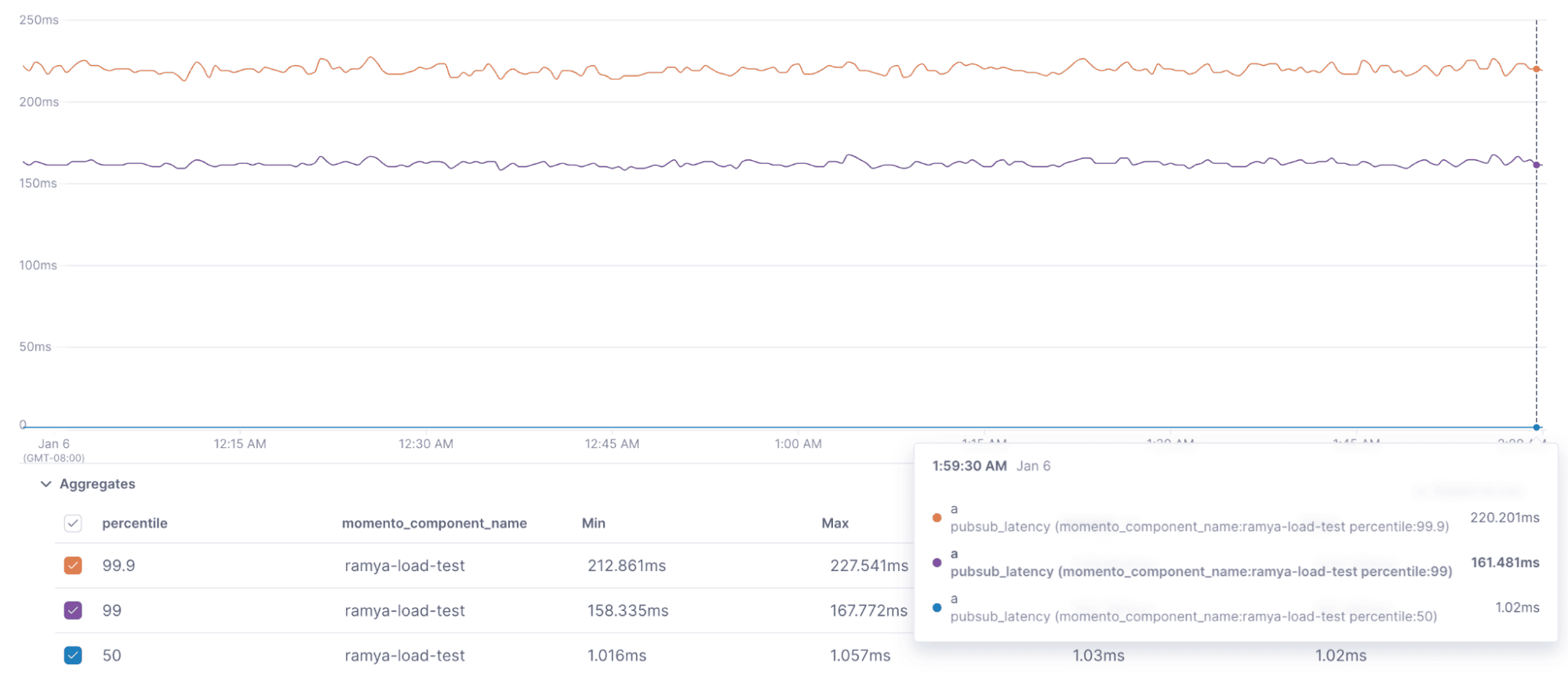
Subscriber End to End Latency
Our p99.9 subscriber e2e latency stayed at ~220ms for most of the test, and the p50 e2e latency was right around 1ms for the entire test.
Result summary
Overall I am very happy with the results of my test and the consistent latency numbers I saw. Being able to quickly spin up and hold this much sustained load for this long of a period really helps me build confidence when building mission critical applications. Having a low-latency pub/sub service that scales with you as you grow is a game-changer for real-time applications like a chat system—especially in the gaming industry where you have large waves of players coming online quickly and variable traffic that changes throughout the day.


