カワジャ・シャムス
カワジャ・シャムス
Two workloads, one accelerator
Inference scale is expanding faster than the serving architectures around it. As systems get larger and load gets higher, a very old distributed systems problem shows up in a new place: the work that maximizes throughput is not always the work that protects latency.
Prefill and decode are fundamentally different workloads. Prefill is compute-heavy, with an order of magnitude higher arithmetic intensity than decode. Decode is memory-bandwidth-sensitive and latency-sensitive. Colocating both on the same accelerator forces a compromise: the hardware is tuned for one workload profile but must absorb both.
When prefill and decode share the same serving pipeline, prefill can interfere with decode. It can create head-of-line blocking. It can reduce the amount of useful decode work the system can sustain. Chunked prefill is a good mitigation because it prioritizes decode and slices large prefills into smaller chunks. But chunking does not make prefill free. The system still has to generate the KV cache, schedule the work, and absorb the interference.
Disaggregation and the KV cache boundary
This is the real argument for disaggregated prefill and decode. Separate the compute-heavy prefill phase from the latency-sensitive decode phase. Let prefill nodes do prefill. Let decode nodes do decode. Connect them with a KV cache transfer interface.
Disaggregation creates a natural interface for KV cache. The prefill call produces KV cache. The decode call consumes KV cache. Once that boundary exists, KV cache becomes a system primitive.
KV cache transitions from an inference implementation detail to a first-class distributed systems primitive the moment prefill and decode live on different hardware.
That shift changes the question. KV caching is much less compelling when it is bolted onto a single-node serving stack. It becomes much more compelling when the serving architecture already has a clean handoff between prefill and decode. At that point, the cache is the object moving across the boundary.
Disaggregation is already becoming real
NVIDIA Dynamo describes disaggregated inference as a system where a prefill engine computes the prefill phase and generates KV cache, transfers that KV cache to the decode engine, and then the decode engine performs the decode phase.
AWS is building disaggregated inference into its infrastructure with Trainium for compute-heavy prefill, and the Cerebras partnership reinforces the direction: Cerebras’s wafer-scale SRAM is a natural fit for memory-bound decode, making the prefill/decode split a first-class architectural boundary rather than a research curiosity.
What this means for KV cache
In a colocated serving stack, KV cache is an implementation detail managed by the inference engine. In a disaggregated architecture, it is the object that carries state across the prefill/decode boundary. That boundary creates new requirements:
- Transfer: KV cache must move from prefill nodes to decode nodes. Transfer latency, serialization format, and network bandwidth become first-order concerns.
- Placement: which decode node receives which KV cache? Cache-aware routing becomes a scheduling problem.
- Lifecycle: when does a KV cache entry expire? Who evicts it? In a colocated system the engine manages this. In a disaggregated system it requires coordination.
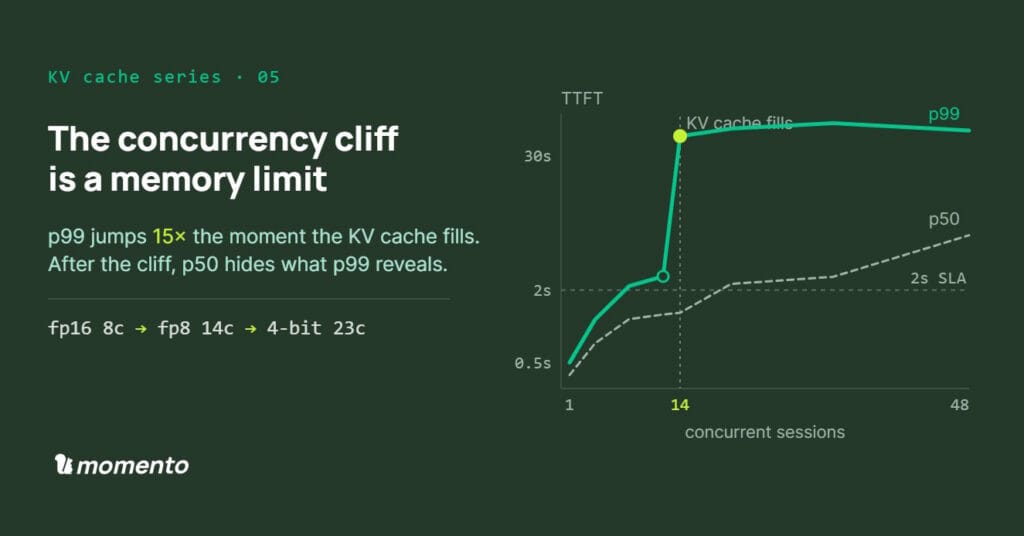
- Storage hierarchy: GPU memory, host memory, NVMe, remote storage. Each tier has different latency and capacity tradeoffs. The concurrency post shows what happens when GPU memory runs out on a single node. Disaggregation makes the storage hierarchy a system design choice rather than a single-node constraint.
These are distributed systems problems. They are the same problems that appear when any system separates storage and compute: what was colocated becomes independently addressable, connected by a transfer layer. The techniques for solving them (caching, replication, placement, eviction) are well-understood in distributed systems. What is new is applying them to the KV cache object in the context of inference serving.
The economics of the split
Disaggregation also changes the hardware economics. Prefill is compute-bound and benefits from high-FLOPS accelerators. Decode is memory-bandwidth-bound and benefits from large, fast memory. Colocating both on the same GPU means neither workload gets its ideal hardware profile. Separating them allows each phase to run on hardware optimized for its specific bottleneck.
This is where the KV cache economics from Post 01 connect. If the KV cache object is shrinking (MLA, CSA, DeltaNet, TurboQuant), the transfer cost of moving it across the boundary shrinks proportionally. Smaller KV caches are faster to transfer, cheaper to store, and fit more entries in the same memory budget. The techniques that reduce KV cache size make disaggregation more practical, and disaggregation makes KV cache management more important. They reinforce each other.
From implementation detail to system design
The rest of this series examines KV cache from the single-node perspective: how prefix caching works (Post 02), how benchmark methodology affects results (Post 03), and where the concurrency knee shows up on a single GPU (Post 04). Those posts are about making the most of one node.
Disaggregation is the next step. Once prefill and decode live on separate hardware, KV cache stops being a per-engine optimization and becomes a system-level resource that needs to be transferred, placed, cached, and evicted across a distributed infrastructure. The single-node lessons still apply. The system-level problems are additive.