Momento is the DNA of AI agents
Enterprise-ready AI Agents need strong communication, reliable memory, and scalable code execution to move beyond fragile prototypes.

Share
The past three years have been a whirlwind in the tech industry. Ever since ChatGPT dropped in November 2022, we’ve fully embraced generative AI and woven it into our daily lives. Engineers use it as a pair programmer in their IDEs, companies build RAG pipelines for expert-level chat automation, and honestly? Most of us have basically replaced Stack Overflow with CLI tools that answer targeted questions in seconds.
When the Model Context Protocol started gaining traction in early 2025, we saw the industry pivot hard toward AI agents. All of a sudden, new advancements, POCs, and advanced use cases for AI were emerging daily, propelling us further into the throes of generative AI. But we were still early. With so many moving parts and conceptual “land grabs” in the AI agent space, many people were building agents that could accomplish tasks, but it was dirty.
Unscalable, siloed hacks got us through day zero of AI agent building. But those methodologies don’t scale to the enterprise. Hacks mean outages, ballooning costs, and security blind spots. A production-ready system needs to remove those risks before they show up in production.
Fortunately, the ecosystem hasn’t stood still. Protocols like MCP and Agent-to-Agent (A2A), have emerged to define how agents act, communicate, and collaborate. They lay the groundwork for production-ready agents. And Momento has been on top of this for months.
But protocols alone aren’t enough. If we take a step back and look at what production-ready AI agents actually means, three things come to mind: expedient communication mechanisms, reliable memory, and scalable code execution.
Communication
Agents shouldn’t operate in silos. If you build a “mono-agent”, you’ve likely granted too many permissions to a single agent and are left with a large blast radius if things go wrong. By contrast, building single-responsibility agents scopes each one to a particular domain, lets you select the right model for better responses, reduces unnecessary context for a given task, and minimizes the surface area for failure. This translates directly into smaller blast radiuses, better governance, and lower operational risk.
By keeping agents focused, you rely on multiple of them to accomplish a task. To accomplish a task efficiently and cost-effectively, a strong communication mechanism is required. The A2A protocol defines ways for both synchronous and asynchronous communication.
Event-driven workflows
In event-driven workflows, a supervisor agent can fan out tasks and then subscribe for updates. As each agent completes its part, it publishes results back over a secure topic and exits.
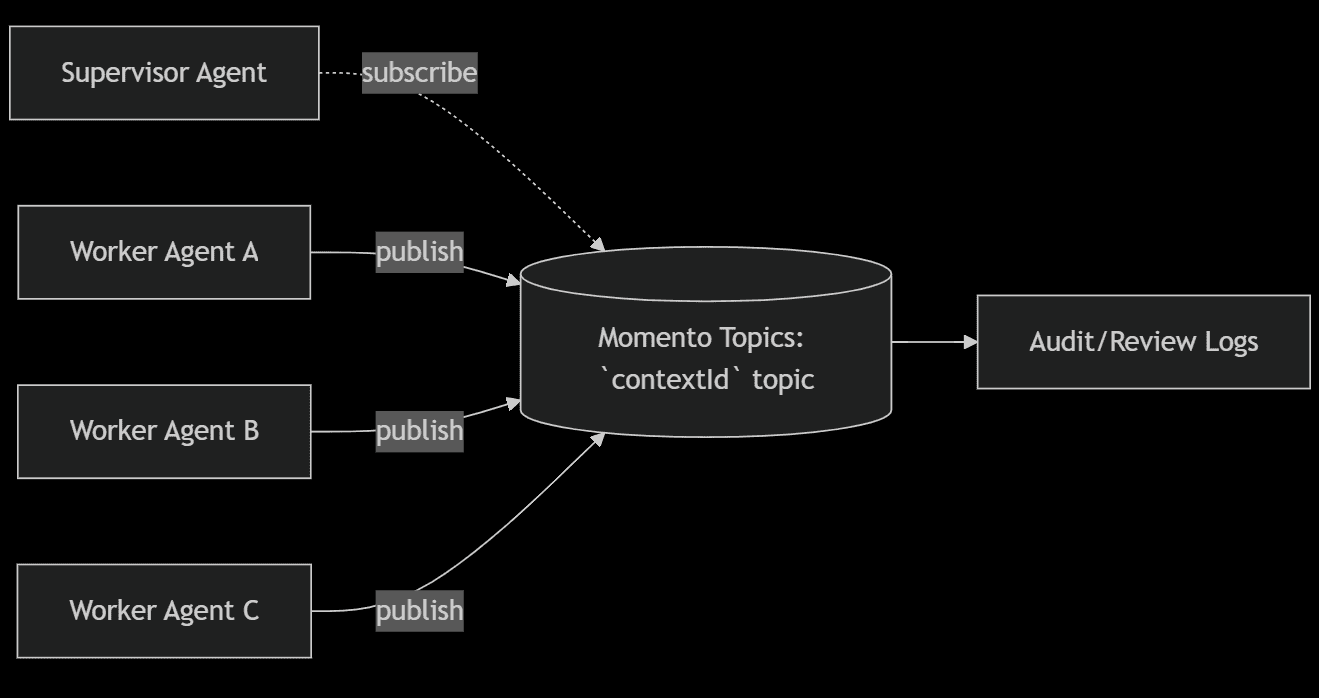
Implementation of the pattern above using A2A is simple:
async function subscribeToAgentUpdates(taskId, a2aClient){
const taskScope = {
permissions: [{
role: TopicRole.PublishOnly,
cache: CACHE_NAME,
topic: taskId
}]
};
// generate a disposable token the agent can use to publish
const token = await momentoAuth.generateDisposableToken(taskScope, ExpiresIn.hours(1));
await a2aClient.setTaskPushNotificationConfig({
taskId,
pushNotificationConfig: {
url: `${MOMENTO_REGION_ENDPOINT_URL}/topics/${CACHE_NAME}/${taskId}`,
authentication: { credentials: token }
}
});
// supervisor subscribes to agent updates
await topicsClient.subscribe(cacheName, taskId, {
onItem: handleAgentUpdate
});
}Using Momento best practices, you can scope downstream agents securely with limited access to only the relevant resources for the task. As progress is made, events are emitted to the supervisor via a dedicated topic to the task. This pattern provides audit trails for every interaction, making compliance and troubleshooting as easy as… calling an LLM.
Orchestrated workflows
In orchestrated workflows, a supervisor agent calls agent workers in a specific order, using tools for synchronous steps while emitting asynchronous workflow events for audits and human review.
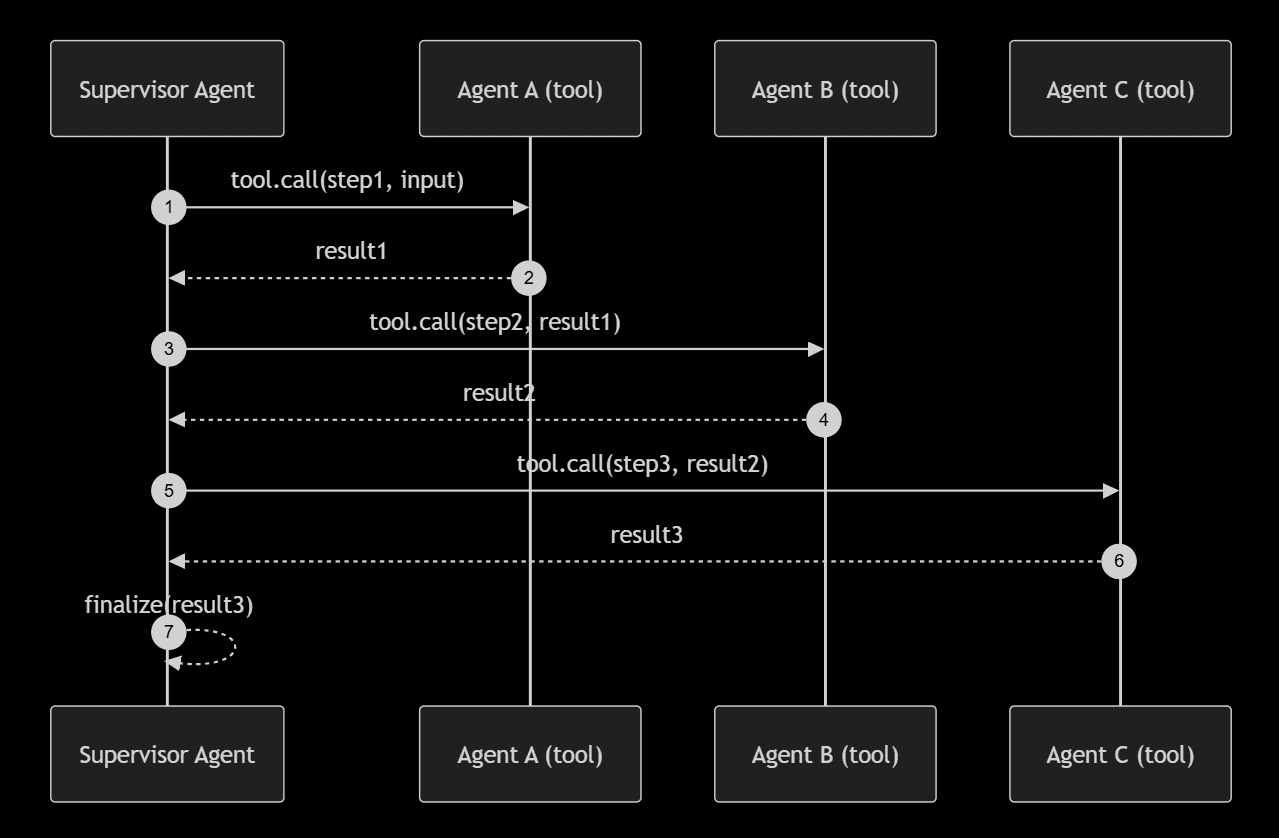
With orchestrated workflows, the LLM makes use of a tool that calls the downstream agents. In many instances, the tool is just a wrapper for a call using the A2A protocol.
async function invokeAgent({ agentUrl, message, contextId, taskId }) {
const client = new A2AClient(agentUrl);
const response = await client.sendMessage({
message: {
messageId: uuidv4(),
kind: 'message',
parts: [{ kind: 'text', text: message }],
role: 'user',
contextId, taskId
}
});
return response.result;
}The result from the tool is the synchronous response from the downstream agent. The supervisor takes that and uses it as context for the other calls it needs to make as part of the workflow.
In both types of workflows, Momento Topics provides the secure, scalable communication backbone agents need. Combined with memory and code execution, this is what turns protocols into production-ready systems.
Memory
One of the hardest parts of building reliable AI agents that improve over time isn’t teaching them how to talk to each other. It’s helping them remember. Enterprise workflows aren’t one shot prompts. As we just discussed, they are executed across many steps, involve multiple agents and participants, and can potentially span several minutes or hours.
Enterprise-grade memory has three primary components: immediate context, a scratch workspace, and long-term recall. Each one of these is distinct in the functionality it provides and its resulting implementation.
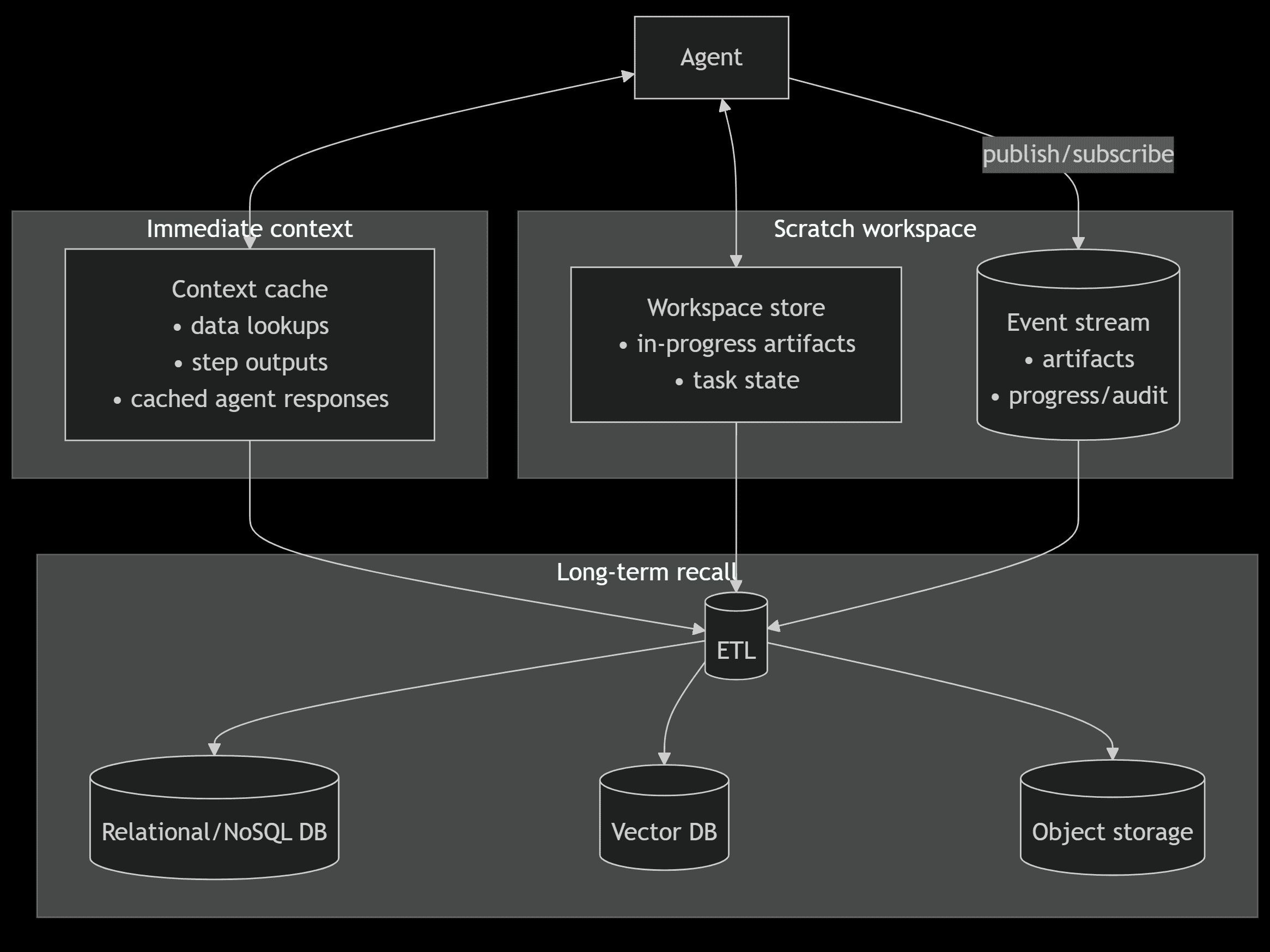
Immediate context
Agents need a working set of facts alongside instructions to reason effectively – the same way a developer needs a stack trace or a support rep needs a chat history. This context is often fetched or computed, then reused across agent calls. Momento Cache is a natural fit here: it centralizes context, makes retries idempotent, and avoids redundant work.
Scratch workspace
Multi-step workflows need somewhere to store and access data actively in-flight. Statuses, workflow steps, artifacts, and an execution plan are all transient data scoped to the life of an individual task. It needs to be accessible to every agent involved and cleaned up when the task completes.
Again, Momento Cache fills the need perfectly. Generated artifacts can be stored in the cache, allowing agents to pass cache keys back and forth, decreasing communication latency and data transfer costs. Cache data types like lists can sequence events for audit purposes and supervisor review. This means you can guarantee traceability of decisions, which is critical for compliance-heavy industries like finance, healthcare, or government.
Long-term recall
Long-term recall is the ability of an agent to learn from what happened in the past and use that knowledge to improve behavior. This turns every execution into a learning loop. Systems get smarter every time they run. It’s a key differentiator between stateless chatbots and a robust, ever-improving enterprise system.
This type of memory requires persisting key information across sessions in a durable store. This information could take the shape of structured records in an RDBMS, semantic embeddings in a vector store, or even artifacts in object storage. Enterprise-grade systems build a knowledge base over time that agents pull from when invoked.
Momento Functions makes building and accessing this long term memory straightforward. By providing a low-latency interface that communicates directly with durable stores like DynamoDB, Redis, or a vector database, functions can parse ephemeral data and persist it as a durable memory with minimal overhead. Coupled with an integrated cache, functions make writes idempotent and reads consistent without extra operational burden.
Code execution
Communication and memory provide a strong working environment for agents, but code execution is what does the work. In production, agents need to be deterministic, fast, and have safe execution paths. Enterprise AI agent development involves more code than many people realize. From pre/post data processing for ETL around model calls to tool execution to even running the entire agent itself, there are plenty of areas that require code to run in order to provide consistent, high-quality, cost-effective agent responses.
ETL around model calls
ETL stands for extract, transform, and load, and is the standard way to combine data from multiple systems into a single resource. This holds exceptionally true for data going into and coming out of LLMs. Enterprises must strictly control the data they provide to an LLM, making tasks like PII sanitization and least-privilege access crucial to data preparation. This is what they demand – deterministic guardrails to keep data safe without slowing down execution.
On the other side of model calls, the post-processing functions, schema validation and data normalization are required tasks if enterprises hope for any semblance of determinism with agent use. Building highly-scalable, memory efficient functions with integrated caching is key to guaranteeing code safety without meaningfully increasing latency in these workloads.
Momento Functions provides HTTP endpoints with integrated authentication to allow for a dependency-free runtime experience. AI agent code can simply make an HTTP call to prepare data for model consumption, and another one to validate and verify correctness after the LLM returns a response.
Below, a minimal Python agent calls a pre-processor function, invokes Claude, then calls a post-processor function to validate/shape the result.
import os, requests, anthropic
client = anthropic.Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
def handler(event):
rid = event["id"]
op = event.get("operation", "summarize")
# 1) Load the source record by ID
record = requests.get(f"{DATA_URL}/{rid}", headers=AUTH).json()
# 2) Pre-process (sanitize, normalize)
cleaned = requests.post(MOMENTO_PRE_URL, json={"record": record}, headers=AUTH).json()["cleaned"]
prompt = f"Operation: {op}\n\nData:\n{cleaned}"
resp = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=400,
messages=[{"role": "user", "content": prompt}]
)
text = resp.content[0].text
# 3) Post-process (validate schema / coerce enums / add provenance)
shaped = requests.post(MOMENTO_POST_URL, json={"raw": text, "operation": op, "id": rid}, headers=AUTH).json()
return {"id": rid, "operation": op, "result": shaped}We keep the code lean by having Functions handle pre/post gates. The agent loads data by an identifier, calls the model, and returns a validated result, resulting in no surprises in production and no drift in schema.
Tool execution
A dynamic and powerful way to execute code in agentic systems is through tools. Tools extend agent capabilities beyond conversation – they allow the LLM to fetch data, manipulate systems, and interact with external APIs. Without tools, an agent is a conversationalist. With tools, an agent is an actor.
- Model Context Protocol (MCP) is an industry standard way for agents to connect to and use tools. Agents authenticate with an MCP server and are provided with a list of available tools and their descriptions. When an LLM determines it needs to use a tool to perform an action, it makes a call to the MCP server and awaits a response.
Many MCP servers act as API wrappers. After login, an LLM invokes a tool and the MCP server proxies the call to an API endpoint. This pattern lends itself exceptionally well to Momento Functions, which provides a dedicated endpoint for each function. The MCP server login authenticates the Momento auth token, and uses it to proxy tool calls to the function. This provides a portable, safe, and discoverable way to use your functions with AI agents.
However, MCP servers are not a requirement to use Momento Functions for tool calls with an AI agent. Many LLMs and agent frameworks allow developers to define tool names, descriptions, and schemas on their own and provide them as context to the LLM. When an LLM determines it needs to use a tool, it returns a response indicating which tool it would like to invoke, and the developer makes that call on behalf of the LLM. This provides a tighter scoped, more controlled environment in enterprise systems, providing security teams with fine-grained control over what agents can touch, reducing the attack surface.
Below is an example of a TypeScript agent using Amazon Bedrock equipped to call tools programmatically rather than automatically through an MCP server.
try {
const command = buildConverseCommand(agentCards, messages, contextId);
const response = await bedrock.send(command);
if (!response.output?.message?.content) {
const messageContent = response.output.message.content;
messages.push({ role: 'assistant', content: messageContent });
const toolUseItem = messageContent.find((item): item is ContentBlock & { toolUse: ToolUseBlock; } => 'toolUse' in item && !!item.toolUse );
if (toolUseItem) {
const { toolUse } = toolUseItem;
const { name: toolName, input: toolInput, toolUseId } = toolUse;
let toolResult: any;
try {
const tool = tools.find(t => t.spec.name === toolName);
toolResult = await tool.handler(toolInput);
} catch (toolError: any) {
console.error(`Tool ${toolName} failed:`, toolError);
toolResult = { error: toolError.message };
}
const block: ToolResultBlock = {
toolUseId,
content: [{ text: JSON.stringify(toolResult) }]
};
messages.push({ role: 'user', content: [{ toolResult: block}]});
}
}In this example, all tool definitions are kept in a tools array which includes the code handler that invokes a Momento Function.
Agent execution
Agents need an execution environment. Depending on the use case, it must be highly scalable, fault tolerant, and low latency. Momento Functions is a perfect environment for running the agent loop.
Functions expose host operations that make agent development both fast and safe. Agents can read/write from Cache and Topics for memory and communication, call models through Amazon Bedrock, and interact with external APIs – all from a managed runtime with strict guardrails.
The result is an enterprise-grade agent runtime. No servers to manage, automatic scaling under unpredictable load, and a consistent development workflow from your IDE to CI/CD.
Pulling it all together
Building enterprise-grade AI agents isn’t about stitching together a few LLM calls. It requires a foundation that handles the messy parts at scale – how agents talk to each other, how they handle memories, how they execute code, and where they run.
Communication makes sure agents can collaborate without silos, using Momento Topics for both event-driven fan-out and orchestrated workflows. It offers visibility into agent plans, tool usage, and ultimately – cost management.
Memory keeps agents grounded in facts and helps prevent hallucinations. Using Momento Cache to store shared context, collaborative scratch workspaces, and artifacts not only keeps your data safe, but it keeps it highly accessible and only available as long as it’s needed.
Code execution turns LLM-based ideas into real-world actions. From tool usage to pre/post data processing, to running the agent loop itself – Momento Functions provides a secure, scalable, and managed runtime perfect for agents.
Momento ties these foundational pillars together in a cohesive, managed platform. Cache, Topics, and Functions provide the backbone for reliable, scalable, and secure agents without the complexity of managing infrastructure. This means faster time-to-market, reduced operational burden, and the confidence that agentic systems will scale predictably without a costly refactor.
That’s what we mean when we say Momento is the DNA of AI agents. It’s not just an analogy, it’s reality. Momento provides the core instructions and systems that make agents communicative, grounded, capable, and resilient. For enterprises, that means lower risk, faster iteration, and infrastructure you can trust from day one. Momento isn’t just enabling today’s agents – it’s the backbone for the next generation of enterprise AI.
Got an AI agent prototype you want to bring to life without hacks, outages, or ballooning costs? Let’s talk!
Share