Effortless caching reducing MongoDB operations
Free up your database to focus on transactional and analytics work.

Share
Introduction
As a new entrance in the marketplace as Cache-as-a-Service, Momento asked me to evaluate their technology and write up about it. I’m coming in with an open mind as an Amazon Web Service (AWS) Data Hero. I’m partial to using AWS ElastiCache for Redis as my go-to caching provider. With Momento in the picture I’ve been inclined to check them out and see how much faster, cheaper, and better(?) they are. I have received no compensation (well, unless you count a tumbler ample compensation) for writing this article save for making great connections with the Momento team and joining their mission to #CacheTheWorld. In this blog I’m going to share some initial impressions from setting up Momento Cache with MongoDB.
Out of the gate, I can argue it requires far less ceremony for you to set up caching. One thing I’d like to see is having the same API as Redis or Memcached so businesses can move their code over without any or minimal changes—other than configs, of course.
For some of you, it might be a problem with yet-another-vendor to work with; however, studies show a 2-second wait on a website could drive customers elsewhere. This is the kind of study keeping marketing managers awake at night, thus they’ll push development teams to innovate further. After optimizing the software portion, they resort to putting their databases closer to their customers. Once the database enhancements are done, then I expect the caching will be the next biggest time-saver. As websites are increasing in complexity, your browser engines are working hard getting inundated with videos, graphics, plug-ins, and ad-tracking tools; thus I wouldn’t rely on the speed browsers.
Since major cloud providers have so many other things on their proverbial plate, Momento specializes in one thing only: caching while reducing latency as much as possible. Although it is a cloud-based provider, it has a presence across all hyperscale clouds and their respective edge locations thus reducing the latency behind caching to the bare minimum. This is a game-changer for those who may have an on-premise service, but could not move to the cloud yet, or for enterprises who may be risk-averse and want to be more cloud-agnostic or subscribed to the idea of being multi-cloud.
Typical client-server setup
If I was building out a website with little ongoing changes such as a personal blog or a website catering to a niche, I would just run everything on AWS. If I was advising a client who sweats at the prospect of having a single-provider risk, while their website requires infinite uptime with low latency, I would advise spreading out the pain onto multiple vendors while having a fail-fail-fail-over (not a typo!) to one cloud provider.
The MACH architecture (Microservices, API, Cloud-native, and Headless) is typical in most modernized websites nowadays. Microservices are little programs doing one, ok, maybe two things. APIs are URI/URL endpoints we interact with. Cloud-native means it runs anywhere—cloud, on-prem, or hybrid. Running as Headless via command line interface (CLI) or having a UI-based front-end built in front of the API are options—clients would either roll their own, use open source tools, or use a third-party integration tool.
Now armed with this level of detail, let’s come up with a hypothetical website and what tools it’d be running off of.
Taking action
I would have a running website hosted on Amazon Web Services (AWS) using Amplify, DocumentDB (compatible with MongoDB), Lambda, and API Gateway. Any website request would first go through the API Gateway endpoint, then passed off to a Lambda which consumes the request and determines what the request is asking for. The Lambda would then query the DocumentDB, wait for the data to come back, and when it finally does, it passes back a packaged response (JSON) through the API Gateway as a HTTP response to the Amplify web app. Let’s go with this line of thinking the rest of the way and figure out how we can be more risk-averse and cloud-agnostic.
As a tech leader, I want to ensure my systems are running as optimized as possible without any major outages. In the cloud, I could create an active-active setup, however it is very costly and AWS databases outside of DynamoDB don’t have the ability for seamless transition from one cloud region to another in case of regional failures. The technology teams need to intervene and manually change configurations to get their apps up and running again pointing to a different region; this process takes time and there is a risk not meeting the business’ recovery time objective.
Database
As mentioned, we’re using DocumentDB as our transactional store. While DocumentDB can hold its own in terms of failover, latency, and extreme durability; there is a business need to alleviate some risks by farming it out to a third-party provider. Because the DocumentDB API is 100% compatible with current versions of MongoDB, we can migrate our databases over to a specialized cloud data provider, MongoDB Atlas. Atlas has a cool ability to fail over in multiple regions AND to multiple cloud providers. If Google Cloud goes down, MongoDB will fail the database over to AWS or Azure. We can use MongoDB as our transactional data store and then we can sleep at night knowing the failovers will work as promised and the risks passed onto the team at MongoDB.
I’ve gone ahead using a cloud-based database provider not tied into a particular cloud. We will then compare results with a caching service, again, not tied to a particular cloud provider, Momento.
I want to see how much time I’m saving by using Momento to retrieve, say, a complicated data set from MongoDB from my laptop which is behind a 100mb/sec internet connection. First, I would sign up for a free MongoDB Atlas account using my Github credentials. You can go to https://cloud.mongodb.com and start the setup. It’s free; no credit cards required. MongoDB provides a series of collections (databases) you may use to query against. I’ve been looking for some data requiring some aggregation work and would take some processing time to retrieve.
I’ve settled onto returning data from the sample_analytics collection, included in the Atlas subscription, pulling information from their transactions table using the group keyword looking for transactions where individuals bought a specific stock.
['sample_analytics']['transactions'].aggregate([
{
'$unwind': {
'path': '$transactions'
}
}, {
'$match': {
'$and': [
{
'transactions.transaction_code': 'buy',
'transactions.symbol': 'adbe'
}
]
}
}, {
'$group': {
'_id': '$_id',
'transaction_item': {
'$push': '$transactions'
}
}
}
])By the way, if you’re wondering why your MongoDB program may not be working for you, you might need to go to Security > Network Access in the Atlas web UI to allow the IP you’re located to access the database. I’ve gotten caught many times wondering why the data isn’t coming back.
Once it works in the MongoDB UI and in your Python program using the pymongo library, then we can proceed to set up Momento. The Momento setup is very easy. If you disagree, let me know as I don’t know of any service letting you run anything new which requires 4 to 5 lines of commands. Using your email as the username, you can follow along the ‘Getting Started’ page to get the Momento CLI installed on your machine. Your momento account can be up and running in literally seconds.
Next, is getting Python to work with Momento. You can pull a program from their GitHub repo and start using it, testing a creation of a key-value and then reading it back. Take note you’ll need to use your authentication token Momento emailed you during setup. You can use Momento as a simple database if you’re so inclined, however you’ll need to seed it every time the cache entry expires.
After testing Momento using your Python program, it is time to combine the two access patterns into one. We need to decide on an approach to retrieve the data assuming cached data is quicker. Well, it has to be since your database is sweating CPU cycles trying to aggregate the data on the fly while the cache service only does a key lookup and returns one simple value.
Assume we have a service allowing auditors to see recent trades by company employees. In some companies, stock trades by employees are monitored to avoid the specter of insider trading. The data will be updated but not very often thus we can assume the data would not go stale.
Running Python
Using the program I’ve put together with the SKIP_CACHE flag of True, consistently, it takes about 5 seconds to retrieve the same record 10 times from MongoDB.
Using my slow internet speed—10 times at 5 seconds: an average of 0.5 seconds per data retrieval. Don’t forget we’d need to render the data coming back into a web page using CSS, JavaScript, and depending on the speed of the browser engine, your internet speed, your desktop computer speed, and of course the servers’ network latency and bandwidth… tons of bottlenecks to worry about—thus overall it’ll take longer than 0.5 seconds to present the data on your web page. I can tell you we can retrieve the data much quicker.
New code sequence
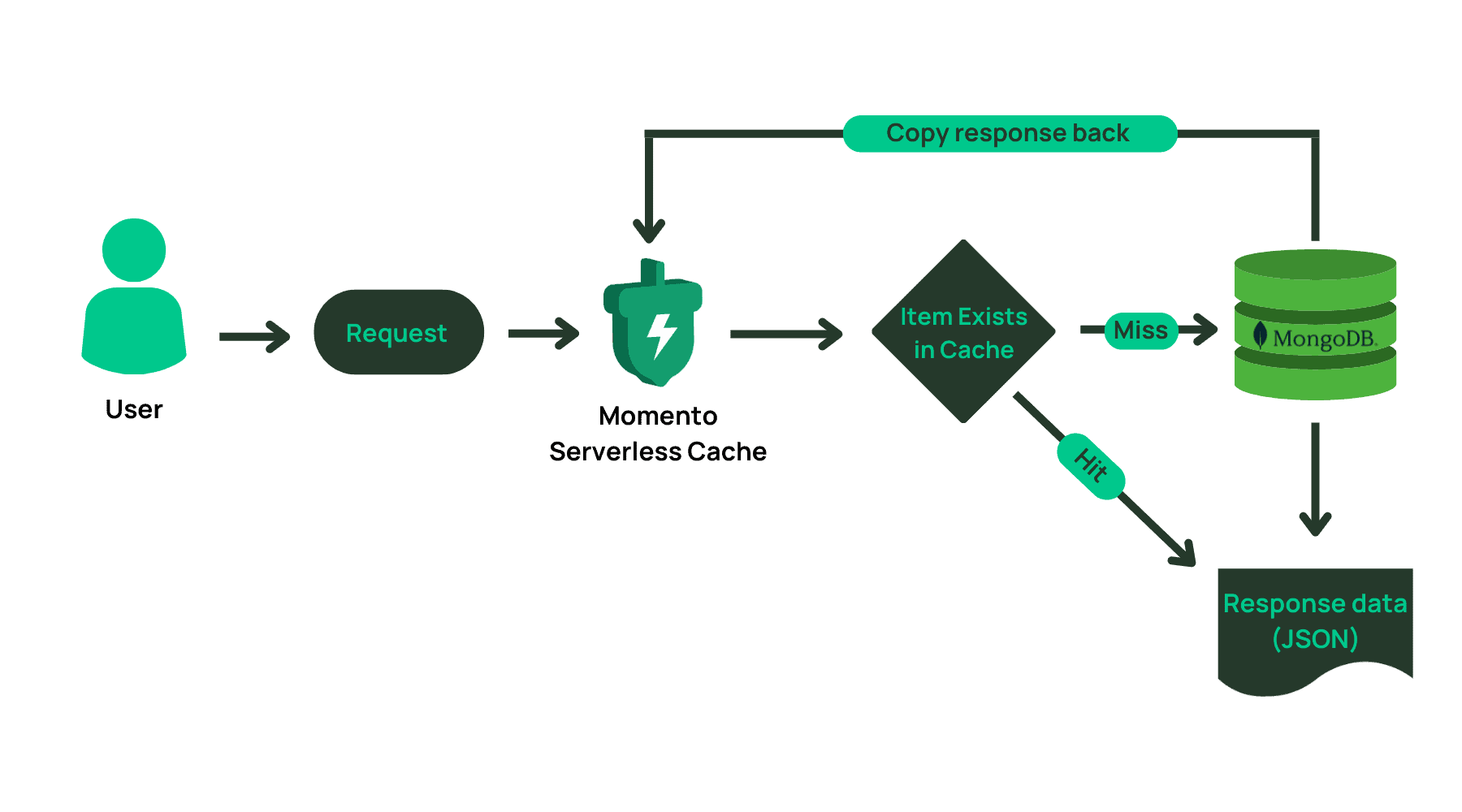
We need to figure out the sequence of how we retrieve data working with a caching service:
- User logs onto website
- User looks up a ticker symbol
- Program looks at Momento first to see if the ticker has been saved in cache. We can probably have a cache name using the pattern as “-“, or using real examples: adbe-buy, amzn-sell, msft-sell, goog-buy. This would be our Momento cache key.
- If the key isn’t found in Momento, retrieve it from MongoDB Atlas. After pulling data from MongoDB Atlas, save to Momento.
- If the data is stored in Momento as discovered by the cache key, return results to the user.
In the first go around, it saves the key in Momento. Then, we retrieve it over and over 9 more times. I see it took a little over 3 seconds to do.
Second time, it retrieved 100% of data from Momento only, and I’ve seen it go under 3 seconds. If we average it up to 3 seconds: 0.3 seconds per request! A 40% reduction in processing time compared to pulling data from the database every time.
GitHub repository
I’ve written this logic in my Python program in my GitHub repo at async-main.py. Please give it a shot and report back if you feel my numbers were a bit off kilter.
Conclusion
While the cloud hyperscale offerings are great and robust, too, there are always configuration and security concerns to manage. You need to figure out what network traffic is being expected and need to tune your caching service to match expected traffic surges. What if the unexpected happens either way? You could be losing money if you scale the caching service too much for a low traffic period, or lose customers because the website is taking too long to load the data.
Momento aims to cut the need to manage or scale the cache service, making it easy for you to focus on more important things, like your technical debts! Some folks might even NOT be in the cloud; thus, Momento can be a great alternative, minimizing the need to slam your on-prem databases and preventing your transaction logs from blowing up and saturating your disk space—I know every DBA deals with this far too often.
If you currently have cost or latency concerns with your current solution and feel caching will help you, try out Momento. There’s some great folks on the team who can help!
Python Notes
I’m using Python as it’s pretty much a universal language used by many data-oriented shops. When I started writing this blog, I used Python 3.9, but during this final push, I’ve decided to use Python 3.11. I can tell you right off the bat it tells me right away what the error is without being cryptic. For example, when I start the program, we need to add an Authentication Token variable to the command to validate the request.
$ python async-main.pyReturns
...
File "/Users/rob.koch/Library/Python/3.11/lib/python/site-packages/momento/_momento_endpoint_resolver.py", line 26, in resolve
return _getEndpointFromToken(auth_token)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/rob.koch/Library/Python/3.11/lib/python/site-packages/momento/_momento_endpoint_resolver.py", line 37, in _getEndpointFromToken
raise errors.InvalidArgumentError("Invalid Auth token.") from None
momento.errors.InvalidArgumentError: Invalid Auth token.Just from running this command, I immediately knew what the issue was and had to run the command passing in the auth token variable like so:
$ DEBUG=true \
MOMENTO_AUTH_TOKEN=* \
python3 async-main.pyAs I always forget to do the little things, I want something to help me remember faster. Enough gushing over Python 3.11.
Share






