A tale of gRPC keepalives in the Lambda execution context
Discover how Momento eliminated timeouts for a more reliable caching service.
Pratik Agarwal
by
Pratik Agarwal
,
,
by
Pratik Agarwal
by
Pratik Agarwal
,
,
Caching
AWS Lambda allows developers to run code in response to triggers without the need to manage infrastructure. This shifts a developer’s focus from server management to code execution, offering scalability and cost-efficiency. However, this model also introduces unique behaviors and challenges, particularly when dealing with long-lived connections and keepalive mechanisms. In this blog, we explore the behavior of AWS Lambda's execution context reuse and its implications for keepalive behavior in serverless environments, drawing from real-world observations and practical experiments.
What is an execution context?
From AWS Lambda’s docs, “Lambda invokes your function in an execution environment, which provides a secure and isolated runtime environment. The execution environment manages the resources required to run your function.” These execution environments are also informally referred to as Lambda containers or Lambda instances. To improve performance and reduce the latency associated with cold starts (the time it takes for a container to boot), AWS Lambda may reuse the runtime and any global variables or static initialization across invocations, which we refer to as the execution context.
Experiment: Global state persistence across invocations
Consider the following Node.js Lambda function snippet:
// These are placed outside the Lambda handler to persist across invocations on the same container
const startTime = Date.now();
let numSecondsElapsed = 0;
// This setInterval will start counting from the time this execution context is initialized, and increment numSecondsElapsed every second
setInterval(() => {
numSecondsElapsed += 1;
}, 1000);
// Lambda handler
export const handler = async function(event: any = {}, context: any) {
// Calculate elapsed time in seconds since the start of this execution context
const calculatedNumberMillisecondsElapsed = Date.now() - startTime;
const calculatedNumberSecondsElapsed = Math.floor(calculatedNumberMillisecondsElapsed / 1000);
// Log both elapsed times for comparison
console.log(`Calculated: ${calculatedNumberSecondsElapsed} seconds, Background Task: ${numSecondsElapsed} seconds`);
return {
statusCode: 200,
body: JSON.stringify({
message: `Hello from Lambda! Calculated: ${calculatedNumberSecondsElapsed} seconds, Background Task: ${numSecondsElapsed} seconds`,
}),
};
};
In this setup, setInterval is used to increment numSecondsElapsed every second, starting when the Lambda execution context is first initialized. This setup aims to compare the elapsed time calculated directly from startTime with the elapsed time tracked by the background task.
Can you guess the output of this function if we invoked it 10 times within 60 seconds? Interestingly, the direct calculation, calculatedNumberSecondsElapsed, will show increments approaching 60 seconds as it measures the time since the startTime of the Lambda execution context. However, the background task, numSecondsElapsed, which increments every second the function is actively running, will likely show a value less than or equal to 10. This discrepancy is because the background task is only given compute resources and the opportunity to increment during the actual execution of the Lambda function, not continuously across idle times between invocations.
This experiment illustrates a crucial aspect of serverless function execution: while Lambda can reuse execution contexts, thereby preserving global variables, it does not continuously allocate compute resources to these contexts between invocations. As a result, setInterval does not run unless the Lambda function is actively executing. This behavior underscores the need for careful consideration when porting applications that rely on continuous background processing.
Implications for keepalive in serverless functions
At Momento, our client-server interactions are powered by gRPC, a high-performance, open-source universal RPC framework. To ensure robust communication, we implement keepalive checks in our gRPC channel settings, configured to prompt a ping every 5 seconds and expect an acknowledgment within 1 second. Initially, these settings were standardized across various environments in our pre-built configurations.
However, the serverless landscape, exemplified by AWS Lambda, introduces a distinct set of challenges for managing persistent connections. This complexity was underscored when our Node.js SDK began experiencing inexplicable 'deadline exceeded' errors—a term used in gRPC for certain types of timeouts—in the Lambda environment. To understand the root cause of these timeouts, we enabled detailed gRPC tracing in our Lambda functions such as dns_resolver, resolving_load_balancer, and keepalive. These traces allowed us to view the network communication and lifecycle management of gRPC connections within the serverless environment of AWS Lambda.
In AWS Lambda, each invocation generates a unique request ID, serving as a fingerprint for the specific execution. By examining these IDs alongside the gRPC traces, we could track the lifecycle of each invocation and its associated network activities. This allowed us to correlate network events directly with specific invocations of the Lambda function.
A notable discovery was made when reviewing the keepalive trace logs: we observed that the request IDs flagged for initiating a keepalive ping did not match those logged at the timeout event. For instance:
The discrepancy in request IDs between the ping attempts and the observed timeout errors clearly indicated that keepalive pings initiated during one Lambda invocation were not being processed until the next. This was a crucial insight, as it confirmed that the Lambda execution environment's behavior of freezing and thawing between invocations was affecting the gRPC keepalive mechanism.
During the dormant state between Lambda invocations, any outgoing keepalive pings remained in limbo, unacknowledged until the container was re-engaged. By the time the container was active again, the gRPC keepalive timeout had often already elapsed, leading to the keepalive failures we noted. These timeouts required a gRPC reconnection, which in turn, could lead to subsequent request timeouts when trying to access the service.
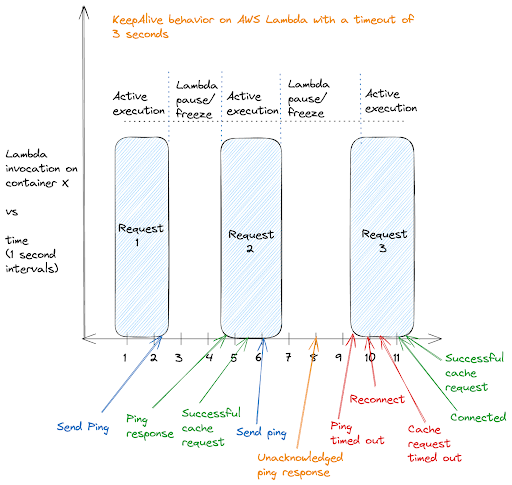
This diagram provides a visual explanation of keepalive behavior within the AWS Lambda execution model. Displayed are three consecutive Lambda invocations on the same container, with periods of active processing and enforced dormancy. The first two requests showcase a smooth cycle of keepalive pings being sent and promptly acknowledged, which corresponds with successful cache requests — indicative of an active and healthy connection.
However, the diagram also brings attention to a hiccup in this cycle: the third request is met with a delayed execution, causing the keepalive ping to fall into a timeout state. Notice that the server sent a ping response between this delay but since the Lambda was inactive, it never acknowledged it. This delay disrupts the continuity of the connection, highlighting a scenario where the inherent latency in Lambda's invocation model can lead to service disruptions, as evidenced by the need for reconnection and a request timeout.
Turning off Keepalive for AWS Lambda
Given the nature of serverless architectures where idle times between invocations are common and unpredictable, the traditional keepalive mechanism proved to be unsuitable. Adjusting the timeout value—whether increasing or decreasing it—would not fix the mismatch between keepalive protocols and the sporadic execution pattern of serverless functions. Consequently, we opted to disable keepalive pings in the default AWS Lambda configuration for Momento.
This change effectively reduced client-side timeout errors, making our caching service's operations fit much better into a serverless paradigm. It's important to note, however, that this solution comes with its own trade-offs. For instance, in scenarios where a connection remains idle for extended periods on a Lambda’s execution context, our system will no longer detect a dropped connection as promptly due to the disabled keepalive. This is a compromise we accepted, prioritizing eliminating frequent timeouts over immediate detection of prolonged inactivity.
Key takeaways and best practices
This experience highlights several important considerations for deploying services in serverless environments:
Serverless-specific configuration: Services must be tailored to the operational dynamics of serverless platforms. Traditional assumptions about network connectivity and long-lived connections may not apply. Hence, it is important for service providers to give different pre-built configurations for different environments in their SDKs, like we do at Momento.
Adapting to platform behaviors: Understanding and adapting to the behavior of serverless platforms, such as the freezing and thawing of execution contexts, is essential for maintaining service reliability and performance.
Monitoring and diagnostics: Implementing detailed logging and tracing is crucial for diagnosing and resolving issues specific to serverless environments. Falling back to network level traces such as those provided by gRPC, or taking TCP dumps and analyzing on Wireshark is often required to diagnose networking related issues.
Conclusion
Serverless offers significant advantages in scalability, cost, and operational efficiency. However, it also requires a reevaluation of how we manage network connections and maintain application state. Our experience at Momento, navigating the challenges of keepalive pings in AWS Lambda, underscores the importance of adaptability and the need for serverless-specific solutions to ensure the seamless operation of services.
Pratik is a software engineer at Momento, specializing in distributed systems. With a rich background spanning roles at prominent teams like AWS DynamoDB and Marketplace, he has honed his expertise across the backend stack. Now at Momento, Pratik is on a mission to elevate the developer experience, rooted in his conviction that it's a cornerstone of serverless computing. Beyond the code, he is passionate about kickboxing and cricket, and loves delving into the strategic nuances of poker, always seeking the upper hand at the table.