Nobody builds a system intending to make it unoperatable. It happens gradually. A cluster grows. Another service gets added. Multi-tenancy gets introduced to cut costs.
Each decision is reasonable in isolation. Then one night something breaks, and the engineer on call is staring at dashboards they can’t interpret, running commands that return data they can’t compose into understanding, making judgment calls on a system that has outgrown their ability to reason about it. The system didn’t fail. The mental model did.
The pressure to build better tooling comes from scale forcing your hand. Valkey came to be because enough platform teams hit the same wall: distributed caches that grew into infrastructure their original tooling was never designed to operate. Two talks at Unlocked this year showed what hitting that wall looks like in practice, and what serious engineering organizations do about it.
The Failure Mode Nobody Could See
Ignacio Alvarez is a Senior Principal Engineer at Mercado Libre, the largest e-commerce platform in Latin America. His team builds the internal platform that all other engineering teams build products on top of.
That means operating roughly 8,000 caches, about 30,000 nodes, on infrastructure growing 30–60% year over year. At that scale, the standard playbook starts to break.
Their first-generation caching solution gave every application its own cluster. Clean isolation, no noisy neighbors, simple mental model. The tradeoff was efficiency. The solution resulted in idle infrastructure, poor capacity utilization, and no visibility into how resources were actually being used. More importantly, no governance. Teams picked whatever Memcached client they wanted, sized clusters based on gut feel, and the platform team had no levers to pull when things went sideways.
The second version introduced multi-tenancy to fix the waste problem. It also introduced a new kind of failure that was far harder to reason about.
Bandwidth saturation killed nodes.
Nodes across shared clusters were dying from the sheer volume of bytes moving in and out. This failure was invisible from inside any single service. One tenant looks fine. Several tenants, observed independently, all look fine. The failure only becomes visible when traffic accumulates across tenants and hits the ceiling of what the underlying nodes can handle. By the time nodes start dropping, the system has already crossed into instability.
This is a problem no individual service team can observe, diagnose, or fix. It exists above the application boundary. No amount of vigilance by any single team prevents it, because no single team can see it.
Mercado Libre’s response was structural and came in several parts. An SDK wrapper gave the platform team a single enforcement point across every service touching the cache. In practice, this meant the wrapper controlled serialization format, enforced maximum payload sizes before a write was even attempted, and applied compression transparently when values crossed a size threshold. A service team couldn’t opt out, misconfigure, or bypass it, which meant the platform team could make a single change to the wrapper and have it propagate across every workload in the fleet. That’s the only governance mechanism that works at 8,000 caches. You can’t negotiate behavior change with thousands of independent teams.
Alongside the wrapper, a centralized control plane made cross-tenant impact visible for the first time. Explicit observability around payload size surfaced the actual bottleneck before it became a crisis. And the team deliberately removed configuration options that increased systemic risk, narrowing what developers could do.
That last one is worth sitting with. The platform team made their system less flexible on purpose. At scale, flexibility is how invisible failures stay invisible.
Caching Grows Up
For most of its history, caching was treated as an application concern. You added Redis or Memcached to make a slow thing fast. You provisioned a cluster per service. You tuned TTLs. You worried about eviction policies. The mental model was local: this cache exists to support this application.
That assumption holds until the number of applications, clusters, and nodes grows large enough that the cache fleet itself becomes the system.
At that point, the problem changes. You are no longer tuning performance for a service. You are operating shared infrastructure across hundreds or thousands of services. Cluster topology, slot ownership, rebalancing safety, and cross-tenant visibility become daily concerns. The cognitive burden shifts from “how do I use the cache?” to “how do we safely operate this fleet?“
Mercado Libre built internal tooling to regain control at that scale. But the pressure they felt wasn’t unique. Every large platform running distributed caches eventually runs into the same constraint: the fleet behaves like infrastructure whether you intended it to or not. The tooling gap they had to fill internally is the gap Valkey is being built to close at the project level.
Valkey 9.0 introduced atomic slot migration and expanded cluster support to 2,000 nodes at over a billion requests per second. Atomic slot migration is worth understanding. Previously, migrating a key between slots could result in a window where the key existed in neither source nor destination, producing lookup failures that operators had to handle defensively. Atomic migration closes that window entirely. The key is owned by exactly one slot at all times. That’s one fewer failure mode platform teams need to reason about during a rebalance.
When a project’s major release focuses on predictable migration semantics and fleet-scale cluster behavior, the audience has shifted. These are features for platform teams running shared infrastructure, not application developers tuning latency.
Not every organization responds by adding more control at the infrastructure layer. Some change the shape of the problem entirely.
What If the System Were Easier to Think About
Joe Lane, Principal Software Engineer at Nubank, takes a different approach. Rather than compensating for operational complexity with tooling, his team eliminated the source of the complexity.
Joe’s argument starts with a problem so fundamental to traditional databases that most engineers have stopped noticing it:
“When you issue the same query twice in a row, you might get different results. You don’t have a strong basis to reason about the answer.”
This instability drives an enormous amount of defensive engineering. Cache invalidation exists because the ground beneath the cache keeps shifting. Distributed lock coordination exists because concurrent writes produce states you can’t predict. Linearizability checks, defensive copying, and consistency protocols are all downstream of the same problem: mutable state gives you nothing stable to hold onto.
Nubank runs on Datomic, which takes a different approach at the data model level. Rather than updating records in place, Datomic accumulates facts. Every update adds a new atomic fact to an ordered ledger. Nothing is deleted or overwritten. The database itself becomes something you can cache everywhere because it will never change underneath you.
Where Mercado Libre added control to manage shared state, Nubank removed the instability of state entirely. The result is a caching architecture that would be incoherent in a mutable system but works perfectly here:
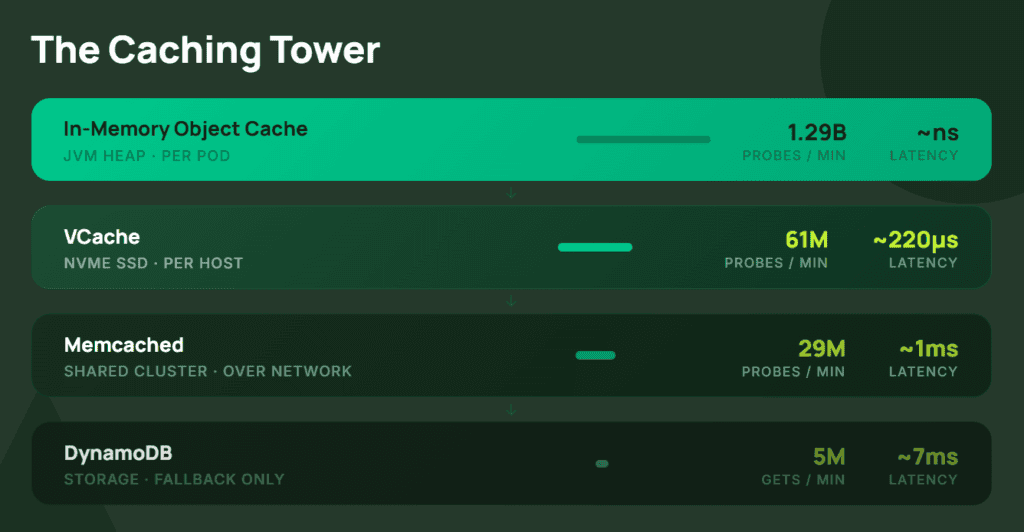
No invalidation protocol. No read coordination. Queries are deterministic. Send someone a point-in-time basis and a query, and they’ll produce the same answer a week later. The query engine lives in the application. Reads scale with your compute, not your database’s capacity to handle connections.
Joe ran the economics. If Nubank served those billions of reads from DynamoDB instead of the multi-tier cache, it would cost $97 million per year. They’d spend 124,000 years of cumulative wait time on reads annually.
The operational load drops because the data model gave engineers something stable enough to reason about that most of the defensive tooling became unnecessary.
Two Strategies, Same Underlying Problem
Ignacio and Joe arrived at opposite solutions, but they’re responding to the same constraint: systems that exceed human cognitive bandwidth.
Mercado Libre built governance mechanisms, enforcement points, and observability infrastructure because the failure modes of their system were invisible without it. The SDK wrapper is the only mechanism that lets a small platform team maintain meaningful control over a fleet of 8,000 caches operated by thousands of independent service teams.
Nubank reduced the need for tooling by choosing a data model that eliminates the instability that makes defensive tooling necessary in the first place. The immutable ledger removes entire categories of operational burden.
Both approaches share a premise: humans are the bottleneck, and something has to give.
Systems fail at scale because humans lose the ability to understand them in time to act. At a certain size, the complexity of the system genuinely exceeds what any team can hold in their heads. Scattered logs, independent metrics, and CLI output that requires mental reconstruction to mean anything all contribute to failing to understand fast enough when something is actively breaking.
The rise of Valkey and the architectural decisions made by companies like Mercado Libre and Nubank all point to the same underlying pressure: scale forces infrastructure to evolve around human limits. Valkey is what it looks like when that evolution happens at the project level rather than inside a single company’s internal platform. The conversations at Unlocked made clear that this pressure is widely felt, and that the engineering community is actively working out what serious responses to it look like.
Tooling is how you close that gap. Sometimes that means building enforcement mechanisms that make bad states unreachable. Sometimes it means choosing architectures that produce fewer bad states to begin with. Once you’re operating at scale, the choice is between tooling intentionally and watching people drown in complexity they were never equipped to manage.
These problems don’t get solved in isolation. They get solved when the people running the hardest systems compare notes. Unlocked is coming to Seattle this May. Bring your war stories.