 Alex DeBrie
Alex DeBrieIt’s no secret that I’m a big DynamoDB fan. I started using DynamoDB because of how well it worked with serverless applications, but I grew to love DynamoDB because of its consistent, predictable performance. It has made me wary of any service that has highly variable performance.
While I reach for DynamoDB first in my data persistence needs, it’s not the right tool for every situation. Even when DynamoDB is a good fit, I may need to pair other services with DynamoDB to meet my application needs.
In this blog, we’ll look at when to augment or even replace DynamoDB with a cache. We’ll focus on three main patterns:
- Accelerate DynamoDB performance with a cache;
- Increasing DynamoDB scalability with a cache;
- Reducing DynamoDB costs with a cache.
For each pattern, we’ll look at the reasons to consider a cache to augment or replace your DynamoDB usage and the key factors to consider.
Accelerate DynamoDB performance with a cache
The first, and most obvious, reason to use a cache with DynamoDB is to improve performance. This is no surprise since blazing speed is the raison d’etre of caches.
I often talk about DynamoDB’s fast performance, so this may be a surprise to some. But my point here is more subtle than pure speed.
Regarding DynamoDB’s performance, I often show a chart like the following:
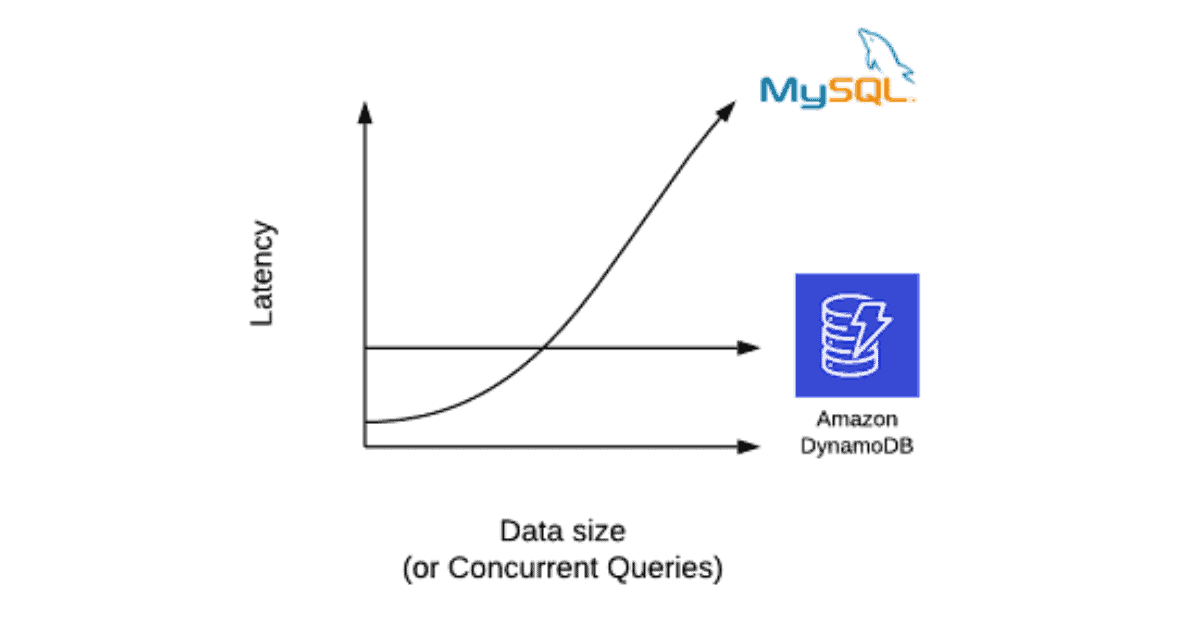
Notice how MySQL (or your relational database of choice) often gets slower as the amount of data in your database grows. In contrast, DynamoDB has the same performance even as the size of your table grows.
In showing this chart, I want to emphasize DynamoDB’s performance is consistent, regardless of factors like database size or the number of concurrent queries. For a single-node system like most relational databases, more data and more queries leads to more contention for resources, which increases query latency.
This consistency from DynamoDB is useful since you don’t have to spend time on costly refactors and optimizations as your database usage grows. You can expect the same single-digit millisecond response time on the first day your application launches or years down the road when you have significantly more users.
But for certain use cases, single-digit millisecond read response times aren’t fast enough. Your e-commerce users want faster page loads and your gaming users want snappier gameplay. If you’re working with a microservices architecture, your service may be one of many called to fulfill a single page load, and you don’t want to be holding up the entire response.
This is an example of using a cache to augment DynamoDB. You’re still counting on the durability and availability guarantees of DynamoDB for your core application requirements, but you’re also using a cache to improve performance in many cases. Caches relax some of the requirements of traditional databases by avoiding the use of disk storage in favor of faster, but less durable, RAM. As a result, your application gets faster response times for your most frequently used data.
Increasing DynamoDB scalability with a cache
A second reason to use a cache with DynamoDB is to enhance scalability.
*Record scratch*
You may be thinking “Wait a minute, I thought DynamoDB’s claim to fame is scalability. Why do we need a cache to enhance scalability?”
You’re absolutely correct, DynamoDB can handle incredible amounts of scale. To dive into this, refer to Jeff Barr’s recap of Amazon Prime Day 2022. Jeff notes Amazon retail’s usage of DynamoDB was in the trillions of requests over Prime Day, peaking at over 105 million requests per second.
So DynamoDB can handle scale. Yet a cache can still be useful in enhancing the scalability of DynamoDB. To understand this, we need to understand a bit about how DynamoDB works.
DynamoDB provides consistent performance at any scale by scaling horizontally. Rather than keeping all of your table’s data on a single machine, it will segment that data into “partitions” which are split across a large number of machines.
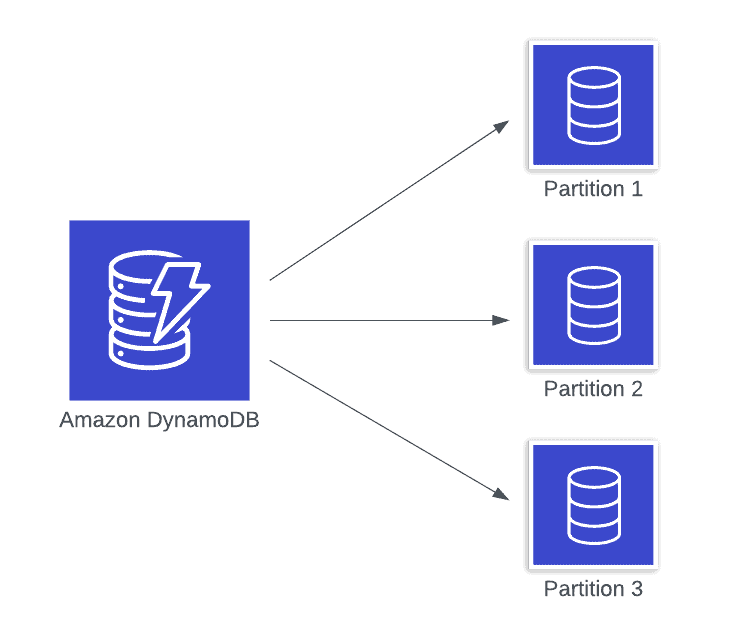
These partitions are intentionally kept small—no larger than 10GB. They are stored with partitions from many other tables on storage nodes that are shared across the DynamoDB service within a given region.
Because your partitions are stored near other partitions, the DynamoDB service enforces partition throughput limits that restrict the read and write throughput per second you can perform on an individual partition. Currently, you cannot exceed 1000 write units or 3000 read units per second on an individual partition.
For many use cases, the partition throughput limit is not an issue. It’s unlikely an individual customer will exceed 1000 writes per second on your ecommerce application, or a character in your video game will need 3000 reads per second. For these examples, a cache may not be needed for scalability purposes (though it can still help reduce system latency).
However, there are certain types of applications where the partition limits are a problem. Think of social media applications like Twitter or Reddit where popular tweets or threads can receive millions of impressions in a short period of time. Or, consider social shopping sites where hot deals drop and lead to extreme traffic as shoppers hurry to capitalize.
Both of these examples may be examples of Zipfian distributions where the most popular items are accessed orders of magnitude more than the average item. Because DynamoDB wants a more even distribution of your data, your application may get throttled as it tries to access popular items.
Adding a cache in front of your DynamoDB table can help you here. Central caches like Momento are designed to handle high volumes of concurrent requests. By pointing your read traffic at a cache, you can alleviate the load from your hot partitions in DynamoDB.
Like the previous example, this is another way to augment your DynamoDB table with a cache. Both examples work well with a read-aside caching pattern in which records are durably written to DynamoDB but many reads can be served from a central cache. This will reduce DynamoDB throttling issues while also enhancing performance in your application.
Reducing application costs for write-heavy applications
While the two patterns above are both about using a cache in conjunction with DynamoDB, this last pattern is about using a cache to replace DynamoDB. The justification to replace DynamoDB with a cache is centered around costs, so let’s first review how DynamoDB billing works.
Rather than charging you for instance-based resources like CPU, RAM, or disk IOPS, DynamoDB charges you based on reads and writes directly via read units and write units. A read unit allows you to read 4KBs of strongly consistent data while a write unit allows you to write 1KB of data. Note that DynamoDB rounds up, so a read of 100 bytes would be rounded up to a full read unit while a write of 100 bytes would be rounded up to a full write unit.
Finally, you have the option of two different billing modes in DynamoDB. You can use Provisioned Capacity mode, in which you will pay an hourly rate for the read and write units you need available on a per-second basis in your application. Alternatively, there is an On-Demand mode in which you do not specify capacity up front but are charged for your read and write units on a pay-per-use basis.
The On-Demand mode is about seven times more expensive than the equivalent fully utilized Provisioned Capacity mode, but full utilization is very unlikely. Depending on the predictability of your workload, utilization on your Provisioned Capacity can be 20% on the low end or 70% on the high end.
With this background in mind, let’s run some calculations. In the examples below, we will be looking at how much it costs to write 1 GB of data into DynamoDB. First, it will show the costs if using the serverless On-Demand billing mode. Then, it will show the costs if using Provisioned Capacity at 100% utilization and at 50% utilization. These three estimates help to set the upper and lower bounds for costs as well as a likely scenario.
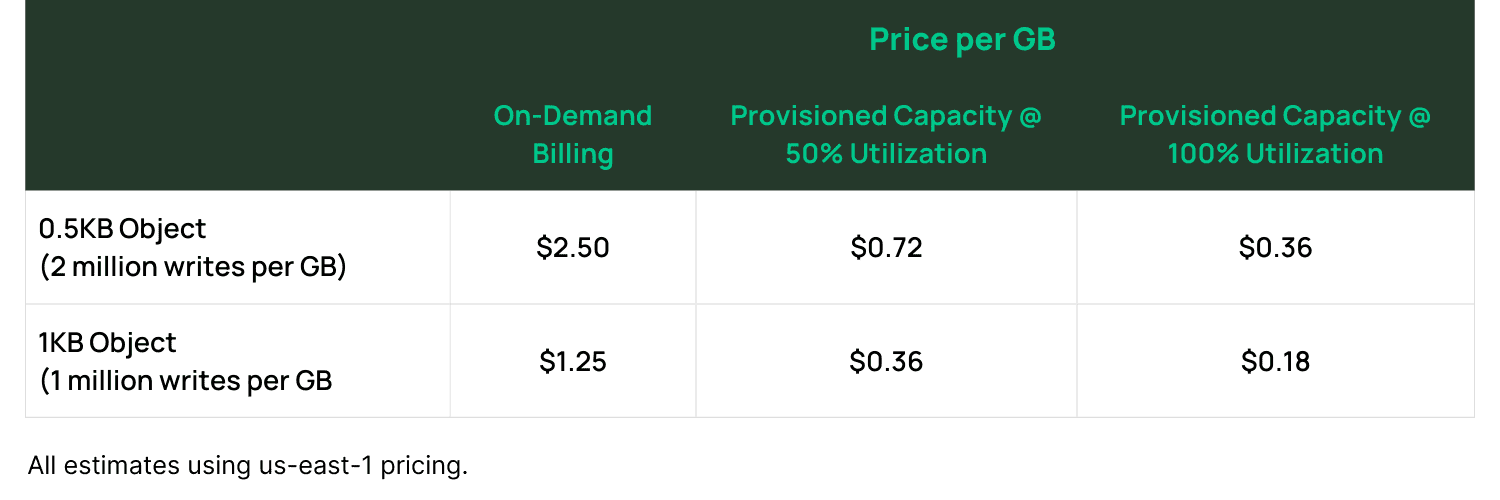
In the chart above, we see that even in the ideal scenario where your objects are exactly 1KB (and thus fully consume one WCU) and you get full utilization from your provisioned capacity, you are paying about 18 cents per GB of data written to DynamoDB. In a more likely scenario where you’re getting 50% utilization and writing half-kilobyte objects, your cost will be $0.72 per GB of data written. Many use cases will have per-GB costs that are even higher, such as if you’re using On-Demand billing or writing smaller items.
Now, let’s add Momento in for comparison so we can start to see the shape of the cost savings I’m talking about. Momento has a simple pricing model of $0.50 per GB of data written or read. This means a pronounced cost difference in most common scenarios.
Of course, this doesn’t mean you should drop your DynamoDB database and move it all to a cache. As a primary database, DynamoDB provides a number of properties around durability, availability, and indexing which are not available from a cache.
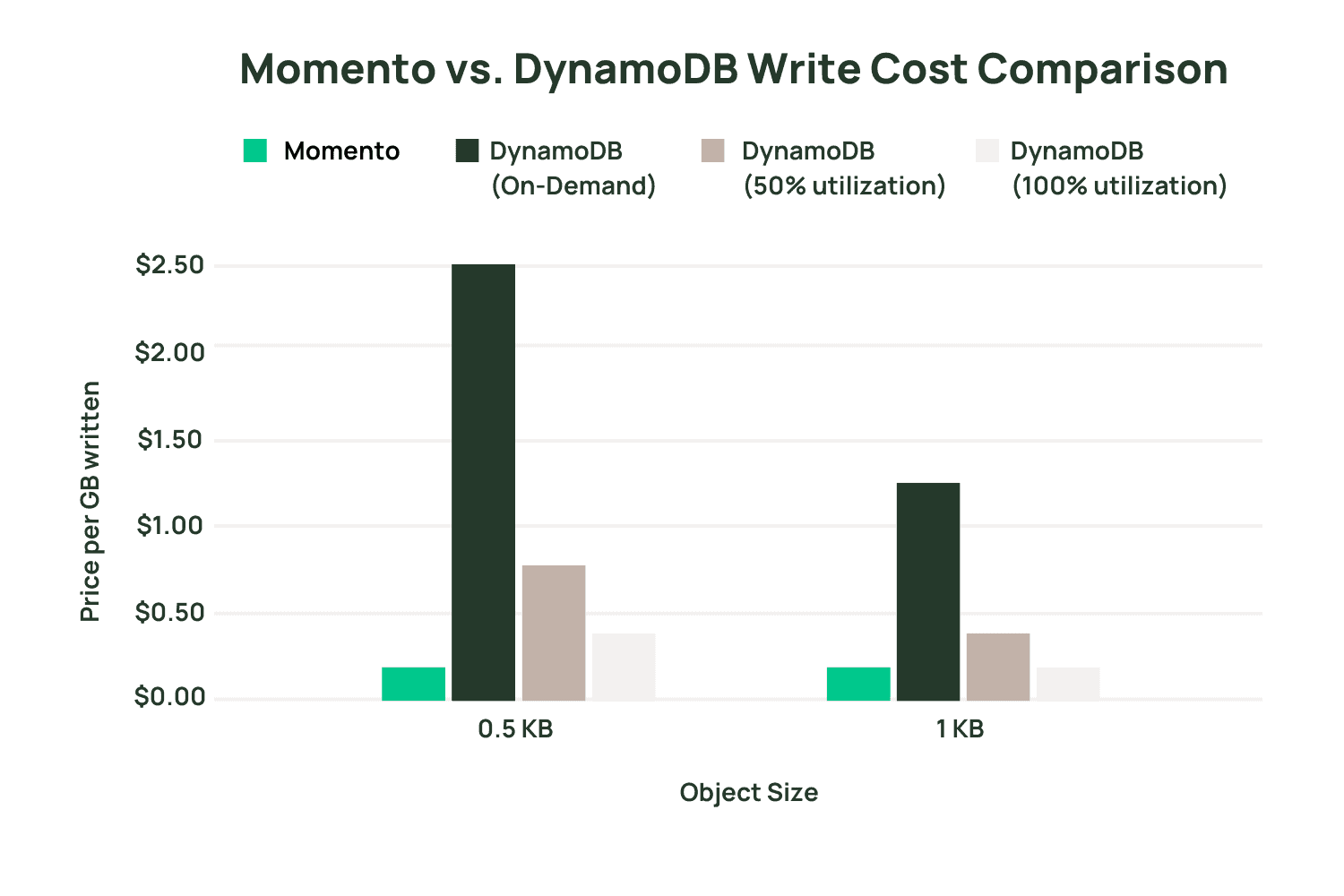
Yet, for certain use cases, it can make sense to move your workload from DynamoDB to Momento to save money. If you have workloads characterized by a high volume of writes but the data is essentially ephemeral (or doesn’t need the stronger durability guarantees of a primary, disk-based database), using a cache can be a good fit.
The two most common examples here are session management or rate limiting. In both situations, you have small bits of data accessed at high frequency. Further, both use cases are situations where the data is ephemeral or can be easily regenerated and thus fits well with the characteristics of a cache. By moving from a primary database to a cache, you will get lower latency and lower costs.
Conclusion
In this blog, we saw how to think about using a cache in conjunction with or in place of Amazon DynamoDB. First, we saw how a cache can improve the tail latency of your application, which is particularly important when there are a number of data access requests required to handle a workflow. Second, we learned how a cache can enhance the scalability of DynamoDB by alleviating pressure on hot partitions. Finally, we explored how a cache can replace DynamoDB and reduce application costs for certain workloads.
In each of these situations, be sure to understand your application requirements. Consider your workload and layer in a cache if it fits your needs.


