Valkey 8.1 vs Redis 8.2: Memory Efficiency at Hyperscale
Valkey 8.1 uses 28% less memory than Redis 8.2 in our 50M sorted set benchmark. See the throughput and memory data from real-world hyperscale testing.

Share
When infrastructure is handling hundreds of millions of operations a day at petabyte scale storage, every byte of memory overhead matters. Sorted sets, the backbone of leaderboards, rankings, and prioritized queues, are especially unforgiving. A few extra bytes of overhead per entry can snowball into gigabytes, lowering utilization, increasing cost, and the risk of degraded responsiveness during peak events.
Raider.IO, which tracks millions of World of Warcraft players in real time, lives this reality every day. For them, memory efficiency isn’t a nice-to-have. It’s the difference between smooth seasonal surges and outages that disrupt the player experience.
To understand how recent improvements in Valkey and Redis translate to workloads like Raider.IO’s, we benchmarked Valkey 8.1 against Redis 8.2 by inserting 50 million items into a sorted set and measuring the memory usage and throughput under pressure.
About Valkey & Raider.IO
At Momento, Valkey is one of the primary storage engines we operate in our Cache service. Its memory efficiency and predictability make it a strong fit for powering mission-critical, real-time workloads at scale. By building on Valkey, we can deliver caching that is fast, resilient, and cost-effective without adding operational complexity for our customers.
One of those customers is Raider.IO, the most popular companion site for World of Warcraft players. Raider.IO maintains leaderboards that track millions of characters and guilds, updating every time a player clears a dungeon or raid. That translates into hundreds of millions of sorted-set operations every day. In that kind of environment, downtime or latency isn’t acceptable. The efficiency of Valkey, combined with Momento’s managed infrastructure and operational expertise, makes leaderboards stay responsive even under peak loads.
Challenge: Memory Efficiency at Scale
Redis and Valkey both recently advertised memory optimizations. Redis 8.2 introduces more than 14 efficiency improvements, including a new representation that can reduce memory usage for keys and JSON by up to 67 %. Valkey 8.1 features a completely new hashtable that cuts per‑key overhead by roughly 20–30 bytes and boosts throughput by about 10 %. Which would deliver the best results on our leaderboard workload?
We spun up an AWS c8g.2xl (Graviton4) instance with 8 vCPUs and 16 GB RAM. We ran Valkey 8.1.1 and Redis 8.2 on the same node. Using an in-house benchmarking harness written in Rust, we inserted 50 million items into a sorted set, 250k at a time, and recorded used memory (INFO MEMORY), throughput, and ZSET size after each million inserts.
Here’s the memory growth:
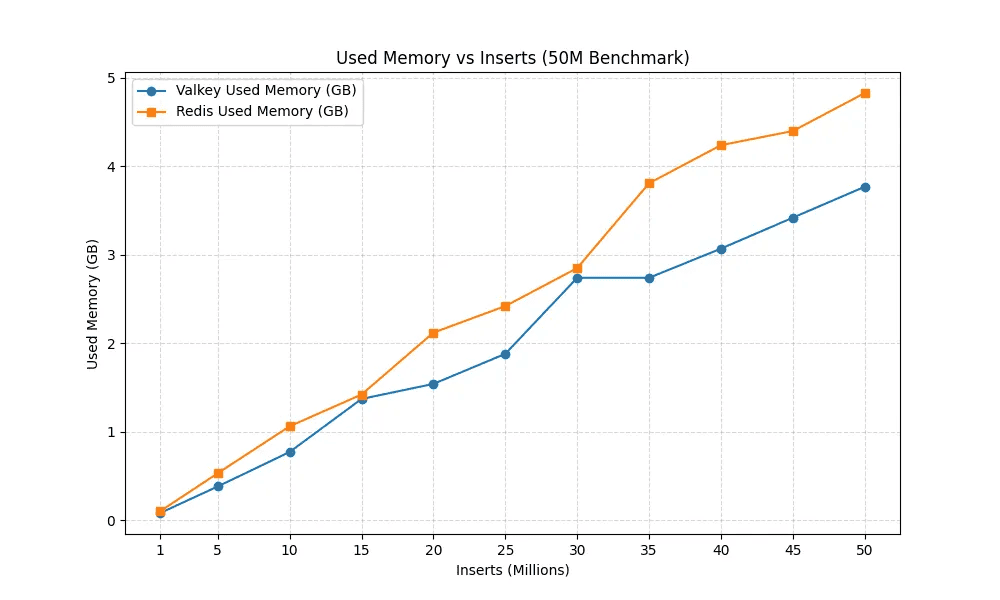
Results: Consistent Memory Savings and Throughput
From the start, Valkey was more frugal. At 1 M inserts, Valkey used ~80 MB of memory while Redis used ~100 MB. By the time we reached 50 M entries, Valkey consumed 3.77 GB whereas Redis consumed 4.83 GB, a difference of 1.06 GB (28 %). That reduction aligns with Valkey’s per‑key overhead savings and the Linux Foundation’s claim that upgrading to Valkey 8.1 can reduce memory footprints by up to 20 % for most workloads. Throughput told a similar story: Redis initially led, but Valkey held steady and finished the run at ~570 k inserts/s while Redis dropped to ~530 k/s, a ~7 % difference.
This impact is noticeable. A 28 % memory reduction means fewer cache nodes, lower operating costs, and room for growth during peak events. Stable throughput ensures leaderboard updates stay snappy even when millions of records are updating. And Valkey’s smooth performance curve makes capacity planning more predictable – no surprise memory spikes when the dataset crosses certain thresholds.
Try It Yourself
We believe in transparency and reproducible results. Our benchmark is open source and designed to run on any Linux system with Docker and Rust installed.
Quick Start
The benchmark runs both Valkey and Redis simultaneously on different ports, allowing direct comparison on identical hardware. Here’s how to reproduce our test:
1. Start Redis 8.2
docker run --network="host" --rm \
--cpuset-cpus="2-7" \
redis:8.2 \
--save "" --appendonly no \
--io-threads 6 --protected-mode no \
--maxmemory 10gb2. Start Valkey 8.1.1 in a separate terminal
docker run --network="host" --rm \
--cpuset-cpus="2-7" \
valkey/valkey:8.1.1 \
--save "" --appendonly no \
--io-threads 6 --protected-mode no \
--maxmemory 10gb --port 6378
3. Clone and run the benchmark
git clone https://github.com/momentohq/sorted-set-benchmark
cd sorted-set-benchmark
cargo run --release -- \
--valkey 127.0.0.1:6378 \
--redis 127.0.0.1:6379 \
--step 1000000 --flush \
--total 50000000 --batch 250000The benchmark will insert 50 million items in batches of 250,000, measuring memory and throughput at every million-item milestone. Results are output as a formatted table showing memory usage and operations per second for both databases.
Configuration Notes
- –cpuset-cpus=”2-7″: Pins both databases to the same CPU cores for fair comparison
- –save “” –appendonly no: Disables persistence to isolate memory performance
- –io-threads 6: Matches our test configuration (adjust based on your CPU count)
- –maxmemory 10gb: Prevents OOM during the test (adjust based on your available RAM)
- –network=”host”: Allows the benchmark tool to connect to both instances
To learn more about how we tune our Valkey benchmarks to reach over 1 million RPS, you can read the blog.
Hardware Recommendations
Our test used an AWS c8g.2xl (8 vCPUs, 16 GB RAM), but you can run this on any system with:
- 4+ CPU cores
- 8+ GB RAM (16 GB recommended for the full 50M item test)
- Linux (required for –cpuset-cpus flag)
For smaller systems, reduce –total to 10 or 25 million items. The memory efficiency differences remain consistent at any scale.
What You’ll See
The benchmark outputs real-time progress and on completion generates a comparison table showing with all the information from the run.
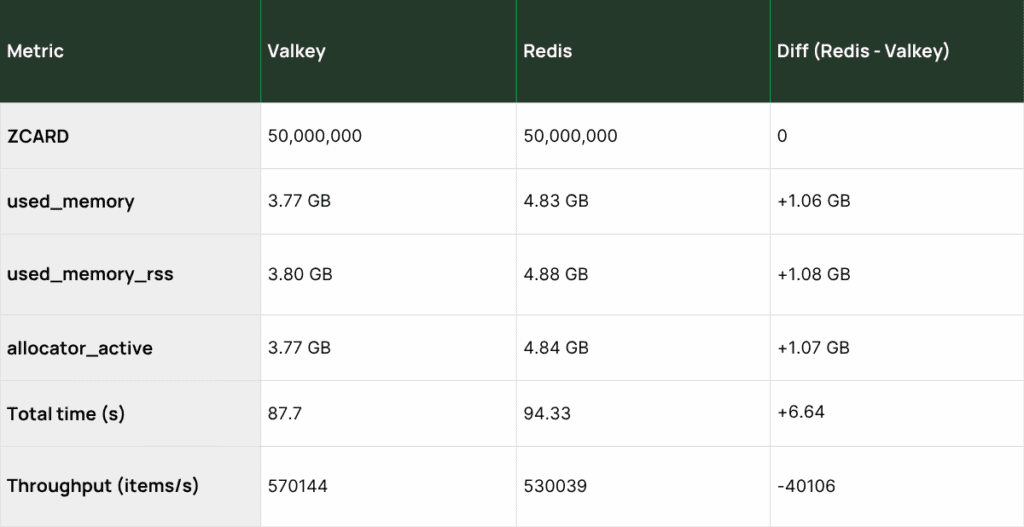
If you’re running sorted-set workloads or any high-volume real-time application, we encourage you to test this on your own hardware and share your results. Join the Valkey community and help us build better in-memory data stores together.
Share




